이번 포스팅에서는 분석을 향상시키는 7가지 판다스 함수 에 대해서 알아보겠습니다.
단순히 dropna()나 fillna()를 말하는 것이 아닙니다. 여러 프로젝트를 진행하고 더 많은 것을 공부한 데이터 분석가로서,
이번 포스팅에서 설명하고 있는 판다스 함수가 데이터 분석 프로세스에서 엄청나게 도움이 된다는 것을 알게 되었습니다.
이번 포스팅의 목적은 개념이나 주제를 가능한 한 간단하게 설명하여 게시물을 아래로 쓸어 넘길 때마다 약간의 지식을 얻을 수 있도록 하는 것입니다.
판다스는 어떤 패키지인가?
판다스는 구조화되고 반구조화된 데이터로 작업하여 데이터 조작 및 분석 작업을 수행하는 데 사용되는 최고의 파이썬 라이브러리입니다.
특히 데이터 분석 프로세스에서 많이 사용합니다.
데이터 정리부터 데이터 시각화에 이르기까지 프로젝트에서 필요한 대부분의 작업을 수행하는 데 필요한 라이브러리입니다.
판다스에는 두 가지 기본 데이터 구조가 있습니다.
1차원(Series) 데이터 구조와 더 널리 사용되는 2차원(DataFrame) 데이터 구조입니다.
소규모 프로젝트의 경우 판다스 라이브러리를 사용하여 모든 작업을 실행하는 것이 전적으로 가능합니다.
판다스 라이브러리를 사용하기 위해 먼저 해야 할 일은 라이브러리를 가져오는 것입니다.
import pandas as pd그럼 중요하고 유용한 7개의 판다스 함수에 대해서 설명하겠습니다.
.update()
여러 가지 방법으로 사용할 수 있지만, 제가 좋아하는 용도는 “격리 및 수정”이라는 용어로 설명할 수 있습니다.
데이터 세트의 “월” 열에서 나머지 데이터와 일치하지 않는 행을 발견했다고 가정해 보겠습니다.
이 행의 다른 열이 일반 데이터와 다르다는 것을 알아챘습니다.
이를 해결하기 위해 이러한 이상한 행을 추출하고 모든 문제를 수정한 다음 수정된 행을 다시 데이터 세트에 통합합니다.
이것이 어떻게 진행되는지에 대한 예시는 아래와 같습니다.
# 샘플 데이터
data1 = pd.DataFrame({
'월': ['Jan', 'Feb', 'Marh', 'Aprh'],
'값': [10, 20, 305, 405]
}, index = [1, 2, 3, 4])
data1
--------------------------------------------------------
월 값
1 Jan 10
2 Feb 20
3 Marh 305
4 Aprh 405# 잘못된 값으로 판단되는 데이터 추출
data = pd.DataFrame({
'월': ['Aprh','Marh'],
'값': [305, 405]
}, index=[3, 4])
# 수정 데이터 정의
data2 = pd.DataFrame({
'월': ['Apr', 'Mar'],
'값': [30, 40]
}, index=[3, 4])
# raw data를 수정값들로 업데이트
data1.update(data2)
data1
--------------------------------------------------------
월 값
1 Jan 10.0
2 Feb 20.0
3 Apr 30.0
4 Mar 40.0.apply()
이 함수는 DataFrame 또는 Series의 축을 따라 함수를 적용하는 데 사용하는 강력한 방법입니다. 매우 다재다능하며 사용자 정의 함수 적용, 데이터 변환, 데이터 분류를 포함한 다양한 작업에 사용할 수 있습니다. 이 함수를 일반적으로 사용하는 세 가지 사례를 살펴보겠습니다.
열의 각 값에 함수 적용
# 샘플 데이터
data = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
data['A'] = data['A'].apply(lambda x: str(x) )
print(data.info())
---------------------------------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 3 non-null object
1 B 3 non-null int64
dtypes: int64(1), object(1)
memory usage: 180.0+ bytes
None새로운 열에 대한 데이터 분류
# 샘플 데이터
data = pd.DataFrame({
'Age': [11, 16, 30, 51]
})
data['Category'] = data['Age'].apply(lambda x: 'Child' if x <= 12 else 'Teenager' if x <= 18 else 'Adult')
print(data)
--------------------------------------------------------------------------------------------------------------
Age Category
0 11 Child
1 16 Teenager
2 30 Adult
3 51 Adult새로운 데이터 프레임 생성
# 샘플 데이터
data = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
print(data)
---------------------------------------------------
A B
0 1 4
1 2 5
2 3 6
# 각 요소들에 람다 함수 적용
dataSquared = data.apply(lambda x: x ** 2)
print(dataSquared)
---------------------------------------------------
A B
0 1 16
1 4 25
2 9 36.pipe()
이 함수를 사용하면 파이프라인에서 DataFrame 또는 Series에 일련의 함수를 적용할 수 있으며, R의 %>%와 매우 유사합니다. 작업을 함께 연결하여 코드를 더 읽기 쉽고 유지 관리하기 쉽게 만드는 데 도움이 됩니다.
예를 들어, 데이터 세트가 있고 열이 올바른 스케일이 아니며 데이터를 정리하기 위해 일련의 작업을 수행해야 한다고 가정해 보겠습니다. 적용 방법은 다음과 같습니다.
# 샘플 데이터
data = pd.DataFrame({
'A': [10, 20, 30],
'B': [1, 2, 3]
})
def multiply(df):
df['A'] *= 100
return df
def add(df):
df['B'] = df['B'] + 10
return df
# A의 값에 100을 곱하고, B의 값에 10을 더합니다.
data.pipe(multiply) \
.pipe(add) \
.pipe(print)
-----------------------------------------------------------
A B
0 1000 11
1 2000 12
2 3000 13pd.crosstab()
이 함수는 범주형 데이터로 작업할 때 자주 사용하는 함수입니다. 두 개 이상의 범주형 변수의 교차점의 빈도 분포를 표시하는 표를 생성합니다. 표시되는 빈도는 데이터를 백분율 또는 상대 빈도로 나타내는 값 또는 비율의 조합의 발생 횟수일 수 있습니다.
예를 들어, “성별” 열과 “사고 심각도” 열이 있는 도로 사고 정보가 포함된 데이터 세트가 있다고 가정해 보겠습니다. “남성이 여성보다 더 심각한 사고에 연루되는가?”와 같은 정보를 찾고 싶습니다. 이는 질문에 답하는 데 사용할 수 있는 접근 방식입니다.
data = pd.DataFrame({
'성별': ['male', 'male', 'female', 'male', 'male', 'female', 'female'],
'사고 심각도': ['1.경미', '2.심각', '3.매우 심각','1.경미', '2.심각', '3.매우 심각', '3.매우 심각']
})
# 발생 횟수로 빈도 제공
crossdf = pd.crosstab(data['사고 심각도'], data['성별'])
crossdf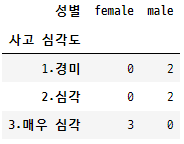
# 빈도를 비율로 표시
crossdf = pd.crosstab(data['사고 심각도'], data['성별'], normalize = 'index')
crossdf
----------------------------------------------------------------------------------
성별 female male
사고 심각도
1.경미 0.0 1.0
2.심각 0.0 1.0
3.매우 심각 1.0 0.0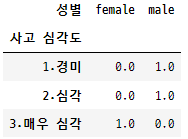
.pct_change()
이 함수는 주어진 축을 따라 현재 요소와 이전 요소 간의 백분율 변화를 계산합니다. 재무 또는 시계열 데이터와 같은 데이터의 상대적 변화를 분석하는 데 유용합니다.
추세 분석에 사용되는 비교적 간단하지만 매우 유용한 함수로, 시간에 따른 변화를 보여줍니다. 월별 판매 수치가 포함된 데이터 세트가 있다고 가정해 보겠습니다. 백분율 변화를 계산하는 방법은 다음과 같습니다.
data = pd.DataFrame({
'Month': ['Jan', 'Feb', 'Mar', 'Apr', 'May'],
'Sales': [2000, 2200, 2100, 2500, 2700]
})
# 'Month' 칼럼을 인덱스로 설정
data.set_index('Month', inplace = True)
# 백분율 변화 계산
data['Sales Change (%)'] = round((data['Sales'].pct_change() * 100), 2)
data
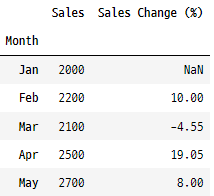
.get_dummies()
이 함수는 범주형 데이터를 데이터 모델링을 위한 머신 러닝 알고리즘에 입력할 수 있는 형식으로 변환하는 데 사용합니다. 일반적으로 “one-hot encoding”이라고 알려진 기술입니다. 이는 일반적으로 범주형 변수를 일련의 이진(0 또는 1) 또는 부울(참 또는 거짓) 열로 변환하여 수행됩니다. (범주형 데이터 인코딩하기 참고.)
scikit-learn에 유사한 작업을 수행하는 레이블 인코더 함수가 있는데, 이 두 함수는 상당히 다릅니다. get_dummies()는 범주 간에 순서를 암시하지 않기 때문에 비순서형 데이터에 더 선호됩니다. 반면 LabelEncoder는 더 간결하고 순서 관계가 있는 교육 수준(중학교 – 고등학교 – 대학교)과 같은 순서형 데이터에 적합합니다.
“예”/”아니요”인 질문에 대한 답변이 포함된 열이 있다고 가정해 보겠습니다. get_dummies()는 각 범주에 대해 하나씩 새 열을 생성합니다. 이러한 새로운 열의 각 행에는 해당 범주에 해당하는 열에는 1이, 다른 열에는 0을 표시합니다.
# 범주형 열이 있는 샘플 데이터프레임
data = pd.DataFrame({
'Answer': ['yes', 'no', 'no', 'yes', 'no']
})
# 범주형 열을 더미 변수로 변환
dummies = pd.get_dummies(data['Answer'])
print(dummies)
------------------------------------------------------
no yes
0 0 1
1 1 0
2 1 0
3 0 1
4 1 0.combine_first()
두 개의 DataFrame을 결합하는 데 사용됩니다. 한 DataFrame의 누락된 값을 다른 DataFrame의 값으로 채웁니다. 특히 서로를 보완하는 두 개의 데이터세트가 있고 이를 병합하여 완전한 데이터세트를 만들 때 유용합니다.
.merge() 함수와 매우 유사하지만, 차이점 중 하나는 두 DataFrame의 모든 고유 열을 자동으로 포함하고 공통 열을 기준으로 정렬하여 첫 번째 DataFrame의 누락된 값을 두 번째 DataFrame의 해당 값으로 채운다는 것입니다. 상황에 따라 .merge()와 상호 교환하여 사용할 수 있습니다.
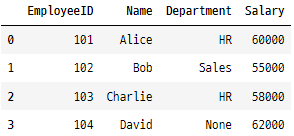
마지막으로 HR과 Sales라는 두 부서에서 직원 성과 데이터를 수집하는 회사를 가정해 보겠습니다. 두 부서 모두 직원 데이터를 추적하지만 서로 다른 측면에 중점을 둡니다. HR 데이터를 분석하고 싶지만 일부 값이 누락되었고 Sales에서 추가 정보가 필요한 경우 다음과 같이 합니다.
# HR Data (data1)
data1 = pd.DataFrame({
'EmployeeID': [101, 102, 103, 104],
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Department': ['HR', 'Sales', 'HR', None],
'Salary': [60000, 55000, 58000, 62000]
})
data1
# Sales Data (data2)
data2 = pd.DataFrame({
'EmployeeID': [101, 102, 104, 105],
'SalesTarget': [50000, 70000, 65000, 80000],
'SalesAchieved': [48000, 75000, 66000, 81000],
'Department': ['HR', None, 'Sales', 'Sales']
})
data2 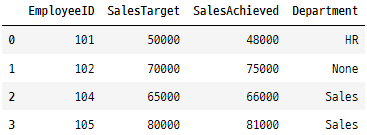
# combine_first 함수를 사용한 결합
combinedData = data1.set_index('EmployeeID').combine_first(data2.set_index('EmployeeID')).reset_index()
combinedData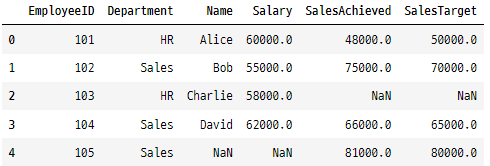
감사합니다.