데이터 탐색 등 데이터를 다룰 때, 체계적인 탐색 및 검증 프로세스는 인사이트를 발굴하고 데이터 무결성을 보장하는 데 매우 중요합니다. 이번 포스팅에서는 Pandas와 Seaborn을 사용하여 도서 데이터를 탐색, 검증 및 요약해 보겠습니다.
1) 데이터 유형 검토, 2) 범주형 및 수치형 데이터 처리, 3) 시각화 방법을 알아보겠습니다. 아래 데이터를 다운로드하고 다음 코드를 사용하여 Python 환경에 로드하면서 따라할 수 있습니다.
import pandas as pd
books = pd.read_csv('D:/clean_books.csv')1단계: 초기 탐색
첫 번째 몇 행 보기
.head()를 사용하여 데이터 구조를 빠르게 살펴보겠습니다.
books.head()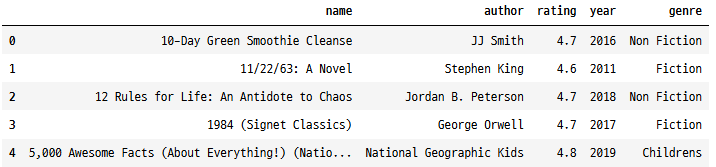
데이터 세트 개요
.info()를 사용하여 열 이름, null이 아닌 데이터 개수, 데이터 유형 등 데이터 세트에 대한 필수적인 기본 세부 정보를 확인합니다.
books.info()
----------------------------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 350 entries, 0 to 349
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 350 non-null object
1 author 350 non-null object
2 rating 350 non-null float64
3 year 350 non-null int64
4 genre 350 non-null object
dtypes: float64(1), int64(1), object(3)
memory usage: 13.8+ KB데이터 유형 확인
모든 열의 데이터 유형을 확인합니다.
books.dtypes
----------------------------------------------------------------
name object
author object
rating float64
year int64
genre object
dtype: object2단계: 상세 탐색
범주형 열
그룹 간 통계량 사용하여 범주형 데이터를 분석합니다. 예를 들어, 각 장르의 평균 rating과 year를 계산합니다.
books.groupby("genre")[["rating", "year"]].mean()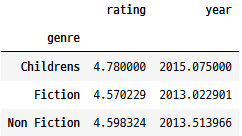
수치 요약
.describe()를 사용하여 숫자 열에 대한 요약 통계를 확인합니다.
books.describe()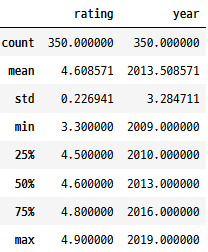
데이터 유형 업데이트
‘year’ 열의 데이터 유형이 올바른지 확인합니다.
books["year"] = books["year"].astype(int)
books.dtypes
----------------------------------------------------------------------
name object
author object
rating float64
year int32
genre object
dtype: object3단계: 수치 데이터 시각화
등급에 대한 히스토그램
‘rating’ 분포를 시각화 해보겠습니다.
import seaborn as sns
import matplotlib.pyplot as plt
sns.histplot(books, x = "rating")
plt.show()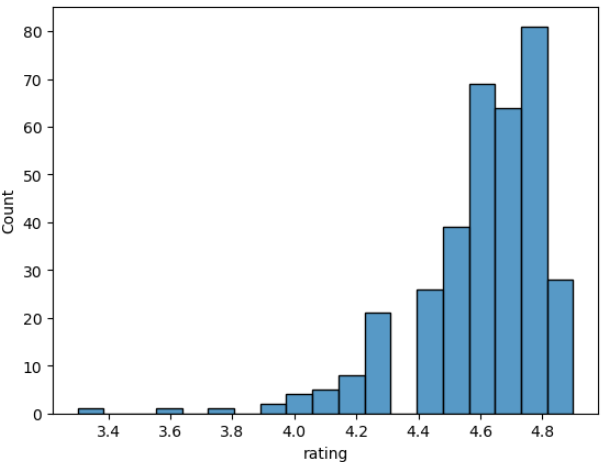
연도 및 장르별 상자 그림
출판 연도 분포를 시각화 해보겠습니다.
sns.boxplot(data=books, x="year")
plt.show()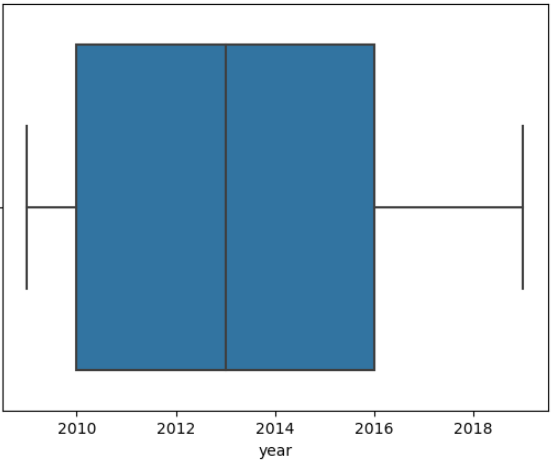
장르별 출판 연도를 비교해보겠습니다.
sns.boxplot(data=books, x="year", y="genre")
plt.show()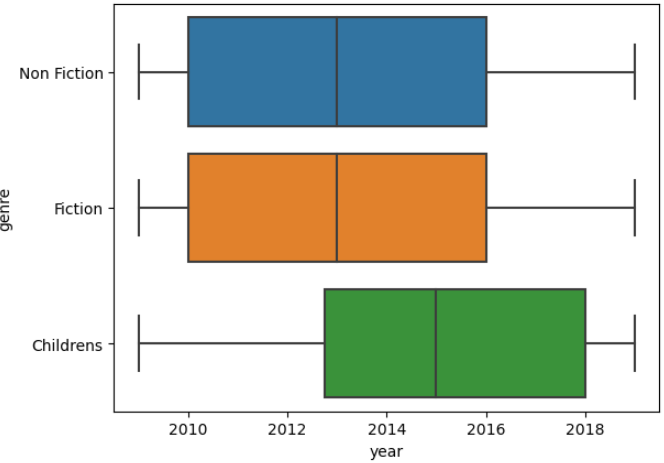
4단계: 데이터 검증
데이터 유형 검증
열 데이터 유형을 다시 확인합니다.
books.info()
books.dtypes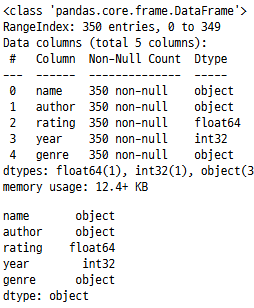
범주형 데이터 검증
유효한 장르를 확인하고 그에 따라 행을 조건검색합니다.
valid_genres = ["Fiction", "Non Fiction"]
books[books["genre"].isin(valid_genres)].head()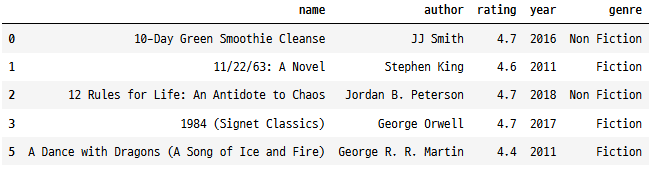
잘못된 장르가 있는 행을 식별합니다.
~books["genre"].isin(valid_genres)
---------------------------------------------------------------
0 False
1 False
2 False
3 False
4 True
...
345 False
346 False
347 False
348 False
349 True
Name: genre, Length: 350, dtype: bool수치 데이터 검증
숫자형 열을 검사합니다.
books.select_dtypes("number").head()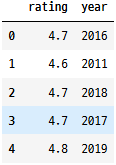
출판년도 범위를 확인합니다.
books["year"].min(), books["year"].max()
------------------------------------------------------
(2009, 2019)
5단계: 데이터 요약
집계
그룹화되지 않은 데이터에 대한 집계 통계량을 생성합니다.
books[["rating", "year"]].agg(["mean", "std"])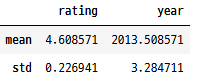
열별로 특정 집계 적용
books.agg({"rating": ["mean", "std"], "year": ["median"]})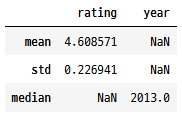
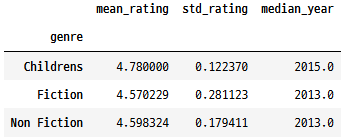
그룹화된 집계
그룹화된 데이터에 대해 명명된 요약 열을 생성합니다.
books.groupby("genre").agg(
mean_rating=("rating", "mean"),
std_rating=("rating", "std"),
median_year=("year", "median")
)
범주형 데이터 시각화
막대 그래프를 사용하여 장르별 평점을 비교합니다.
sns.barplot(data=books, x="genre", y="rating", palette="viridis")
plt.show()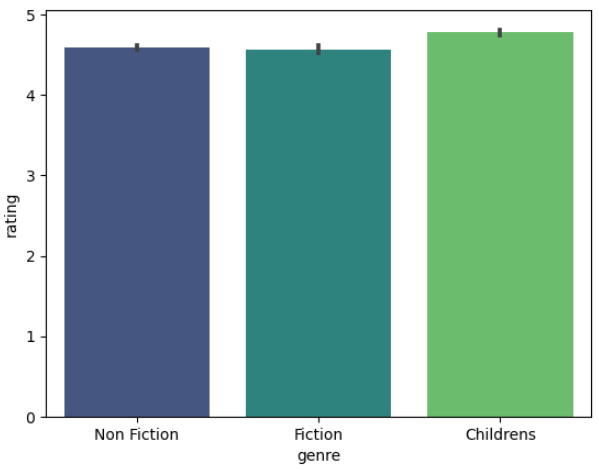
결론
탐색, 검증, 시각화 기술을 결합하면 데이터 품질을 보장하는 동시에 귀중한 인사이트를 얻을 수 있습니다. 이러한 방법은 효과적인 데이터 분석 및 모델링을 위한 탄탄한 기반을 마련합니다. 감사합니다.