빅데이터 처리를 위한 PyArrow 라이브러리 포스팅에서 Pyarrow 라이브러리에 대해서 알아 보았습니다. 빅데이터 처리 시 Pyarrow와 연관이 있는 파일 형식 중 Parquet 파일이 있습니다. Parquet파일은 빅데이터를 저장하고 처리하기 위한 열 지향 데이터 저장 형식 중 하나 입니다. Parquet 파일 형식은 빅데이터 분석 및 처리 작업에 최적화되어 있어, 여러 프로그래밍 언어 및 프레임워크에서 지원됩니다. 이번 포스팅에서는 여러 빅데이터 처리 시 매우 유용한 Parquet(파케이) 파일 형식에 대해서 알아 보겠습니다.
Parquet 파일의 주요 특징
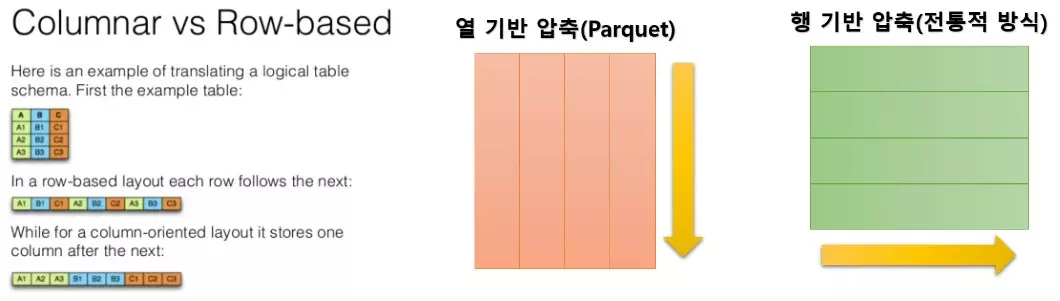
- 열 지향 구조
- Parquet 파일은 열 기반으로 데이터를 저장하는 방식을 채택하고 있습니다.
이는 같은 열의 데이터를 연속적으로 저장하여 읽고 쓰기를 효율적으로 만들어줍니다.
대용량 데이터 셋에서 특정 열에 대한 연산이 필요한 경우 성능을 향상시킬 수 있습니다.
- Parquet 파일은 열 기반으로 데이터를 저장하는 방식을 채택하고 있습니다.
- 압축 기능
- Parquet 파일은 압축을 사용하여 데이터를 저장합니다.
이는 디스크 공간을 절약하고 데이터를 효율적으로 전송할 수 있도록 도와줍니다.
다양한 압축 알고리즘을 선택할 수 있어 사용자가 성능과 압축률 간의 적절한 균형을 찾을 수 있습니다.
- Parquet 파일은 압축을 사용하여 데이터를 저장합니다.
- 다양한 데이터 타입 지원
- Parquet은 다양한 데이터 타입을 지원하며, 복합 데이터 타입도 처리할 수 있습니다.
이는 복잡한 데이터 구조를 효과적으로 다루고 저장하는 데 유용합니다.
- Parquet은 다양한 데이터 타입을 지원하며, 복합 데이터 타입도 처리할 수 있습니다.
- 스키마 지정
- Parquet 파일은 스키마를 가지고 있어 데이터의 구조를 정의합니다. 이는 데이터의 의미를 명확히 하고 데이터의 일관성을 유지하는 데 도움이 됩니다.
- 분할 가능한 파일 포맷
- Parquet 파일은 여러 개의 블록으로 나뉘어져 있습니다.
이는 대용량 파일을 여러 부분으로 나누어 분산 저장 및 처리가 가능하도록 해줍니다.
이는 병렬 처리를 통해 대규모 데이터셋에 대한 효율적인 처리를 지원합니다.
- Parquet 파일은 여러 개의 블록으로 나뉘어져 있습니다.
Parquet 파일은 Apache Arrow 프로젝트와도 관련이 깊습니다. Arrow의 형식을 통해 데이터를 효과적으로 변환할 수 있습니다. 다양한 데이터 처리 및 분석 도구에서 Parquet 형식을 지원하고 있어 데이터의 이동성과 상호 운용성을 높이는 데 기여하고 있습니다. 또한, Python의 Pyarrow 라이브러리를 활용해서 Parquet 형식을 매우 유연하게 처리할 수 있습니다.
python에서 parquet 파일을 다루는 예제 코드
Parquet 파일을 다루기 위해서는 PyArrow 또는 Pandas와 같은 라이브러리를 사용할 수 있습니다. 여기에서는 PyArrow를 사용하여 Parquet 파일을 읽고 쓰는 간단한 예제 코드를 작성해 보겠습니다. 여기서는 공공데이터포털의 금융회사 기본정보 불러오기 포스팅에서 생성한 “금융회사기본정보조회서비스.csv” 데이터를 활용하겠습니다.
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# 금융회사기본정보조회서비스.csv 파일 불러오기
df = pd.read_csv("D:/금융회사기본정보조회서비스.csv")
# Pandas DataFrame을 PyArrow Table로 변환
table = pa.Table.from_pandas(df)
# Parquet 파일로 저장
pq.write_table(table, 'example.parquet')
# Parquet 파일 읽기
readTable = pq.read_table('example.parquet')
# PyArrow Table을 Pandas DataFrame으로 변환
dfFromParquet = readTable.to_pandas()
# 결과 확인
print("원본 DataFrame:")
df
print("\nParquet 파일에서 읽은 DataFrame:")
dfFromParquet
이 예제에서는 Pandas DataFrame을 PyArrow Table로 변환합니다. 이를 Parquet 파일로 저장한 후 다시 읽어와 PyArrow Table을 Pandas DataFrame으로 변환하는 과정을 보여줍니다.
중요한 것은, PyArrow는 Arrow 형식으로 데이터를 저장하므로 데이터를 읽고 쓸 때 Arrow 형식을 통해 변환 작업이 이루어집니다. PyArrow는 대용량 데이터에 대한 효율적인 처리를 지원하기 때문에 대규모 데이터 셋에 유용합니다.
엄청나게 큰 용량의 데이터도 위의 방식으로 처리 가능?
위의 예제에서는 전체 데이터의 개수가 1,066건 밖에 되지 않습니다. 만약, 데이터의 개수가 1,000,000,000 건으로 매우 크다면, 위의 방식으로 처리할 수 있을까? 불가능합니다. csv 파일을 DataFrame으로 변환하는 과정에서 메모리 부족으로 에러가 발생할 것입니다. 다음 포스팅에서는 메모리 이슈를 해결하고, 엄청나게 큰 용량의 데이터를 parquet 파일로 저장하고, 처리하는 방법에 대해서 알아 보겠습니다.