이번 포스팅에서는 테이터 탐색 분석 시 알아야 할 파이썬 기본 함수에 대해서 알아보겠습니다. 간단하지만, 가장 많이 사용하고 유용한 함수로 꼭 알고 있어야 하는 함수입니다.
데이터 탐색 분석의 기본 프로세스를 보다 효율적으로 할 수 있는 9가지 함수를 소개합니다.
필요 패키지 로드
필수 패키지인 pandas 와 numpy를 로드합니다.
import pandas as pd
import numpy as np실습 데이터 다운로드
실습을 위해 필요한 데이터를 다운로드합니다. 데이터는 판다스 마스터하기 포스팅에서 사용한 타이타닉 데이터를 활용하겠습니다. 실습 데이터를 D 드라이브에 다운로드 한 후 메모리에 업로드 합니다.
# D드라이브에 다운로드 한 실습 데이터 메모리에 업로드 하기
analysisData = pd.read_csv("D:/titanic.csv")데이터프레임 기본 정보 확인하기
데이터 탐색 분석 시 가장 먼저 해야 하는 작업 중 하나는 분석하고자 하는 데이터프레임의 기본 정보를 확인하는 것입니다. 이러한 작업을 하기 위해서는 info() 함수를 사용합니다.
analysisData.info()
-------------------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB모든 데이터프레임에 대해 info() 함수는 전체 데이터 건수, 각 열의 이름 및 데이터 유형, null이 아닌 값의 건수를 알려줍니다. null이 아닌 값의 양을 총 항목 수와 비교하여 null 값이 있는 열을 찾을 수 있습니다.
우리가 실습하기 위해 다운로드 한 타이타닉 데이터는
- 전체 데이터 건수: 891건
- 열(변수)의 개수: 12개 (PassengerId, … , Embarked)
- 데이터 유형
- PassengerId ~ Pclass, SibSp, Parch : 숫자형(정수형) – int
- Name, Sex, Ticket, Cabin, Embarked : 문자형 – object
- Age, Fare : (소수점을 가지는)숫자형 – float
- 변수별 Null이 아니 값의 건수
- PassengerId ~ Sex, SibSp ~ Fare : 891건 (즉, 모든 데이터에 null이 존재하지 않습니다.)
- Age: 714건 (즉, 177개의 null 값이 존재합니다.)
- Cabin: 204건 (즉, 687개의 null 값이 존재합니다.)
- Embarked: 889건 (즉, 2개의 null 값이 존재합니다.)
중복된 행의 존재 여부 확인하기
데이터 프레임에서 중복 행을 찾는 방법은 여러 가지가 있습니다. 그 중 가장 쉬운 함수는 duplicated() 입니다. duplicated() 함수는 행이 중복되는 지 확인하여, 중복된 데이터인 경우 True를 반환하고, 중복된 행이 아니면, False를 반환합니다.
이를 sum() 함수와 함께 사용하면 중복 행이 몇 개나 있는지 알 수 있습니다.
analysisData.duplicated().sum()
--------------------------------------
0실습 데이터에는 중복 값을 가지는 행이 존재하지 않음을 확인할 수 있습니다.
데이터프레임의 열별 고유한 값 (unique value) 확인하기
데이터 탐색 분석 시 우리는 몇 가지 핵심 열에 집중합니다. 우리의 관심의 대상이 되는 열의 모든 고유 값을 빠르게 확인하여 값의 범위를 이해할 수 있습니다.
사용방법은 아래와 같습니다.
# 'Cabin' 열의 고유한 값 확인하기
analysisData["Cabin"].unique()
-----------------------------------------------------------------------------------
array([nan, 'C85', 'C123', 'E46', 'G6', 'C103', 'D56', 'A6',
'C23 C25 C27', 'B78', 'D33', 'B30', 'C52', 'B28', 'C83', 'F33',
'F G73', 'E31', 'A5', 'D10 D12', 'D26', 'C110', 'B58 B60', 'E101',
'F E69', 'D47', 'B86', 'F2', 'C2', 'E33', 'B19', 'A7', 'C49', 'F4',
'A32', 'B4', 'B80', 'A31', 'D36', 'D15', 'C93', 'C78', 'D35',
'C87', 'B77', 'E67', 'B94', 'C125', 'C99', 'C118', 'D7', 'A19',
'B49', 'D', 'C22 C26', 'C106', 'C65', 'E36', 'C54',
'B57 B59 B63 B66', 'C7', 'E34', 'C32', 'B18', 'C124', 'C91', 'E40',
'T', 'C128', 'D37', 'B35', 'E50', 'C82', 'B96 B98', 'E10', 'E44',
'A34', 'C104', 'C111', 'C92', 'E38', 'D21', 'E12', 'E63', 'A14',
'B37', 'C30', 'D20', 'B79', 'E25', 'D46', 'B73', 'C95', 'B38',
'B39', 'B22', 'C86', 'C70', 'A16', 'C101', 'C68', 'A10', 'E68',
'B41', 'A20', 'D19', 'D50', 'D9', 'A23', 'B50', 'A26', 'D48',
'E58', 'C126', 'B71', 'B51 B53 B55', 'D49', 'B5', 'B20', 'F G63',
'C62 C64', 'E24', 'C90', 'C45', 'E8', 'B101', 'D45', 'C46', 'D30',
'E121', 'D11', 'E77', 'F38', 'B3', 'D6', 'B82 B84', 'D17', 'A36',
'B102', 'B69', 'E49', 'C47', 'D28', 'E17', 'A24', 'C50', 'B42',
'C148'], dtype=object)Cabin 열에는 nan(null value), ‘C85’, … , ‘C148’ 의 값을 가지는 것을 확인할 수 있습니다.
열의 고유한 값 (unique value)들의 건수 확인하기
‘Cabin’ 의 고유한 값은 확인한 후에는, 고유한 값들이 몇 건씩 있는 지 확인해야 합니다. 이럴 때 활용할 수 있는 함수가 value_counts() 입니다.
analysisData["Cabin"].value_counts()
------------------------------------------
B96 B98 4
G6 4
C23 C25 C27 4
C22 C26 3
F33 3
..
E34 1
C7 1
C54 1
E36 1
C148 1
Name: Cabin, Length: 147, dtype: int64null 값 대체하기
analysisData.replace(np.nan, "0", inplace = True)replace() 함수는 전체 데이터프레임을 가져와 null 값을 “0”으로 채우거나 함수의 두 번째 인수에 입력한 값(여기서는 “0”)으로 채웁니다. 이는 null 값을 없애고 분석에서 더 많은 오류를 피할 수 있는 빠른 방법입니다.
null 값이 분석에 영향을 미치는지 확실하지 않은 경우 null 값을 채우거나 널 값을 보유한 을 삭제하는 것이 좋습니다.
데이터 프레임에서 특정 조건을 만족하는 행만 가져오기
analysisData2 = analysisData[analysisData["Fare"] > 50]
analysisData2
----------------------------------------------------------------------
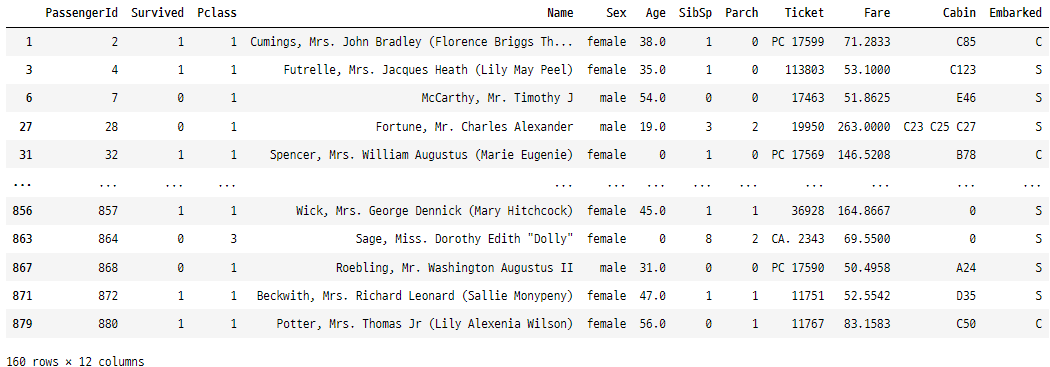
위의 코드는 “Fare” 열이 50보다 큰 행 만을 가져와서 새로운 데이터프레임인 analysisData2에 저장하는 코드입니다. 물론 “작음” 또는 “같음”과 같은 다른 조건과 여러 조건을 동시에 사용하여 더 복잡한 조건으로 필터링할 수도 있습니다.
데이터프레임의 모든 열에 대한 상자 그림 (boxplot) 그리기
analysisData.boxplot()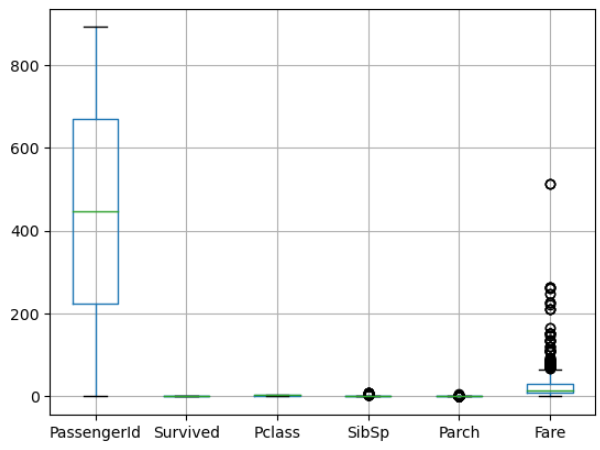
위 함수는 데이터 세트의 모든 숫자 열에 대한 상자 그림을 반환합니다. 특정 열에 대해서만 상자 그림을 출력하려면, 아래와 같이 특정 열을 지정해 주면 됩니다.
상관관계 행렬 생성하기
analysisData.corr()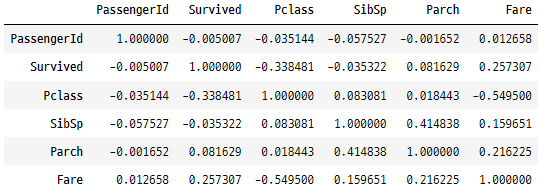
corr() 함수는 숫자형 열의 모든 쌍에 대한 상관관계를 반환합니다.
결론
이번 포스팅에서는 데이터 탐색 분석 시 기본적으로 알아야 하는 파이썬 기본 함수에 대해서 알아보았습니다. info(), unique(), value_counts(), replace(), boxplot(), corr(), 데이터 필터링 방법 등은 필수적으로 사용되는 함수이니 만큼, 잘 알아두면 많은 도움이 됩니다.
감사합니다.