이번 포스팅에서는 랜덤포레스트 하이퍼파라미터 조정 방법에 대해서 알아보겠습니다.
사이킷런을 사용하여 랜덤포레스트의 하이퍼파라미터 조정 프로세스를 탐색하려면 하이퍼파라미터의 중요성을 이해해야 합니다. 최적의 하이퍼파라미터를 찾기 위해 GridSearchCV를 활용하고, 체계적인 실험을 통해 모델의 정확도를 높이는 것이 필요합니다.
코드
사이킷런의 GridSearchCV를 통해 랜덤포레스트 하이퍼파라미터 조정을 완료하여 모델의 정확도를 높입니다.

from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# 하이퍼파라미터 그리드 정의
grid = {'n_estimators': [10, 50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'bootstrap': [True, False]}
# 랜덤포레스트 분류모델 초기화
rf = RandomForestClassifier()
# GridSearchCV 초기화
gridSearch = GridSearchCV(estimator = rf, param_grid = grid, cv = 5, n_jobs = -1, verbose = 2)
# 모델 적합
gridSearch.fit(X_train, y_train)
# Best 하이퍼파라미터
bestParams = grid_search.best_params_
print('Best parameters:', bestParams)
------------------------------------------------------------------------------------------------------------
Fitting 5 folds for each of 288 candidates, totalling 1440 fits
코드 설명
랜덤포레스트 모델의 성능을 향상하고자 하는 데이터 과학자, 머신 러닝 엔지니어 및 연구자입니다.
- Import necessary libraries: 하이퍼파라미터 조정을 위한 GridSearchCV와 모델 적합을 위한 RandomForestClassifier
- Define the parameter grid: 그리드를 위한 하이퍼파라미터를 지정하는 딕셔너리
- Initialize the classifier: RandomForestClassifier 인스턴스 생성
- Initialize GridSearchCV: 분류기, 하이퍼파라미터 그리드, 교차 검증 폴드, 병렬 작업 설정
- Fit the model: GridSearchCV를 사용하여 모델을 학습하여 최상의 하이퍼파라미터 Search
- Best parameters: 최상의 하이퍼파라미터 조합 추출
- Parameter grid explanation: 다양한 모델 구성을 탐색하기 위한 n_estimators, max_depth 등의 리스트와 범위
- Cross-validation: cv = 5는 모델 성능 평가를 위한 5번의 교차 검증
- Parallel execution: n_jobs=-1은 모든 프로세서를 사용하여 검색 속도를 높임
- Verbose output: 검색 프로세스 중에 더 자세한 로깅을 위한 옵션 지정 verbose=2
사이킷런을 사용한 랜덤포레스트 하이퍼파라미터 조정
랜덤포레스트 모델를 최대한 활용하여 더 정확하고 신뢰할 수 있는 예측을 이루려면 하이퍼파라미터를 조정하는 것이 중요합니다.
알고리즘
사이킷런에서 랜덤포레스트 모델의 하이퍼파라미터를 조정하여 더 나은 정확도와 성능을 얻는 체계적인 접근 방식입니다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# 검색할 하이퍼파라미터 그리드 정의
param_grid = {
'n_estimators': [100, 200, 300],
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth': [4, 6, 8, 10, None],
'criterion': ['gini', 'entropy']
}
# 랜덤포레스트 분류모델 초기화
rf = RandomForestClassifier(random_state=42)
# GridSearchCV 초기화
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2)
# GridSearchCV 적합
grid_search.fit(X_train, y_train)
# best 하이퍼파라미터 및 score 추출
best_parameters = grid_search.best_params_
best_score = grid_search.best_score_
print(f'Best Parameters: {best_parameters}')
print(f'Best Score: {best_score}')Demo 1
사이킷런의 GridSearchCV를 통해 랜덤 포레스트 튜닝을 마스터하여 모델 정확도를 높입니다.
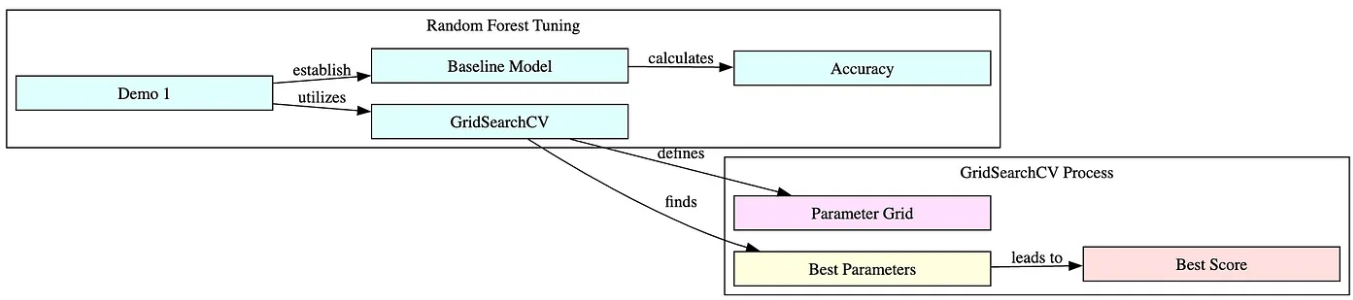
# Demo 1: 사이킷런을 사용한 랜덤포레스트의 하이퍼파라미터 조정 가이드
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.datasets import load_iris
# 데이터 셋 로드
iris = load_iris()
X = iris.data
y = iris.target
# 훈련 및 테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 기본 하이퍼파라미터를 가지는 랜덤포레스트 분류기 초기화
clf = RandomForestClassifier(random_state=42)
clf.fit(X_train, y_train)
baseline_accuracy = clf.score(X_test, y_test)
print(f'Baseline Model Accuracy: {baseline_accuracy}')
# 하이퍼파라미터 그리드 정의
param_grid = {
'n_estimators': [100, 200, 300],
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth' : [4, 6, 8, 10],
'criterion' :['gini', 'entropy']
}
# GridSearchCV 초기화
clf = GridSearchCV(RandomForestClassifier(random_state=42), param_grid, cv=5, verbose=True, n_jobs=-1)
# best 하이퍼파라미터를 찾기 위한 모델 적합
clf.fit(X_train, y_train)
# 이러한 하이퍼파라미터를 사용하여 최상의 하이퍼파라미터와 모델의 정확도 출력
print(f'Best parameters: {clf.best_params_}')
print(f'Best score: {clf.best_score_}')
# 이 데모는 Scikit-Learn의 GridSearchCV를 사용하여
# 랜덤포레스트 모델의 하이퍼파라미터를 조정하는 프로세스
# 비교를 위한 기준 모델로 시작하여 관심 있는 하이퍼파라미터에 대한
# 그리드를 정의하고 GridSearchCV를 사용하여 최적의 매개변수 조합 Search
# 기준 정확도, 발견된 최상의 하이퍼파라미터, 이러한 하이퍼파라미터를 사용한 모델의 정확도 출력
--------------------------------------------------------------------------------------------------------------------
Baseline Model Accuracy: 1.0
Fitting 5 folds for each of 72 candidates, totalling 360 fits
Best parameters: {'criterion': 'gini', 'max_depth': 4, 'max_features': 'auto', 'n_estimators': 100}
Best score: 0.9428571428571428Demo 2
# Demo 2: 사이킷런을 사용한 기본 랜덤포레스트 모델
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 데이터 셋 로드
iris = load_iris()
X = iris.data
y = iris.target
# 훈련 및 테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 기본 하이퍼파라미터를 가지는 랜덤포레스트 분류기 초기화
clf = RandomForestClassifier(n_estimators=100, random_state=42)
# 모델 적합
clf.fit(X_train, y_train)
# 모델 평가
accuracy = clf.score(X_test, y_test)
print(f'Model Accuracy: {accuracy}')
# 이 코드는 분류를 위해 사이킷런에서 랜덤포레스트를 기본적으로 적용하는 방법을 보여줍니다.
----------------------------------------------------------------------------------------------------
Model Accuracy: 1.0아래는 위의 기본 코드를 기반으로 랜덤포레스트를 마스터하고, GridSearchCV를 활용하며, 모델 정확도를 높이는 코드입니다.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.datasets import make_classification
# 합성 데이터 생성
X, y = make_classification(n_samples = 1000, n_features = 20, n_informative = 2, n_redundant = 0, random_state = 42)
# 데이터 세트를 훈련 세트와 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 하이퍼파라미터 그리드 정의
param_grid = {
'n_estimators': [50, 100, 200],
'max_features': ['auto', 'sqrt'],
'max_depth' : [None, 10, 20],
'criterion' :['gini', 'entropy']
}
# 랜덤포레스트 분류기 초기화
clf = RandomForestClassifier(random_state=42)
# GridSearchCV 초기화
grid_search = GridSearchCV(estimator=clf, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2)
# 모델 적합
grid_search.fit(X_train, y_train)
# Best 하이퍼파라미터
best_params = grid_search.best_params_
# 시각화를 위한 데이터 생성
n_estimators_data = [param['n_estimators'] for param in grid_search.cv_results_['params']]
mean_test_scores = grid_search.cv_results_['mean_test_score']
# 시각화
fig, ax = plt.subplots(1, 2, figsize=(14, 5))
# n_estimators 대 mean_test_scores에 대한 막대 그래프
ax[0].bar(n_estimators_data, mean_test_scores, color='#99ff99')
ax[0].set_xlabel('Number of Estimators')
ax[0].set_ylabel('Mean Test Score')
ax[0].set_title('Performance of Different Number of Estimators')
# n_estimators 대 mean_test_scores에 대한 산점도
ax[1].scatter(n_estimators_data, mean_test_scores, color='#9999ff')
ax[1].vlines([50, 100, 200], ymin=min(mean_test_scores), ymax=max(mean_test_scores), colors='r', linestyles='dashed', label='25%, 50%, 75% Quantiles')
ax[1].set_xlabel('Number of Estimators')
ax[1].set_ylabel('Mean Test Score')
ax[1].set_title('Scatter Plot of Estimators Performance')
ax[1].legend()
plt.suptitle('Random Forest Parameter Tuning Visualization')
plt.tight_layout()
plt.show()
# 관련성: 이 함수는 사이킷런의 GridSearchCV를 사용하여 랜덤포레스트의 하이퍼파라미터를 조정하는 방법을 보여주고 다양한 수의 분류기의 성능을 시각화합니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------
Fitting 5 folds for each of 36 candidates, totalling 180 fits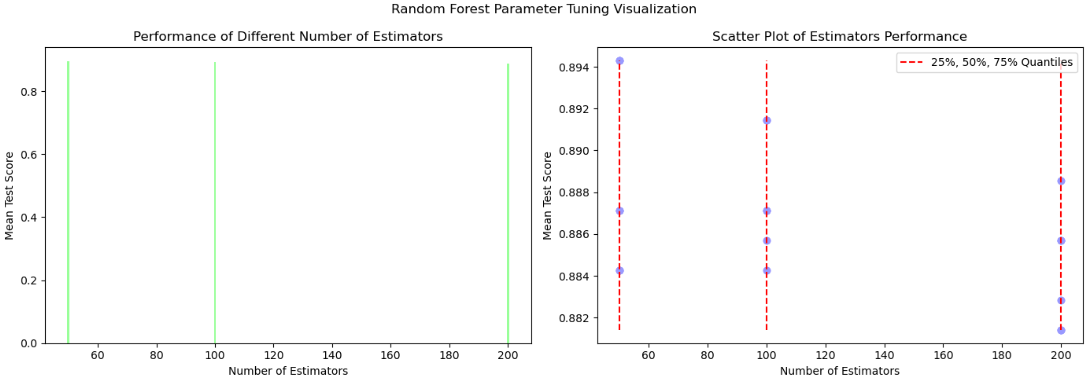
Case Study
대도시 지역의 주택 가격을 예측하는 모델의 정확도를 개선하는 과제를 받았다고 가정해 보겠습니다. 데이터 세트에는 침실 수, 면적, 주변 범죄율, 학교와의 근접성과 같은 특징이 있습니다.
견고성과 비선형 데이터를 처리하는 기능 때문에 랜덤 포레스트 알고리즘을 사용하기로 결정했습니다. 사이킷런의 기본 랜덤포레스트 하이퍼파라미터를 사용하여 초기 모델을 학습하였습니다. 하이퍼파라미터를 조정하면 모델의 정확도를 크게 개선할 수 있습니다.
GridSearchCV를 사용하여 n_estimators, max_depth, min_samples_split, min_samples_leaf와 같은 주요 하이퍼파라미터에 대한 다양한 값을 체계적으로 탐색했습니다. 여러 번 반복 후 GridSearchCV는 예측 오류를 최소화하는 하이퍼파라미터 집합을 식별했습니다.
그런 다음 최적화된 랜덤포레스트 모델을 배포하여 주택 가격 예측을 눈에 띄게 개선하여 실제 시장 가치와 거의 일치한 결과를 얻었습니다.
Pitfalls
- Overfitting: 교차 검증 없이 하이퍼파라미터를 조정하면 훈련 데이터에서는 좋은 성능을 보이지만 테스트 데이터에서는 성능이 떨어집니다.
- Computation Time: 대규모 하이퍼파라미터 그리드와 데이터 세트에 GridSearchCV를 사용하면 계산 비용이 많이 들고 시간이 오래 걸릴 수 있습니다.
- Parameter Interdependence: 일부 하이퍼파라미터는 명확하지 않은 방식으로 상호 작용하여 효과를 분리하기 어려울 수 있습니다.
- Default Parameter Reliance: 기본 하이퍼파라미터에만 의존하면 모델 성능이 최적이 아닐 수 있습니다.
- Local Optima: GridSearchCV는 하이퍼파라미터에 대한 전역적 최적이 아닌 지역적 최적을 찾을 수 있습니다.
생산을 위한 팁
- Parallel Processing: GridSearchCV의 n_jobs을 활용하여 병렬 계산을 실행하고 하이퍼파라미터 검색 시간을 줄입니다.
- Randomized Search: 하이퍼파라미터 공간에서 GridSearchCV보다는 덜 포괄적인 검색이지만, 더 빠른 RandomizedSearchCV를 사용하는 것도 고려해야 합니다.
- Incremental Tuning: 광범위한 검색으로 시작하여 이전 결과에 따라 검색 공간을 반복적으로 세분화하여 최적의 매개변수를 보다 효율적으로 찾습니다.
- Validation Set: 별도의 검증 세트 또는 교차 검증을 사용하여 하이퍼파라미터 효과를 평가하고 과적합을 방지합니다.
- Feature Importance: 변수 중요도를 분석하여 데이터의 차원을 잠재적으로 줄여 모델 성능을 개선하고 학습 시간을 줄일 수 있습니다.
Demo 3

# Demo 3: GridSearchCV를 사용하여 랜덤포레스트 하이퍼파라미터 조정
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
# 데이터 로드
digits = load_digits()
X = digits.data
y = digits.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 하이퍼파라미터 그리드 정의
param_grid = {
'n_estimators': [50, 100, 200],
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth' : [4,6,8,10],
'criterion' :['gini', 'entropy']
}
# GridSearchCV 초기화
clf = GridSearchCV(RandomForestClassifier(random_state=42), param_grid, cv=5, verbose=True, n_jobs=-1)
# 모델 적합
clf.fit(X_train, y_train)
# Best parameters and score
print(f'Best parameters: {clf.best_params_}')
print(f'Best score: {clf.best_score_}')
# 이 코드는 GridSearchCV를 사용하여 랜덤포레스트 모델에 가장 적합한 하이퍼파라미터를 찾는 방법을 보여줍니다.
--------------------------------------------------------------------------------------------------------------
Fitting 5 folds for each of 72 candidates, totalling 360 fits
Best parameters: {'criterion': 'entropy', 'max_depth': 10, 'max_features': 'log2', 'n_estimators': 200}
Best score: 0.9749419279907086결론
사이킷런을 사용하여 랜덤포레스트에서 조정 하이퍼파라미터를 탐색하는 포괄적인 여정을 시작하여 하이퍼매개변수의 최적화를 시도하였습니다.
하이퍼파라미터 그리드를 정의하는 초기 단계부터 GridSearchCV를 사용하는 프로세스까지 각 단계는 모델의 정확도를 높이는 데 중요한 역할을 했습니다.
실용적인 가이드뿐만 아니라 ‘n_estimators’, ‘max_depth’, ‘min_samples_split’과 같은 다양한 하이퍼파라미터의 영향에 대해 더 깊게 이해하였습니다.
최적화로 가는 길에는 과적합 및 계산 요구 사항과 같은 과제가 많지만 모델 성능 측면에서는 반드시 필요하다는 것을 알았습니다. 앞으로 이러한 통찰력과 전략을 모델 적합 프로젝트에 적용하여 랜덤포레스트와 사이킷런의 힘을 활용하여 보다 정확하고 신뢰할 수 있는 예측을 달성할 수 있으리라 봅니다.
학습과 개선의 여정은 지속될 것이며, 더욱 탐구하고, 대담하게 실험하고자 합니다.
# 필수 라이브러리 로드
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# 데이터 로드
iris = load_iris()
X = iris.data
y = iris.target
# 데이터 세트를 훈련과 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 랜덤포레스트 분류기 초기화
rf = RandomForestClassifier(random_state=42)
# 하이퍼파라미터 그리드 정의
param_grid = {
'n_estimators': [10, 50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# GridSearchCV 초기화
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2)
# 모델 적합
grid_search.fit(X_train, y_train)
# best parameters 출력
print('Best parameters found:\n', grid_search.best_params_)
# 테스트 데이터를 통한 예측
y_pred = grid_search.predict(X_test)
# 정확도 계산
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
# 이 코드는 GridSearchCV를 RandomForestClassifier와 함께 사용하여 최적의 하이퍼파라미터를 찾고 모델 정확도를 개선하는 방법을 보여줍니다.
---------------------------------------------------------------------------------------------------------------------------------------------
Fitting 5 folds for each of 144 candidates, totalling 720 fits
Best parameters found:
{'max_depth': None, 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 100}
Accuracy: 1.0
Demo 4
# Demo 4: GridSearchCV 및 Pipeline을 사용한 랜덤포레스트 조정
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 합성 데이터 생성
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=42)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# pipeline 생성
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', RandomForestClassifier(random_state=42))
])
# 하이퍼파라미터 그리드 정의
param_grid = {
'classifier__n_estimators': [100, 200],
'classifier__max_features': ['auto', 'sqrt'],
'classifier__max_depth': [None, 10, 20],
'classifier__criterion': ['gini', 'entropy']
}
# GridSearchCV 초기화
clf = GridSearchCV(pipeline, param_grid, cv=5, verbose=True, n_jobs=-1)
# 모델 적합
clf.fit(X_train, y_train)
# Best parameters and score
print(f'Best parameters: {clf.best_params_}')
print(f'Best score: {clf.best_score_}')
# 이 예제는 파이프라인에서 전처리 단계를 거쳐 랜덤포레스트 모델을 조정하는 GridSearchCV의 보다 고급 활용 방법을 보여줍니다.
------------------------------------------------------------------------------------------------------------------------------
Fitting 5 folds for each of 24 candidates, totalling 120 fits
Best parameters: {'classifier__criterion': 'entropy', 'classifier__max_depth': None, 'classifier__max_features': 'auto', 'classifier__n_estimators': 100}
Best score: 0.908https://medium.com/@Doug-Creates/tuning-random-forest-parameters-with-scikit-learn-b53cbc602cd0