모델 구축 후 성능을 파악하는데 있어 자주 사용하는 모델 성능 지표 에 대해서 알아보겠습니다. 모델 구축의 핵심은 일반화와 강건함을 유지하는 것입니다.
이를 달성하기 위해서는 모델이 충분히 좋은지 또는 성능을 개선하기 위해 약간의 수정이 필요한지 파악하기 위해 모델을 평가해야 합니다. 모델을 평가할 때는 예측 능력, 일반화 가능성 및 전반적인 품질을 평가하는 것이 중요합니다.
모델 성능 지표 의 선택은 데이터 유형에 따라 달라집니다.
모델러는 견고한 모델을 제공할 수 있어야 합니다. 견고한 모델을 구축하려면 모델 성능을 지속적으로 평가하고 적절하게 수정하여야 합니다.
이번 포스팅에서는 분류(classification) 및 회귀(regression) 평가 지표 및 성능 지표 의 선택 방법, 장단점을 살펴보겠습니다.
예측 모델
예측 모델은 분류 모델과 회귀 모델, 두 가지 유형이 있습니다. 분류 모델의 최종 결과값은 클래스 라벨이고 회귀 모델은 연속 값입니다.
분류 모델
분류 작업은 주어진 입력 데이터 포인트에 대한 클래스 레이블을 예측하는 것입니다. 이진 분류에서는 가능한 결과가 두 가지뿐인 반면 다중 클래스 분류에서는 두 개 이상의 클래스가 존재합니다.
또한 분류 모델은 최종 결과값 유형에 따라 두 가지 유형이 있습니다.
결과값이 클래스인 경우
SVM, KNN 등의 알고리즘은 클래스 결과값을 생성합니다. 예를 들어 이진 분류 문제에서 결과값은 1 또는 0이 됩니다. 다중 클래스 분류 문제인 경우 결과값은 기본적으로 클래스 중 하나입니다.
결과값이 확률인 경우
로지스틱 회귀, 랜덤 포레스트, 그래디언트 부스팅 등과 같은 알고리즘은 확률값을 제공합니다. 이제 이 확률값을 클래스 레이블로 변환하는 것은 임계값 확률에 따라 달라집니다.
회귀 모델
회귀 분석에서 결과값은 항상 연속적인 특성을 가지며 추가적인 처리가 필요하지 않습니다.
분류 모델 성능 지표
정확성 ( Accuracy )
정확성은 가장 일반적이고 간단한 모델 성능 지표 입니다. 정확성은 바르게 분류된 데이터의 비율을 데이터 총 건수로 나눈 값입니다.
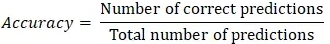
정확성은 클래스가 균형 있는 데이터(Ex. 클래스가 남성과 여성인 경우, 남성 데이터 건수와 여성 데이터 건수가 유사한 데이터)에서 좋은 성능 지표입니다.
반대로 클래스가 불균형한 경우(Ex. 대표적인 예 – 클래스가 암환자와 정상환자인 경우) 오해의 소지가 있는 지표가 될 수 있습니다. 모델의 정확성은 높지만, 실제로 모델의 판별력은 매우 낮게 나타날 수 있습니다.
예를 들어, 1000개(환자)의 테스트 데이터 중 950개(건강한 환자)가 양성이고 50개(병든 환자)가 음성이라고 가정해 보겠습니다. 어떤 모델이 모든 데이터를 양성(즉, 모든 환자가 건강한 것)으로 분류하면 정확도는 95%가 높습니다.
이러한 결과는 ‘멍청한 모델(모든 결과를 정상환자라고 분류)’이라는 것을 알고 있습니다. 실제 병든 환자를 건강하다고 예측합니다. 이것은 사람들이 특정 질병을 치료하기 위한 의료 지원을 받지 못하게 되어 매우 나쁜 결과를 초래할 것입니다.
따라서 불균형한 데이터 세트인 경우에는 정확성을 사용하지 않아야 합니다.
Confusion matrix (혼동 행렬)
혼동 행렬은 이름에서 알 수 있듯이 N*N 행렬을 결과값으로 제공하는데, 여기서 N은 대상 클래스의 수입니다(이진 분류 모델에서 N = 2). 혼동 행렬은 모델이 만든 정확한 예측과 잘못된 예측의 수를 표 형식으로 요약한 것입니다.
이 행렬은 실제 값과 모델이 예측한 값을 비교합니다.
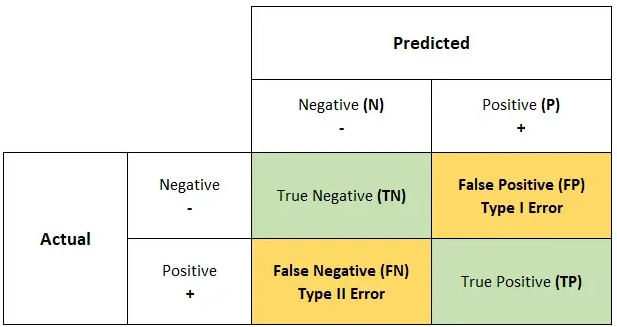
혼동 행렬에 대한 이해
아래 4가지 기본 용어는 혼동 행렬을 더 잘 이해하는 데 도움이 됩니다.
- True Positive (TP): 실제 값은 양수이고 예측 값도 양수
- True Negative (TN): 실제 값은 음수이고 예측 값도 음수
- False Positive (FP): 실제 값은 음수이고 예측 값은 양수
- False Negative (FN): 실제 값은 양수이고 예측 값은 음수
유의해야 할 핵심 사항은 아래와 같습니다.
- 좋은 모델은 TP와 TN 비율이 높고 FP와 FN 비율이 매우 낮아야 합니다.
- 혼동 행렬은 정확도에 비해 직관적으로 더 나은데, 정확도에서는 True Positive와 True Negative에만 신경을 쓰는 반면 잘못 분류된 사례에 대한 정보는 전혀 없기 때문입니다.
Precision (정밀도)
정밀도는 양성 예측 중 참 양성의 비율을 측정하는 지표입니다. 이는 올바르게 분류된 양성 데이터의 총 건수를 예측된 양성 데이터 총 건수로 나누어 계산합니다.
다시말해서, 정밀도는 모델이 양성으로 예측한 모든 데이터 중 실제로 양성인 데이터 건수의 비율을 의미합니다.

Recall (재현율)
재현율은 실제 양성 중 참 양성의 비율을 측정하는 지표입니다. 올바르게 분류된 양성 데이터의 총 건수를 실제로 양성인 데이터의 총 건수로 나누어 계산합니다.
재현율은 거짓 음성이 거짓 양성보다 더 큰 우려를 불러일으키는 경우에 유용한 지표입니다. 거짓 경보의 발생 여부는 중요하지 않지만 실제 양성 사례는 감지되지 않아야 하는 의료 사례에서 매우 중요합니다.
다시말해서, 재현율은 실제 양성 데이터 건수 중에서 양성으로 예측되는 데이터 건수의 비율을 의미합니다.
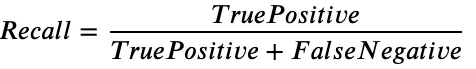
F1 Score
정밀도와 재현율을 모두 모니터링하는 것은 불편할 수 있어, 정밀도와 재현율을 모두 결합한 하나의 지표가 있다면 더 좋을 것입니다. F1score는 이 문제를 해결하는 데 유용합니다.
F1score는 정밀도와 재현율을 단일 점수로 결합한 지표로, 정밀도와 재현율의 조화 평균으로 계산됩니다.
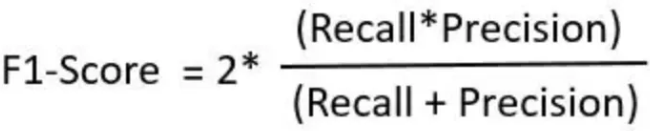
AUROC (Area Under ROC Curve)
AUROC 곡선은 클래스를 구분하는 다양한 임계값에서 TPR(참 양성률)과 FPR(거짓 양성률)을 플로팅하는 확률 곡선입니다. 이 곡선은 분류 모델이 다양한 임계값에서 두 클래스를 얼마나 잘 구별하는지 보여주는 그래프입니다.
AUC가 높을수록 예측력이 뛰어난 모델입니다. 아래는 y축에 TPR, x축에 FPR이 있는 ROC 곡선을 보여주는 그래프입니다.
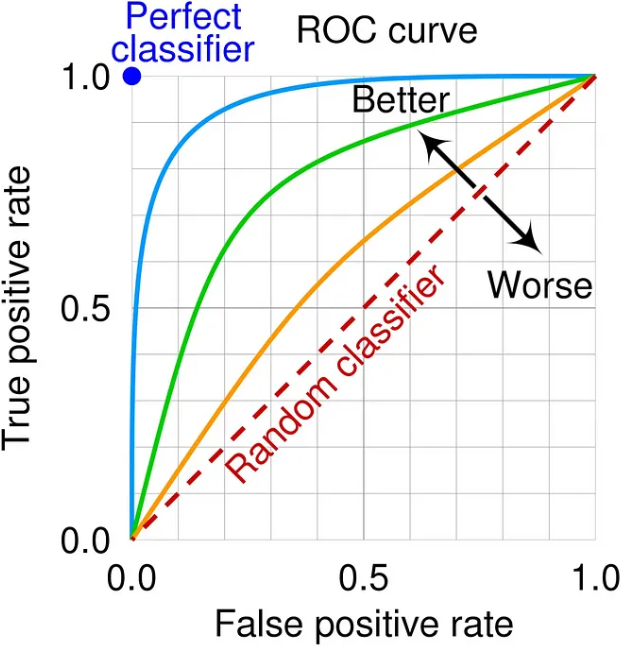
분류모델의 성능은 FPR이 크게 증가하지 않고도 높은 TPR을 달성할 때 최적이라고 간주됩니다. 따라서 높은 TPR과 낮은 FPR을 나타내는 ROC 곡선의 왼쪽 상단 모서리는 이상적인 균형 또는 “스위트 스팟”을 나타냅니다(Perfect classifier).
곡선이 대각선 위에 있는 경우(즉, 왼쪽 아래에서 오른쪽 위로) 대각선이 TPR = FPR인 곳을 의미하기 때문에 무작위 추측보다 모델이 더 좋습니다.
AUC에 대한 이해
AUC는 “곡선 아래의 면적(Area Under Curve)”을 의미합니다. 그럼 왜 면적이 필요한 걸까요? ROC 곡선이 다양한 임계값에 대한 True Positive Rate(TPR)와 False Positive Rate(FPR)를 표시하기 때문입니다.
ROC 곡선을 통해 시각적으로 모델에 접근하는 대신(다양한 상황에서 어려울 수 있음) 단일 숫자 값으로 요약하고 있으며, AUC가 높을수록 모델 성능이 우수함을 나타냅니다.
단일 AUC 값은 여러 모델을 빠르게 비교할 수 있게 해줍니다. AUC 값이 1이면 완벽한 분류모델이고, 0.5와 1 사이이면 무작위 모델보다 성능이 더 나은 것으로 간주됩니다. 0.5보다 작으면 무작위 모델보다도 성능이 좋지 못한 것으로 간주됩니다.
Log loss
로그 손실은 특히 확률적 예측의 맥락에서 분류 모델(이진 및 다중 클래스 분류 문제 모두)의 성능을 평가하는 데 사용되는 지표입니다. ‘손실’이라는 용어는 실제 결과값을 충족하지 못한 것에 대해 지불하는 페널티를 의미합니다.
이 지표는 예측된 확률이 실제 클래스 레이블과 얼마나 잘 일치하는지를 평가합니다. 로그 손실은 확실하게 잘못된 예측에 대해 모델에 더 큰 페널티를 부과합니다.
로그 손실은 0과 무한대 사이의 값을 가집니다. 로그 손실이 낮을수록 모델 성능이 더 좋습니다. 로그 손실이 0이면 예측된 확률이 실제 결과와 완벽하게 일치하는 반면 값이 높을수록 편차 수준이 증가함을 나타냅니다.

로그 손실은 모델이 정확할 뿐만 아니라 예측에 대한 자신감도 갖도록 해줍니다.
회귀 모델 성능 지표
결과값이 실수일 경우 앞서 논의한 성능 지표를 더 이상 사용할 수 없습니다. 분류 문제와 달리 회귀는 클래스가 아닌 연속적인 숫자 값의 형태로 결과값을 제공합니다. 회귀 기반의 모델 성능을 나타내기 위한 지표는 다음과 같습니다.
평균 절대 오차 (MAE)
회귀 모델에서의 가장 간단하고 일반적인 지표입니다. 기본적으로 실제 값과 예측 값의 절대 차이의 평균 합계로 계산됩니다. 값이 낮을수록 모델의 성능이 더 좋습니다.

이 지표는 이상치에 강건하게 작용하는데, 그 이유는 이상치와 상관없이 모든 점을 동등하게 처리하기 때문입니다. 이 지표는 오류(오차)의 크기만 고려합니다.
하지만, MAE의 가장 큰 단점은 0에서 미분할 수 없다는 것입니다. 많은 최적화 문제에서 최적의 값을 찾기 위해 미분을 사용합니다. 다시 말해서, MAE를 최소로 하기 위한 접근이 어렵습니다.
평균 제곱 오차 (MSE)
회귀 모델에서 사용하는 가장 간단하고 일반적인 메트릭이고, L2 손실이라고도 합니다. 실제 값과 예측 값 차이의 제곱합에 대한 평균으로 계산됩니다.

이 지표의 문제점은 이상치와 상관없이 모든 점을 동등하게 취급한다는 것입니다. 따라서 이 지표도 이상치에 강건하게 작용합니다. 또한 오류는 제곱으로 인해 과대 표현됩니다.
MSE는 0에서 무한대까지 발생 가능하며 모델은 값이 0에 가까울수록 좋습니다. 이 지표가 이전 지표에 비해 유리한 점은 최적의 값을 찾을 수 있기 때문에 차별화할 수 있다는 것입니다.
평균 제곱근 오차 (RMSE)
평균 제곱근 오차(RMSE)는 평균 제곱 잔차의 제곱근으로 계산됩니다. RMSE의 장점은 결과값의 단위가 데이터 척도와 동일하기 때문에 해석하기 쉽다는 것입니다. 예를 들어, 10명의 성인 남녀 키(cm)의 MSE 단위는 cm2 인 반면, RMSE 단위는cm로 데이터와 동일 단위입니다. 그 외에는 MSE와 매우 유사합니다.

R 제곱근 오차 (R squared error)
R² 오차를 이해하려면 Total Sum of Square(TSS)를 이해해야 합니다. TSS는 결과값들의 평균(y의 평균)으로 만들 수 있는 가장 기본적인 모델이라고 할 수 있습니다.
가장 기본적인 이러한 모델은 x축과 평행한 직선으로, 모든 관찰값 x에 상관없이 예측값이 y의 평균으로 동일합니다. 이는 기본적으로 가장 간단한 평균 모델입니다.
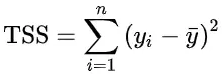
잔차 제곱합(RSS)은 선형 회귀에서 적합된 선에 대한 기대값과 실제값의 차이를 측정합니다.

R² 값은 0과 1 사이의 범위에 있습니다. R² 값이 1에 가까울수록(RSS의 값이 0에 수렴할수록 (=선형 회귀의에서 적합된 선에 대한 기대값과 추정값의 차이가 없을수록) 모델의 성능은 더 좋습니다.
R 제곱 오차의 해석
- 사례 1: R² = 1
- SSR = 0, 모든 ei = 0 => R² = 1 인 경우
- 실제로 존재할 가능성이 거의 없는 가장 이상적인 모델입니다.
- 사례 2: R²>0이고 R² <1일 때
- 전형적인 사례로 값이 1에 가까울수록 모델의 성능이 더 좋습니다.
- 사례 3: R² = 0
- SSR = SST 모델로서 가치가 없다고 할 수 있습니다.
- 사례 4: R²<0
- SSR > SST 을 의미하는 것으로 이 모델은 단순 평균 모델보다도 더 성능이 좋지 않다는 것을 의미합니다.
조정된 R 제곱 오차
조정된 R²은 R²을 계산할 때 독립 변수의 수를 고려하므로 R²의 업데이트된 버전이라고 할 수 있습니다. R² 성능 지표의 단점은 예측 변수(x)가 증가하면 R² 값도 증가한다는 것입니다.
이를 극복하기 위한 성능 지표가 조정된 R 제곱 오차입니다. 이는 예측 변수의 수를 늘리면 페널티가 발생하는 구조를 가집니다. 이를 통해 과적합을 방지할 수 있습니다.
또한 조정된 R²의 값은 예측 변수가 모델에 의미 있게 기여하는 경우에만 증가합니다.

요약하자면, 조정된 R²은 모델의 복잡성(예측 변수 수)과 예측 능력 간의 균형을 고려하기 때문에 모델의 적합도를 측정하는 데 더 신뢰할 수 있는 지표입니다.
이 지표는 예측 변수 수를 늘리면서 모델의 성능을 향상시키고자 할 때, 모델 개발에 접근하는 매우 유용한 성능 지표입니다.
결론
결론적으로, 우리의 목적에 가장 적합한 모델을 선택하기 위해서는 모델의 성능을 평가하는 것이 매우 중요합니다. 성능 지표의 선택은 해결하려는 문제의 유형, 데이터의 특성, 분석의 목표에 따라 달라집니다.
항상 좋은 성능을 보이고 일반화된 모델을 구축하는 데 도움이 되는 절대적인 기준을 가지는 성능 지표는 없습니다. 이러한 메트릭을 이해하고 적절하게 사용하면 더 나은 모델과 더 정확한 예측으로 이어질 수 있습니다.