Python 은 Guido van Rossum이 개발한 동적 의미 체계를 갖춘 해석된 객체 지향 고급 프로그래밍 언어로 1991년에 출시되었습니다. 쉽고 재미있도록 디자인된 “Python”이라는 이름은 영국 코미디 그룹인 Monty Python 에서 따온 것입니다. Python 은 서버 측 웹 개발, 소프트웨어 개발, 수학 및 시스템 스크립팅에 사용되며, 빠른 애플리케이션 개발 및 높은 수준의 내장 데이터 구조로 인해 기존 구성 요소를 연결하는 스크립팅 또는 접착 언어로 널리 사용됩니다. Python 을 사용하면 구문을 쉽게 배우고 가독성을 강조하여 프로그램을 유지하고 관리하는 데 매우 효율적입니다. 또한 Python 의 모듈 및 패키지 지원은 모듈식 프로그램과 코드 재사용을 용이하게 합니다. Python 은 오픈 소스 커뮤니티 언어이므로 수많은 독립 프로그래머가 Python 용 라이브러리와 기능을 지속적으로 구축하고 있습니다.
Python 사용 사례는
1. 서버에서 웹 애플리케이션 생성
2. 소프트웨어와 연동하여 사용할 수 있는 워크플로우 구축
3. 데이터베이스 시스템에 연결
4. 파일 읽기 및 수정
5. 복잡한 수학 수행
6. 빅데이터 처리
7. 빠른 프로토타이핑
8. 생산 준비가 된 소프트웨어 개발등으로 매우 다양합니다.
이번 포스팅에서는
‘Hotel’ 데이터를 활용하여 실제로 기초적인 데이터 분석을 수행해 보겠습니다.
라이브러리 및 데이터 프레임 가져오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import re
sns.set()
pd.set_option('display.max_columns', 600)그런 다음 파일을 호출합니다. 저장한 형식 파일은 github에 있는 csv이므로 아래 링크를 사용하시면 됩니다.
# github에 있는 파일 호출
hotelsData = pd.read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-02-11/hotels.csv')
# 상위 5개 데이터 확인하기
hotelsData.head()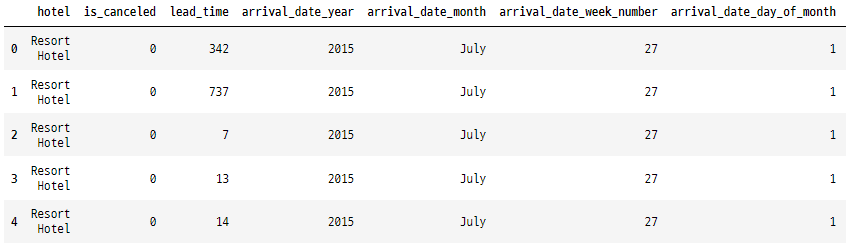
인덱스 추가 및 열 이름 바꾸기
# 인덱스 추가 후 인덱스 컬럼명 변경(index -> id)하기
hotelsData = hotelsData.reset_index().rename(columns={'index':'id'})
hotelsData.head()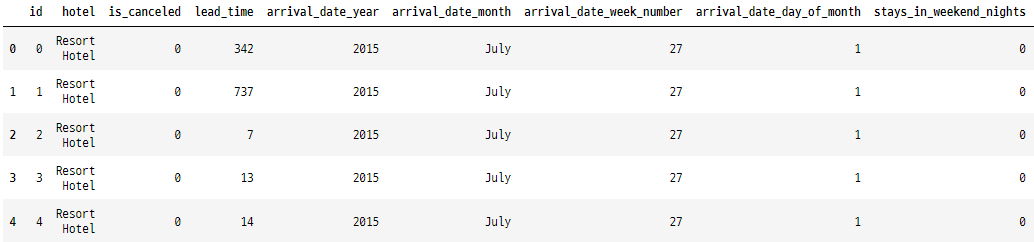
컬럼명 확인
hotelsData.columns
---------------------
Index(['id', 'hotel', 'is_canceled', 'lead_time', 'arrival_date_year',
'arrival_date_month', 'arrival_date_week_number',
'arrival_date_day_of_month', 'stays_in_weekend_nights',
'stays_in_week_nights', 'adults', 'children', 'babies', 'meal',
'country', 'market_segment', 'distribution_channel',
'is_repeated_guest', 'previous_cancellations',
'previous_bookings_not_canceled', 'reserved_room_type',
'assigned_room_type', 'booking_changes', 'deposit_type', 'agent',
'company', 'days_in_waiting_list', 'customer_type', 'adr',
'required_car_parking_spaces', 'total_of_special_requests',
'reservation_status', 'reservation_status_date'],
dtype='object')데이터 셋 개요 확인
hotelsData.info()
-----------------------------------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 119390 entries, 0 to 119389
Data columns (total 33 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 119390 non-null int64
1 hotel 119390 non-null object
2 is_canceled 119390 non-null int64
3 lead_time 119390 non-null int64
4 arrival_date_year 119390 non-null int64
5 arrival_date_month 119390 non-null object
6 arrival_date_week_number 119390 non-null int64
7 arrival_date_day_of_month 119390 non-null int64
8 stays_in_weekend_nights 119390 non-null int64
9 stays_in_week_nights 119390 non-null int64
10 adults 119390 non-null int64
11 children 119386 non-null float64
12 babies 119390 non-null int64
13 meal 119390 non-null object
14 country 118902 non-null object
15 market_segment 119390 non-null object
16 distribution_channel 119390 non-null object
17 is_repeated_guest 119390 non-null int64
18 previous_cancellations 119390 non-null int64
19 previous_bookings_not_canceled 119390 non-null int64
20 reserved_room_type 119390 non-null object
21 assigned_room_type 119390 non-null object
22 booking_changes 119390 non-null int64
23 deposit_type 119390 non-null object
24 agent 103050 non-null float64
25 company 6797 non-null float64
26 days_in_waiting_list 119390 non-null int64
27 customer_type 119390 non-null object
28 adr 119390 non-null float64
29 required_car_parking_spaces 119390 non-null int64
30 total_of_special_requests 119390 non-null int64
31 reservation_status 119390 non-null object
32 reservation_status_date 119390 non-null object
dtypes: float64(4), int64(17), object(12)
memory usage: 30.1+ MB데이터 유형 확인
hotelsData.dtypes
--------------------------------------------
id int64
hotel object
is_canceled int64
lead_time int64
arrival_date_year int64
arrival_date_month object
arrival_date_week_number int64
arrival_date_day_of_month int64
stays_in_weekend_nights int64
stays_in_week_nights int64
adults int64
children float64
babies int64
meal object
country object
market_segment object
distribution_channel object
is_repeated_guest int64
previous_cancellations int64
previous_bookings_not_canceled int64
reserved_room_type object
assigned_room_type object
booking_changes int64
deposit_type object
agent float64
company float64
days_in_waiting_list int64
customer_type object
adr float64
required_car_parking_spaces int64
total_of_special_requests int64
reservation_status object
reservation_status_date object
dtype: objectNull 값 확인
hotelsData.isnull().sum(axis=0)
---------------------------------------------------------------
hotel 0
is_canceled 0
lead_time 0
arrival_date_year 0
arrival_date_month 0
arrival_date_week_number 0
arrival_date_day_of_month 0
stays_in_weekend_nights 0
stays_in_week_nights 0
adults 0
children 4
babies 0
meal 0
country 488
market_segment 0
distribution_channel 0
is_repeated_guest 0
previous_cancellations 0
previous_bookings_not_canceled 0
reserved_room_type 0
assigned_room_type 0
booking_changes 0
deposit_type 0
agent 16340
company 112593
days_in_waiting_list 0
customer_type 0
adr 0
required_car_parking_spaces 0
total_of_special_requests 0
reservation_status 0
reservation_status_date 0
dtype: int64</pre>고유 값 개수 확인하기
hotelsData.nunique(axis=0)
--------------------------------------------------
id 119390
hotel 2
is_canceled 2
lead_time 479
arrival_date_year 3
arrival_date_month 12
arrival_date_week_number 53
arrival_date_day_of_month 31
stays_in_weekend_nights 17
stays_in_week_nights 35
adults 14
children 5
babies 5
meal 5
country 177
market_segment 8
distribution_channel 5
is_repeated_guest 2
previous_cancellations 15
previous_bookings_not_canceled 73
reserved_room_type 10
assigned_room_type 12
booking_changes 21
deposit_type 3
agent 333
company 352
days_in_waiting_list 128
customer_type 4
adr 8879
required_car_parking_spaces 5
total_of_special_requests 6
reservation_status 3
reservation_status_date 926
dtype: int64</pre>Null 값의 백분율 확인
round(100*(hotelsData.isnull().sum()/len(hotelsData.index)),2)
-------------------------------------------------------------------
id 0.00
hotel 0.00
is_canceled 0.00
lead_time 0.00
arrival_date_year 0.00
arrival_date_month 0.00
arrival_date_week_number 0.00
arrival_date_day_of_month 0.00
stays_in_weekend_nights 0.00
stays_in_week_nights 0.00
adults 0.00
children 0.00
babies 0.00
meal 0.00
country 0.41
market_segment 0.00
distribution_channel 0.00
is_repeated_guest 0.00
previous_cancellations 0.00
previous_bookings_not_canceled 0.00
reserved_room_type 0.00
assigned_room_type 0.00
booking_changes 0.00
deposit_type 0.00
agent 13.69
company 94.31
days_in_waiting_list 0.00
customer_type 0.00
adr 0.00
required_car_parking_spaces 0.00
total_of_special_requests 0.00
reservation_status 0.00
reservation_status_date 0.00
dtype: float64</pre>
데이터 분석 사례 1
아래 4개를 만족하는 함수 생성하기
1. 데이터 유형을 확인하기 위한 데이터 프레임 형태의 인수 1개,
2. null 값의 수를 확인하기
3. 퍼센트 null 값을 확인하기
4. 데이터 프레임의 각 칼럼에 대한 고유 값의 수
1번에 대한 해결방안
‘company’ 컬럼에 대한 데이터 유형을 알고 싶다면?
hotelsData[‘company’].dtype
dtype('float64')
2번에 대한 해결방안
‘company’ 컬럼에서 얼마나 많은 null 값을 가지는 지 확인하고 싶다면?
hotelsData[‘company’].isna().sum()
112593
3번에 대한 해결방안
‘company’ 컬럼에서 백분율 null 값을 구하고 싶다면?
round(100*(hotelsData[‘company’].isna().mean()),2)
94.31
4번에 대한 해결방안
def check_values(df):
oodata = []
oofor col in df.columns:
oooodata.append([col, # 컬럼명
oooooooooooooooodf[col].dtype, #컬럼의 데이터 유형
oooooooooooooooodf[col].isna().sum(), #컬럼의 null 값
ooooooooooooooooround(100*(df[col].isna().mean()),2), # 컬럼의 null 값 비율
oooooooooooooooodf[col].nunique()]) # 칼럼의 고유 값 개수
ooreturn pd.DataFrame(columns=[‘dataFeatures’, ‘dataType’, ‘null’, ‘nullPct’, ‘unique’],data = data)
check_values(hotelsData)
| dataFeatures | dataType | null | nullPct | unique | |
|---|---|---|---|---|---|
| 0 | id | int64 | 0 | 0.00 | 119390 |
| 1 | hotel | object | 0 | 0.00 | 2 |
| 2 | is_canceled | int64 | 0 | 0.00 | 2 |
| 3 | lead_time | int64 | 0 | 0.00 | 479 |
| 4 | arrival_date_year | int64 | 0 | 0.00 | 3 |
| 5 | arrival_date_month | object | 0 | 0.00 | 12 |
| 6 | arrival_date_week_number | int64 | 0 | 0.00 | 53 |
| 7 | arrival_date_day_of_month | int64 | 0 | 0.00 | 31 |
| 8 | stays_in_weekend_nights | int64 | 0 | 0.00 | 17 |
| 9 | stays_in_week_nights | int64 | 0 | 0.00 | 35 |
| 10 | adults | int64 | 0 | 0.00 | 14 |
| 11 | children | float64 | 4 | 0.00 | 5 |
| 12 | babies | int64 | 0 | 0.00 | 5 |
| 13 | meal | object | 0 | 0.00 | 5 |
| 14 | country | object | 488 | 0.41 | 177 |
| 15 | market_segment | object | 0 | 0.00 | 8 |
| 16 | distribution_channel | object | 0 | 0.00 | 5 |
| 17 | is_repeated_guest | int64 | 0 | 0.00 | 2 |
| 18 | previous_cancellations | int64 | 0 | 0.00 | 15 |
| 19 | previous_bookings_not_canceled | int64 | 0 | 0.00 | 73 |
| 20 | reserved_room_type | object | 0 | 0.00 | 10 |
| 21 | assigned_room_type | object | 0 | 0.00 | 12 |
| 22 | booking_changes | int64 | 0 | 0.00 | 21 |
| 23 | deposit_type | object | 0 | 0.00 | 3 |
| 24 | agent | float64 | 16340 | 13.69 | 333 |
| 25 | company | float64 | 112593 | 94.31 | 352 |
| 26 | days_in_waiting_list | int64 | 0 | 0.00 | 128 |
| 27 | customer_type | object | 0 | 0.00 | 4 |
| 28 | adr | float64 | 0 | 0.00 | 8879 |
| 29 | required_car_parking_spaces | int64 | 0 | 0.00 | 5 |
| 30 | total_of_special_requests | int64 | 0 | 0.00 | 6 |
| 31 | reservation_status | object | 0 | 0.00 | 3 |
| 32 | reservation_status_date | object | 0 | 0.00 | 926 |
데이터 분석 사례 2
해결방안
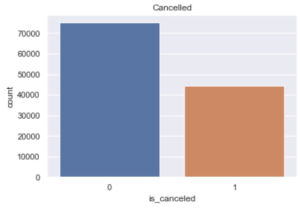
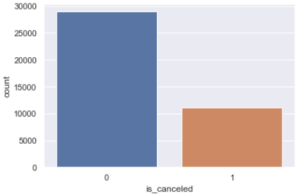
hotelsData[‘is_canceled’].value_counts()
0 75166 1 44224 Name: is_canceled, dtype: int64
hotelsData[‘is_canceled’].value_counts(normalize=True)
0 0.629584 1 0.370416 Name: is_canceled, dtype: float64
plt.title(‘Cancelled’)
plt.show()
데이터 분석 사례 3
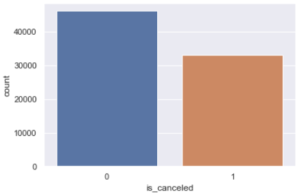
1. “City Hotel”의 경우 예약 취소 비율은 얼마나 됩니까?
2. “리조트 호텔”의 경우 예약 취소 비율은 얼마나 됩니까?
1번에 대한 해결방안
city[‘is_canceled’].value_counts(normalize=True)
0 0.58273 1 0.41727 Name: is_canceled, dtype: float64
plt.show()
2번에 대한 해결방안
resort = hotelsData[hotelsData[‘hotel’] == ‘Resort Hotel’]
resort[‘is_canceled’].value_counts(normalize=True)
0 0.722366 1 0.277634 Name: is_canceled, dtype: float64
plt.show()
데이터 분석 사례 4
dfCheckout.shape
(75166, 33)
데이터 분석 사례 5
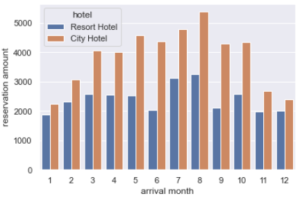
1. 각 호텔 유형에 대한 도착 월별 예약 수를 표시합니다.
2. 호텔 종류별로 예약이 가장 많은 달은 언제일까요? 두 유형의 호텔에서 추세가 동일한지 결론을 내리시겠습니까?
3. 월 이름에 숫자를 매핑하여 다시 산출합니다.
1번과 2번에 대한 해결방안
dfCheckout.groupby([‘hotel’,’arrival_date_month’])[‘id’].nunique()
hotel arrival_date_month
City Hotel April 4015
August 5381
December 2392
February 3064
January 2254
July 4782
June 4366
March 4072
May 4579
November 2696
October 4337
September 4290
Resort Hotel April 2550
August 3257
December 2017
February 2308
January 1868
July 3137
June 2038
March 2573
May 2535
November 1976
October 2577
September 2102
Name: id, dtype: int64
3번에 대한 해결방안
문자열에서 숫자로 월 매핑:
import calendar
monthDict = {month: index for index, month in enumerate(calendar.month_name) if month}
monthDict
{'January': 1,
'February': 2,
'March': 3,
'April': 4,
'May': 5,
'June': 6,
'July': 7,
'August': 8,
'September': 9,
'October': 10,
'November': 11,
'December': 12}
dfCheckout.groupby([‘hotel’,’arrival_date_month_num’]).size()
hotel arrival_date_month_num
City Hotel 1 2254
2 3064
3 4072
4 4015
5 4579
6 4366
7 4782
8 5381
9 4290
10 4337
11 2696
12 2392
Resort Hotel 1 1868
2 2308
3 2573
4 2550
5 2535
6 2038
7 3137
8 3257
9 2102
10 2577
11 1976
12 2017
dtype: int64
그런 다음 그래프로 표현합니다.
plt.xlabel(‘arrival month’)
plt.ylabel(‘reservation amount’)
plt.show()
데이터 분석 사례 6
1. 도착 연도, 월 및 날짜에 대한 완전한 정보를 포함하는 arrival_date라는 새 칼럼을 생성합니다.
2. 컬럼을 날짜/시간 유형으로 변경합니다(연도, 월, 날짜를 yyyy-mm-dd 형식으로 연결).
1번에 대한 해결방안
dfCheckout.arrival_date_month_num.astype(‘str’).str.pad(2,fillchar=’0′,side=’left’)
0 07
1 07
2 07
3 07
4 07
..
119385 08
119386 08
119387 08
119388 08
119389 08
Name: arrival_date_month_num, Length: 75166, dtype: object
df_checkout.arrival_date_month_num.astype(‘str’).str.pad(2,fillchar=‘0’) + ‘-‘ +\
df_checkout.arrival_date_day_of_month.astype(‘str’).str.pad(2,fillchar=‘0’)
0 2015-07-01
1 2015-07-01
2 2015-07-01
3 2015-07-01
4 2015-07-01
...
119385 2017-08-30
119386 2017-08-31
119387 2017-08-31
119388 2017-08-31
119389 2017-08-29
Length: 75166, dtype: object
dfCheckout[‘arrival_date’] = dfCheckout[‘arrival_date_year’].astype(‘str’) + ‘-‘ +\
dfCheckout.arrival_date_month_num.astype(‘str’).str.pad(2,fillchar=’0′) + ‘-‘ +\
dfCheckout.arrival_date_day_of_month.astype(‘str’).str.pad(2,fillchar=’0′)
dfCheckout[‘arrival_date’]
0 2015-07-01
1 2015-07-01
2 2015-07-01
3 2015-07-01
4 2015-07-01
...
119385 2017-08-30
119386 2017-08-31
119387 2017-08-31
119388 2017-08-31
119389 2017-08-29
Name: arrival_date, Length: 75166, dtype: object
2번에 대한 해결방안
데이터 유형을 날짜 시간으로 변경
dfCheckout[‘arrival_date’] = pd.to_datetime(dfCheckout[‘arrival_date’])
dfCheckout[‘arrival_date’]
0 2015-07-01
1 2015-07-01
2 2015-07-01
3 2015-07-01
4 2015-07-01
...
119385 2017-08-30
119386 2017-08-31
119387 2017-08-31
119388 2017-08-31
119389 2017-08-29
Name: arrival_date, Length: 75166, dtype: datetime64[ns]
dtype('<M8[ns]')
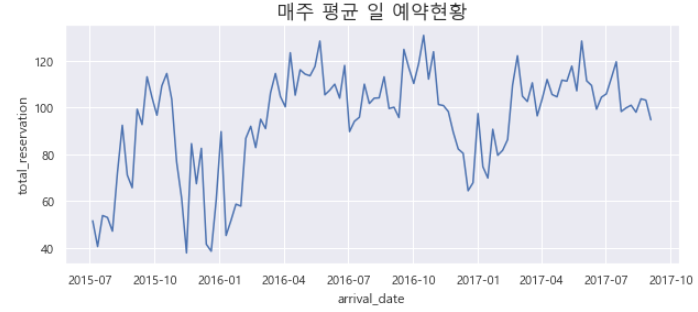
데이터 분석 사례 7
1. 총 일일 예약(df_reservation_per_day) 현황
2. 매주 평균 일일 예약(df_avg_reservations_day) 현황
1번에 대한 해결방안
dfReservationPerDay.head(15)
| arrival_date | total_reservation | |
|---|---|---|
| 0 | 2015-07-01 | 103 |
| 1 | 2015-07-02 | 36 |
| 2 | 2015-07-03 | 37 |
| 3 | 2015-07-04 | 45 |
| 4 | 2015-07-05 | 37 |
| 5 | 2015-07-06 | 41 |
| 6 | 2015-07-07 | 29 |
| 7 | 2015-07-08 | 45 |
| 8 | 2015-07-09 | 29 |
| 9 | 2015-07-10 | 42 |
| 10 | 2015-07-11 | 61 |
| 11 | 2015-07-12 | 37 |
| 12 | 2015-07-13 | 39 |
| 13 | 2015-07-14 | 24 |
| 14 | 2015-07-15 | 54 |
2번에 대한 해결방안
oooooooooooooooooooooo.reset_index().rename(columns={0:’total_reservation’})
oooooooooooooooooooooo.resample(‘W’,on=’arrival_date’)[‘total_reservation’]
oooooooooooooooooooooo.mean()
oooooooooooooooooooooo.reset_index())
dfAvgReservationsDay
| arrival_date | total_reservation | |
|---|---|---|
| 0 | 2015-07-05 | 51.600000 |
| 1 | 2015-07-12 | 40.571429 |
| 2 | 2015-07-19 | 53.857143 |
| 3 | 2015-07-26 | 53.000000 |
| 4 | 2015-08-02 | 47.142857 |
| … | … | … |
| 109 | 2017-08-06 | 101.000000 |
| 110 | 2017-08-13 | 98.000000 |
| 111 | 2017-08-20 | 103.714286 |
| 112 | 2017-08-27 | 103.142857 |
| 113 | 2017-09-03 | 94.750000 |
sns.lineplot(data = dfAvgReservationsDay, x=’arrival_date’, y=’total_reservation’)
plt.title(‘매주 평균 일 예약현황’, fontsize=’x-large’)
plt.show()
데이터 분석 사례 8
2. 각 호텔 유형에서 ADR이 가장 큰 고객 유형은 무엇입니까요?
1번에 대한 해결방안
dfCheckout.groupby([‘hotel’,’customer_type’])[‘adr’].mean()
hotel customer_type
City Hotel Contract 108.929255
Group 87.398712
Transient 110.423280
Transient-Party 93.705007
Resort Hotel Contract 78.581674
Group 77.306575
Transient 96.001928
Transient-Party 77.204010
Name: adr, dtype: float64
2번에 대한 해결방안
sns.boxplot(data=dfCheckout, x=’adr’, y=’hotel’,hue=’customer_type’)
plt.show()
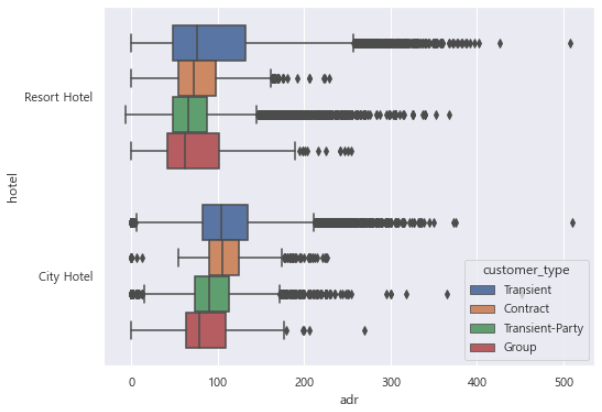
Transient는 각 호텔 유형에서 ADR이 가장 큰 고객 유형입니다.
데이터 분석 사례 9
국가 이름과 국가 코드에 대한 정보가 포함된 dfCountry 데이터 프레임을 사용하여 예약 수가 가장 많은 10개 국가를 표시해 봅니다.
해결방안
#새로운 데이터 셋 읽기
dfCountry = pd.read_csv(‘https://gist.githubusercontent.com/tadast/8827699/raw/f5cac3d42d16b78348610fc4ec301e9234f82821/countries_codes_and_coordinates.csv’)
dfCountry.head()
| Country | Alpha-2 code | Alpha-3 code | Numeric code | Latitude (average) | Longitude (average) | |
|---|---|---|---|---|---|---|
| 0 | Afghanistan | “AF” | “AFG” | “4” | “33” | “65” |
| 1 | Albania | “AL” | “ALB” | “8” | “41” | “20” |
| 2 | Algeria | “DZ” | “DZA” | “12” | “28” | “3” |
| 3 | American Samoa | “AS” | “ASM” | “16” | “-14.3333” | “-170” |
| 4 | Andorra | “AD” | “AND” | “20” | “42.5” | “1.6” |
dfCountry[‘code’] = dfCountry[‘Alpha-3 code’].str.replace(‘”‘,”).str.strip()
dfCountry[‘Alpha-3 code’] = dfCountry[‘Alpha-3 code’].str.replace(‘”‘,”).str.strip()
dfCountry
| Country | Alpha-2 code | Alpha-3 code | Numeric code | Latitude (average) | Longitude (average) | code | |
|---|---|---|---|---|---|---|---|
| 0 | Afghanistan | “AF” | AFG | “4” | “33” | “65” | AFG |
| 1 | Albania | “AL” | ALB | “8” | “41” | “20” | ALB |
| 2 | Algeria | “DZ” | DZA | “12” | “28” | “3” | DZA |
| 3 | American Samoa | “AS” | ASM | “16” | “-14.3333” | “-170” | ASM |
| 4 | Andorra | “AD” | AND | “20” | “42.5” | “1.6” | AND |
| … | … | … | … | … | … | … | … |
| 251 | Wallis and Futuna | “WF” | WLF | “876” | “-13.3” | “-176.2” | WLF |
| 252 | Western Sahara | “EH” | ESH | “732” | “24.5” | “-13” | ESH |
| 253 | Yemen | “YE” | YEM | “887” | “15” | “48” | YEM |
| 254 | Zambia | “ZM” | ZMB | “894” | “-15” | “30” | ZMB |
| 255 | Zimbabwe | “ZW” | ZWE | “716” | “-20” | “30” | ZWE |
oooooooooooooooooodfCountry[[‘Country’,’code’]],
ooooooooooooooooooleft_on=’country’,
ooooooooooooooooooright_on=’code’,
ooooooooooooooooooindicator=True,
oooooooooooooooooohow=’left’)
dfMerged
dfMerged._merge.value_counts()
both 74269 left_only 1448 right_only 0 Name: _merge, dtype: int64
dfMerged[dfMerged._merge==’left_only’][‘country’].unique()
array([nan, 'CN', 'TMP'], dtype=object)
plt.show()
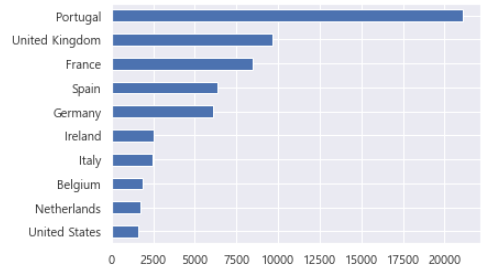
데이터 분석 사례 10
1. 예약당 몇 명이 숙박하나요?
2. 데이터 세트를 기준으로 최대 손님 수는 몇 명입니까? 또한 손님 수가 가장 많은 예약 데이터 행을 표시합니다.
1번에 대한 해결방안
dfCheckout[‘total_guest’] = dfCheckout.adults + dfCheckout.children + dfCheckout.babies
dfCheckout.total_guest.describe()
count 75166.000000 mean 1.942461 std 0.669966 min 0.000000 25% 2.000000 50% 2.000000 75% 2.000000 max 12.000000 Name: total_guest, dtype: float64
2번에 대한 해결방안
dfCheckout.total_guest.max()
12.0
dfCheckout[dfCheckout[‘total_guest’]==dfCheckout.total_guest.max()].T
| 46619 | |
|---|---|
| id | 46619 |
| hotel | City Hotel |
| is_canceled | 0 |
| lead_time | 37 |
| arrival_date_year | 2016 |
| arrival_date_month | January |
| arrival_date_week_number | 3 |
| arrival_date_day_of_month | 12 |
| stays_in_weekend_nights | 0 |
| stays_in_week_nights | 2 |
| adults | 2 |
| children | 0.0 |
| babies | 10 |
| meal | BB |
| country | PRT |
| market_segment | Online TA |
| distribution_channel | TA/TO |
| is_repeated_guest | 0 |
| previous_cancellations | 0 |
| previous_bookings_not_canceled | 0 |
| reserved_room_type | D |
| assigned_room_type | D |
| booking_changes | 1 |
| deposit_type | No Deposit |
| agent | 9.0 |
| company | NaN |
| days_in_waiting_list | 0 |
| customer_type | Transient |
| adr | 84.45 |
| required_car_parking_spaces | 0 |
| total_of_special_requests | 1 |
| reservation_status | Check-Out |
| reservation_status_date | 2016-01-14 |
| arrival_date_month_num | 1 |
| arrival_date | 2016-01-12 00:00:00 |
| total_guest | 12.0 |