이번 포스팅에서는 파이썬 데이터 전처리 방법 중 매우 기본적인 내용에 대해서 알아보겠습니다.
예제를 위한 기초 데이터를 생성한 후 필요 라이브러이 가져오기, 결측치 처리, 대소문자가 섞여 있는 텍스트 데이터 표준화 방법, 통화 형식을 통일시키는 방법에 대해 순차적으로 알아 보겠습니다.
기초 데이터 생성
기초 데이터를 생성하여 시작해 보겠습니다.
import pandas as pd
import numpy as np
# 정제가 필요한 데이터가 포함된 샘플 데이터프레임
data = pd.DataFrame({
'Name': ['John', 'Alice', 'Robert', 'Jane', 'Erik'],
'Age': [25, '31', np.nan, 'unknown', 29],
'Income': ['55000', '72000', '$63,000', '45,000', '78000'],
'Email': ['john@example.com', 'alice@gmail.com', 'robert@com', 'jane@gmail', 'erik@outlook.com']
})
data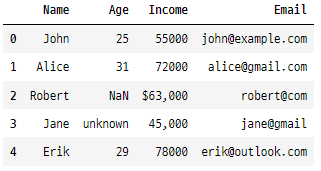
위의 코드는 다양한 데이터 전처리 문제를 포함하는 샘플 데이터 세트를 정의하고, 출력합니다.
라이브러리 가져오기
Pandas와 NumPy 패키지를 사용하기 위해 필요한 라이브러리를 가져올 것입니다.
import pandas as pd
import numpy as np위 라이브러리는 데이터를 조작하고 정리하는 데 매우 유용합니다.
결측값 처리
데이터를 보면 ‘Age’ 열에 결측치와 숫자가 아닌 값이 포함되어 있습니다. ‘Age’ 열의 누락된 값을 처리하기 위해 중간값(median)으로 채우고 숫자가 아닌 값을 NaN으로 변환하는 함수를 작성합니다.
# 'Age' 열의 결측치를 처리하는 함수
def clean_age(df):
df['Age'] = pd.to_numeric(df['Age'], errors = 'coerce') # 숫자가 아닌 값을 NaN으로 변환
df['Age'].fillna(df['Age'].median(), inplace = True) # 결측치를 중앙값으로 채우기위에서 생성한 clean_age 함수는 pd.to_numeric 함수를 사용하여 ‘Age’ 열을 숫자로 변환합니다. ‘coerce’ 옵션을 사용하여 숫자가 아닌 값을 NaN으로 변환합니다.
그런 다음 결측치를 ‘Age’의 중앙값으로 채웁니다(결측치 대체하는 함수 .fillna에 대한 자세한 내용은 fillna 함수 이해하기 포스팅 글을 참고하시면 됩니다.).
이제 이 함수를 데이터 세트에 적용하고 정리된 데이터를 표시해 보겠습니다.
# 'Age' 열 정제
clean_age(data)
data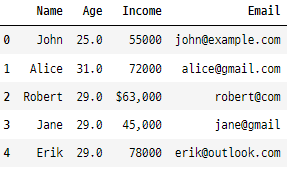
이 단계에서는 결측치를 처리하고 숫자가 아닌 데이터를 일관된 형식으로 변환하는 데이터 전처리 과정을 보여줍니다.
일관되지 않은 텍스트 데이터 처리
‘Name’ 열에 일관되지 않은 대소문자가 있는 텍스트 데이터가 포함되어 있습니다. ‘Name’ 열의 모든 텍스트를 소문자로 변환하는 함수를 작성합니다.
# 'Name' 열의 텍스트 대소문자를 모두 소문자로 변환하는 함수
def standardize_text_case(df, column):
df[column] = df[column].str.lower()standardize_text_case 함수는 .str.lower() 메서드를 사용하여 지정된 열의 모든 텍스트를 소문자로 변환합니다. 이제 이 함수를 데이터 세트에 적용하고 정리된 데이터를 표시해 보겠습니다.
# 'Name' 열 정제
standardize_text_case(data, 'Name')
data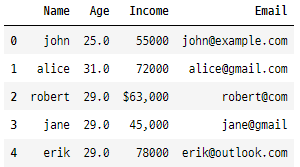
이 단계에서는 일관되지 않은 텍스트 대소문자 문제를 해결해 줍니다.
통화 형식 표준화
‘Income’ 열에는 다양한 형식의 소득 데이터가 들어 있습니다. ‘Income’ 열의 통화 형식을 표준화하는 함수를 작성합니다.
# 'Income' 열의 통화 형식을 일관성 있게 변환하는 함수
def standardize_currency_format(df, column):
df[column] = df[column].str.replace(r'[^\d.]', '', regex T ue).astype(float)standardize_currency_format 함수는 정규표현식(regex)을 사용하여 ‘Income’ 열에서 숫자나 기간이 아닌 모든 문자를 제거합니다. 그런 다음 정리된 값을 부동 소수점 숫자 형식으로 변환합니다. 이 함수를 데이터 세트에 적용하고 정리된 데이터를 표시해 보겠습니다.
# 'Income' 열 정제
standardize_currency_format(data, 'Income')
data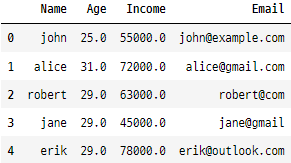
이 단계에서는 일관되지 않은 통화 형식 문제를 해결하고 모든 소득 데이터가 표준화된 숫자 형식을 갖도록 변환합니다.
결론
이상으로 파이썬 데이터 전처리 과정의 기초 방법에 대해서 알아보았습니다.