이번 포스팅에서는 판다스 데이터프레임에서 열 값 매핑 방법에 대해서 알아보겠습니다. 열 값 매핑이란 열의 특정 값을 다른 값으로 대체하는 것을 의미하며, 일반적으로 데이터 정리 및 변환에 사용됩니다. 열 값 매핑이 유용한 사례는 많이 있습니다. 다음은 몇 가지 일반적인 사용 사례입니다.
- 열의 특정 문자열 값을 숫자에 매핑합니다.
예를 들어, “Male”과 “Female”을 각각 0과 1에 매핑하여 머신 러닝 알고리즘에서 학습과 예측을 용이하게 합니다. - 약어를 전체 이름으로 대체합니다.
예를 들어, “USA”와 “UK”를 “United States”와 “United Kingdom”으로 대체하여 데이터를 더 읽기 쉽게 만듭니다. - 철자가 틀린 단어를 올바른 철자로 대체하여 수정합니다.
예를 들어, “Cocacola”를 “Coca-Cola”로 대체하여 통계 및 분석에서 오류를 방지합니다.
map() 함수 활용
map() 함수는 가장 간단하고 직접적인 방법입니다. 예를 들어, 다음 사례에서 성별 값을 0과 1로 매핑합니다.
import pandas as pd
# 매핑 전
mapDf = pd.DataFrame({
"name": ["Alice", "Bob", "Charlie", "David", "Eva", "Frank"],
"sex": ["female", "male", "male", "male", "female", "male"],
"age": [23, 34, 29, 42, 25, 31],
})
mapDf<매핑 전>

<매핑 후>

Factorize Mapping
map 함수를 사용하여 열 값을 매핑하는 것이 가장 간단한 방법입니다. 그러나 열에 여러 개의 고유한 값이 있는 경우 하나씩 매핑하는 것은 번거로울 수 있습니다. 예를 들어, 다음 예의 grade 열의 경우 두 개의 값만 있는 sex 열과 달리 가능한 값이 더 많습니다.
이 경우에는 인수분해 방법을 사용하여 매핑을 수행할 수 있습니다.
import pandas as pd
# 매핑 전
fatorizeDf = pd.DataFrame({
"name": ["John", "Emily", "Michael", "Sarah", "James", "Olivia"],
"sex": ["male", "female", "male", "female", "male", "female"],
"grade": ["A", "B", "C", "A", "B", "C"],
})
fatorizeDf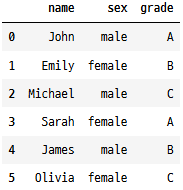
fatorizeDf.sex = fatorizeDf.sex.factorize()[0]
fatorizeDf.grade = fatorizeDf.grade.factorize()[0]
# 매핑 후
fatorizeDf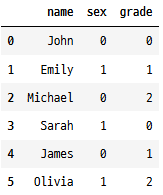
factorize 함수는 두 개의 요소가 있는 튜플을 반환합니다. 첫 번째 요소는 매핑된 값을 나타내는 숫자 배열이고, 두 번째 요소는 인덱스 유형으로, 인덱스 값은 열의 고유한 값에 해당합니다.
fatorizeDf.grade.factorize()
---------------------------------------------------------------------------------
(array([0, 1, 2, 0, 1, 2], dtype=int64), Int64Index([0, 1, 2], dtype='int64'))따라서 코드는 factorize()[0]을 사용합니다.
‘grade’ 열의 경우 매핑 후 값을 이진화하려면 서로 다른 수준을 나타내는 네 가지 값이 있습니다. 실패(F)와 통과(P)의 두 가지 범주만 원하는 경우 코드는 다음과 같습니다.
fatorizeDf.grade = fatorizeDf.grade.factorize()[0]
fatorizeDf.grade = (fatorizeDf.grade == 2).astype("int")
fatorizeDf
A와 B는 0에 매핑되고, C는 1에 매핑됩니다.
이상으로 판다스 데이터프레임에서 열 값 매핑 방법에 대해서 알아보았습니다.