데이터 클린징 작업을 수행한 적이 있습니까?
데이터 클린징 작업이 모든 분석 프로젝트에서 가장 시간이 많이 걸리는 부분이라는 것을 알고 있을 것입니다.
결측치, 중복 및 데이터 유형 불일치를 수동으로 처리하는 것은 짜증스럽고 귀찮은 작업일 수 있습니다.
파이썬에서 데이터 정리 워크플로우를 자동화 한다면, 이 모든 문제를 해결할 수 있습니다.
많은 시간 동안 데이터를 수동으로 정리하는 대신 이제는 재사용 가능한 함수와 파이프라인을 생성하여 힘든 작업을 대신 처리합니다.
이번 포스팅에서는 데이터 클린징 작업을 자동화하고 분석 프로세스를 간소화하는 데 도움이 되는 주요 파이썬 기술에 대해 알아보겠습니다.
초보자이든 데이터 전문가이든 이러한 기술은 데이터를 분석에 적합한 깨끗하고 구조화된 데이터로 변환(데이터 전처리)하는 데 도움이 될 것으로 확신합니다.
데이터 클린징 자동화 이유
파이썬 코드로 들어가기 전에 데이터 클린징 자동화가 왜 그렇게 중요한지 알아보겠습니다.
- 일관성: 데이터를 수동으로 정리할 때 오류나 불일치가 발생할 가능성이 더 큽니다.
프로세스를 자동화하면 전체 데이터 세트에서 균일성이 보장됩니다. - 효율성: 자동화는 중복 제거나 누락된 값 처리와 같은 반복적인 작업의 속도를 높입니다.
이를 통해 데이터 클린징보다는 실제 분석에 집중할 수 있는 시간이 더 많아집니다. - 확장성: 데이터 세트가 커질수록 수동 정리는 비실용적이 됩니다.
자동화된 워크플로는 추가 노력 없이 훨씬 더 큰 데이터 세트를 처리할 수 있습니다.
1단계: 파이썬 함수를 사용하여 결측치 처리 자동화
결측치는 데이터 세트에서 가장 흔한 문제 중 하나이며, 제대로 처리하지 않으면 큰 혼란을 초래할 수 있습니다.
데이터 세트와 문제에 따라 결측치가 있는 행을 삭제하거나 기본값으로 채우거나 imputation과 같은 고급 기술을 사용할 수도 있습니다.
파이썬 함수를 사용하여 프로세스를 자동화하는 방법은 다음과 같습니다.
## Code Example: 결측치 처리
import pandas as pd
# 결측치를 처리하는 파이썬 함수 생성
def handle_missing_values(df, method = 'mean', fillValue = None):
if method == 'drop':
return df.dropna()
elif method == 'fill':
return df.fillna(fillValue)
elif method == 'mean':
return df.fillna(df.mean())
else:
raise ValueError("Invalid method provided")
# 예제 데이터
tempData = {'Name': ['Alice', 'Bob', None, 'David'],
'Age': [25, None, 30, 22],
'Salary': [50000, 60000, None, 45000]}
tempDf = pd.DataFrame(tempData)
tempDf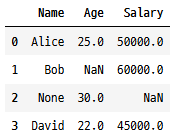
# 평균값으로 결측치를 대체하는 함수 사용 예
cleanedDf = handle_missing_values(tempDf, method = 'mean')
cleanedDf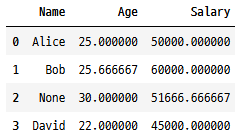
이 함수는
- dropna()를 사용하여 누락된 값을 삭제할 수 있습니다.
- fillna()를 사용하여 누락된 값을 특정 값으로 채울 수 있습니다.
- 연속형 데이터에 대한 일반적인 전략인 숫자형 열을 열의 평균으로 자동으로 채울 수 있습니다.
일반적인 실수
많은 사람들이 전체 데이터 세트에 어떤 영향을 미치는지 생각하지 않고, 누락된 값을 수동으로 삭제하거나 채웁니다.
일관된 방법을 사용하는 것이 필수적입니다.
2단계: 중복을 효율적으로 제거하기
중복 데이터는 데이터 세트에서 발생하는 또 다른 일반적인 문제입니다.
이를 제거하는 것은 간단해 보이지만, 실수로 중요 데이터를 삭제하지 않도록 하는 것은 까다로울 수 있습니다.
## Code Example: 중복데이터 제거
import pandas as pd
# 특정 칼럼에 기반한 중복 데이터를 제거하는 함수 정의
def remove_duplicates(df, subset = None):
return df.drop_duplicates(subset = subset)
# 중복된 행을 가지는 예제 데이터 생성
tempData = {'Name': ['Alice', 'Bob', 'Alice', 'David'],
'Age': [25, 30, 25, 22],
'Salary': [50000, 60000, 50000, 45000]}
tempDf = pd.DataFrame(tempData)
tempDf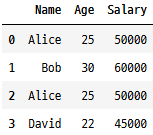
# 'Name' 열에 중복 데이터 제거
cleanedDf = remove_duplicates(tempDf, subset = ['Name'])
cleanedDf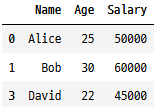
이 예에서 subset 인수를 사용하여 중복을 검사할 열을 지정했습니다.
이렇게 하면, 일부 열만 반복될 수 있는 행을 실수로 제거하는 것을 방지할 수 있습니다.
일반적인 실수
초보자 중에는 drop_duplicates() 함수를 사용할 때 어떤 열이 중복에 기여하는지 확인하지 않는 경우가 많습니다.
이로 인해 중요한 정보가 손실될 수 있으니, 주의하셔야 합니다.
3단계: 파이프라인에서 데이터 유형 변환
지저분한 데이터로 작업할 때 문자열로 저장된 숫자 값과 같은 잘못된 데이터 유형을 접하는 경우가 있습니다.
이 변환 프로세스를 자동화하여 데이터 파이프라인에 통합할 수 있습니다.
## 코드 예제: 데이터 유형 변환 자동화
# 데이터 유형 변환을 위한 함수 정의
def transform_data_types(df, col_types):
for col, dtype in col_types.items():
df[col] = df[col].astype(dtype)
return df
# 잘못된 데이터 유형을 가지는 데이터 예시
data = {'Name': ['Alice', 'Bob', 'David'],
'Age': ['25', '30', '22'],
'Salary': ['50000', '60000', '45000']}
df = pd.DataFrame(data)
# 올바른 데이터 유형 명시
col_types = {'Age': 'int', 'Salary': 'float'}
# 변환 적용
cleaned_df = transform_data_types(df, col_types)
cleaned_df.dtypes
--------------------------------------------------------------
Name object
Age int32
Salary float64
dtype: object이 예제에서는 특정 열의 데이터 유형을 변환하는 사용자 정의 함수를 만들어 숫자형 데이터가 분석을 위해 올바르게 처리되도록 합니다.
일반적인 실수
데이터 유형을 행별로 수동으로 변환하는 것은 비효율적이고 오류가 발생하기 쉽습니다.
특히 대용량 데이터 세트를 다루는 경우 더욱 그렇습니다.
4단계: 자동화된 데이터 정리 파이프라인 구축
사용자 정의 함수가 준비되면 이를 데이터 클린징 파이프라인으로 결합할 수 있습니다.
이 접근 방식을 사용하면 일관되고 자동화된 워크플로를 사용하여 모든 데이터 세트를 처리할 수 있습니다.
# 데이터 클린징 파이프라인 완성 빌드업
def data_cleaning_pipeline(df, missing_values_method = 'mean', fill_value = None, subset = None, col_types = None):
# 결측치 처리
df = handle_missing_values(df, method = missing_values_method, fillValue = fill_value)
# 중복 데이터 제거
df = remove_duplicates(df, subset = subset)
# 데이터 유형 변환
if col_types:
df = transform_data_types(df, col_types)
return df
# 여러가지 문제가 있는 데이터를 가지는 예제 데이터 셋
data = {'Name': ['Alice', 'Bob', None, 'Alice'],
'Age': ['25', None, '30', '22'],
'Salary': [50000, 60000, None, 50000]}
df = pd.DataFrame(data)
# 데이터 유형 정리 및 파이프라인 적용
col_types = {'Age': 'int', 'Salary': 'float'}
cleaned_df = data_cleaning_pipeline(df, missing_values_method = 'mean', subset = ['Name'], col_types = col_types)
cleaned_df
-----------------------------------------------------------------
Name Age Salary
0 Alice 25 50000.0
1 Bob 25 60000.0
2 None 30 52500.0
이 파이프라인은 결측치를 처리하고, 중복을 제거하고, 데이터 유형을 한 번에 변환하는 전체 정리 프로세스를 자동화합니다.
데이터 세트와 정리 요구 사항에 따라 파이프라인을 사용자가 지정할 수 있습니다.
결론: 파이썬을 이용한 데이터 정리 간소화
파이썬에서 데이터 클린징을 자동화하면 워크플로를 훨씬 더 효율적이고 일관적이며 확장 가능하게 만들 수 있습니다.
함수를 정의하고 정리 파이프라인을 구축하면 데이터가 아무리 지저분하더라도 전처리가 완료된 데이터를 확보할 수 있습니다.
이러한 작업을 자동화하면 시간을 절약할 뿐만 아니라 오류도 줄어든다는 것을 알았습니다.
이러한 기술은 데이터 분석에 대한 접근 방식을 바꾸는데 도움이 될 수 있습니다.
이러한 파이썬 기술을 워크플로에 통합하면 데이터 정리 과제를 더 잘 처리할 수 있습니다.
데이터가 정리되면 본격적인 데이터 분석을 시작할 준비가 되었다고 할 수 있습니다.