이번 포스팅에서는 판다스 패키지를 활용한 데이터 필터링 방법에 대해서 알아보겠습니다.
Python을 사용한 데이터 분석에서 다양한 조건, 차원 및 조합을 기반으로 데이터를 추출하고 필터링하는 것은 가장 일반적인 작업 중 하나입니다. 이를 통해 데이터 분석 및 통찰력에 필요한 특정 데이터를 추출하는 데 도움이 됩니다.
이번 포스팅에서는 고급적이고 일반적으로 자주 사용되는 데이터 추출 및 필터링 방법을 요약했습니다. 이를 위해 사용한 데이터 세트는 sklearn의 Boston 데이터입니다.
실습 데이터 프레임 생성
import pandas as pd
import numpy as np
dataUrl = "http://lib.stat.cmu.edu/datasets/boston"
rawDf = pd.read_csv(dataUrl, sep = "\s+", skiprows = 22, header = None)
rawDfTemp1 = rawDf[rawDf.index % 2 == 0].reset_index().drop('index', axis = 1)
rawDfTemp2 = rawDf[rawDf.index % 2 != 0].reset_index().drop('index', axis = 1)
rawDfTem3 = pd.concat([rawDfTemp1, rawDfTemp2], axis =1)
rawDfFinal = rawDfTem3.dropna(axis = 1)
rawDfFinal.columns = ['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT','MEDV']
rawDfFinal.head()
- CRIM: 도시별 1인당 범죄율
- ZN: 25,000제곱피트 이상의 면적으로 지정된 주거용 토지의 비율
- INDUS: 도시당 비소매업 면적 비율
- CHAS: Charles River 더미 변수(= 지역이 강의 경계를 이루는 경우 1, 그렇지 않은 경우 0)
- NOX: 일산화질소 농도(1000만분의 1)
- RM: 주택당 평균 방 개수
- AGE: 1940년 이전에 건설된 소유자 거주 단위의 비율
- DIS: 보스턴 취업 센터 5곳까지의 가중 거리
- RAD: 방사형 고속도로 접근성 지수
- TAX: $10,000당 전체 가치 재산세율
- PTRATIO: 도시별 교사-학생 비율
- B: 1000(Bk – 0.63)^2 여기서 Bk는 도시별 흑인 비율입니다.
- LSTAT: % lower status of the population
- MEDV: 소유자가 거주하는 주택의 중간 가치는 1000달러대입니다.
[]를 사용한 데이터 필터링
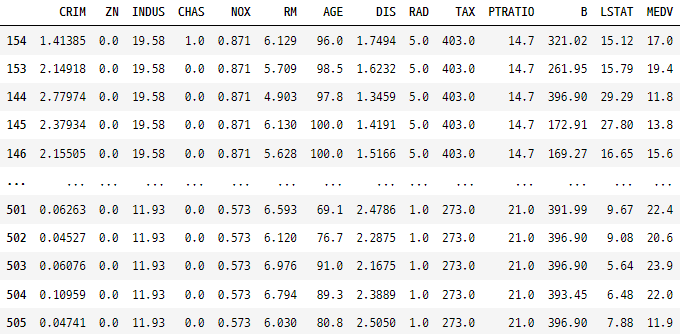
첫 번째 방법은 가장 빠르고 편리한 방법입니다. 데이터프레임의 [ ] 내부에 필터링 조건이나 조건 조합을 직접 작성하는 것입니다. 예를 들어, NOX 변수가 평균 값보다 큰 모든 데이터를 필터링한 다음 결과를 NOX를 기준으로 내림차순으로 정렬하려면 다음과 같이 수행하면 됩니다.
rawDfFinal[rawDfFinal['NOX'] > rawDfFinal['NOX'].mean()].sort_values(by = 'NOX', ascending = False)
&와 |와 같은 논리 연산자를 사용한 조합 조건을 사용할 수도 있습니다. 예를 들어, 위의 조건 외에도 CHAS가 1이어야 한다는 조건을 추가할 수 있습니다. 단, 논리 연산자로 구분된 조건은 괄호로 묶어야 합니다.
rawDfFinal[(rawDfFinal['NOX'] > rawDfFinal['NOX'].mean()) & (rawDfFinal['CHAS'] == 1)].sort_values(by = 'NOX', ascending = False)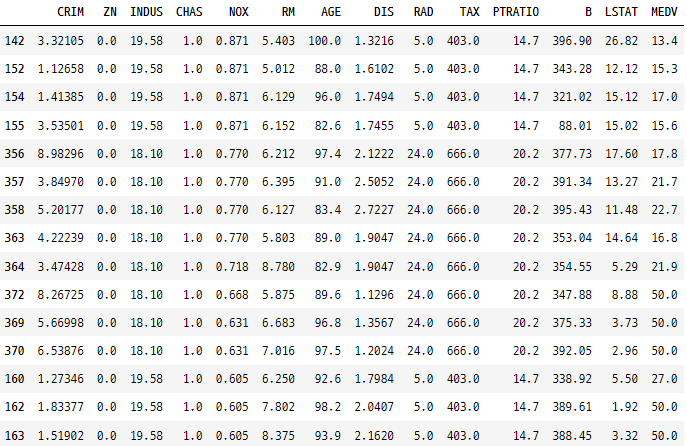
loc/iloc를 사용한 데이터 필터링
[ ]를 사용하는 것 외에도 loc와 iloc은 아마도 가장 일반적으로 사용되는 두 가지 쿼리 방법입니다. loc는 레이블(열 이름과 행 인덱스)로 데이터에 액세스하는 반면, iloc는 숫자 인덱스로 데이터에 액세스합니다.
두 방법 모두 단일 값 액세스 또는 슬라이싱 쿼리를 지원합니다. [ ]와 같은 조건으로 데이터를 필터링하는 것 외에도 loc는 반환할 열을 지정하여 행 및 열 차원에서 필터링할 수 있습니다.
예를 들어, 아래는 조건에 따라 데이터를 필터링하고 특정 열을 선택한 다음 결과를 할당하는 코드입니다.
rawDfFinal.loc[(rawDfFinal['NOX'] > rawDfFinal['NOX'].mean()), ['CHAS']] = 2
rawDfFinal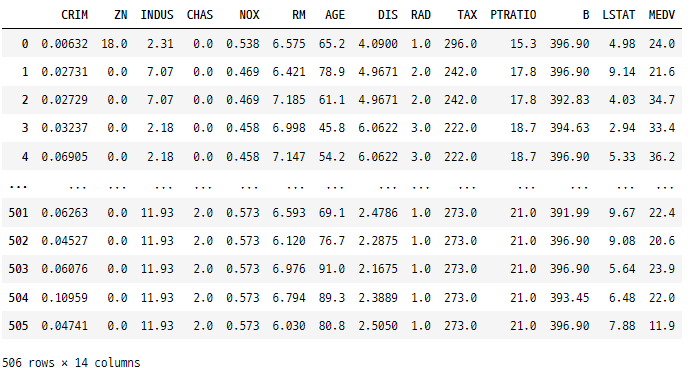
isin을 사용한 데이터 필터링
위에서 우리는 <, >, ==, !=와 같은 필터링 조건을 사용했는데, 이는 범위를 정의하는 방법입니다. 그러나 종종 특정 값을 타겟팅해야 하는 경우도 있습니다.
그런 경우 isin을 사용할 수 있습니다. 예를 들어, NOX의 값을 0.538, 0.713 또는 0.437로만 제한하려면 아래와 같이 수행하면 됩니다.
rawDfFinal.loc[rawDfFinal['NOX'].isin([0.538,0.713,0.437]),:].head()
필터링 조건 앞에 ~ 기호를 추가하여 역 연산을 수행할 수도 있습니다. 예를 들어, NOX 값이 0.538, 0.713 또는 0.437이 아닌 행을 필터링하려면 아래와 같이 수행하면 됩니다.
rawDfFinal.loc[~rawDfFinal['NOX'].isin([0.538,0.713,0.437]),:].head()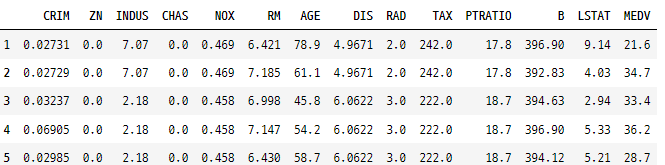
str.contains을 사용한 데이터 필터링
지금까지 설명한 필터링위의 모든 예는 수치적 비교에 기반한 필터링 조건을 포함합니다. 수치적 기준 외에도 문자열 쿼리에 대한 요구 사항도 있습니다. 판다스에서 퍼지 문자열 매칭을 수행하려면 SQL의 LIKE와 다소 유사한 .str.contains()를 사용할 수 있습니다.
실습 데이터 수정
위에서 설명한 필터링 조건을 설명하기 위해 가상의 실습 데이터를 생성합니다.
from faker import Faker
# Faker 객체 생성
fake = Faker()
# 50만건의 Fake Data 데이터 프레임 생성하기
fakerDf = pd.DataFrame(
{
'name':[fake.name() for i in range(506)]
}
)
rawDfFinal = pd.concat([rawDfFinal, fakerDf], axis = 1)
rawDfFinal
아래의 코드는 위에서 생성한 데이터프레임에서 따옴표 안에 | 논리 연산자를 사용하여 사람의 이름에 “Amanda” 또는 “James”가 포함된 데이터를 필터링하는 예입니다.
rawDfFinal.loc[rawDfFinal['name'].str.contains('Amanda|James'),:].head()
where 또는 mask를 사용한 데이터 필터링
SQL에서 WHERE 절은 특정 조건을 만족하는 행을 필터링하는 데 사용된다는 것을 알고 있습니다. pandas에서 where도 필터링을 수행하지만 사용법은 약간 다릅니다.
pandas의 where 메서드는 부울 유형의 조건을 허용합니다. 행이 일치 조건을 만족하지 않으면 기본값 NaN 또는 다른 지정된 값이 할당됩니다. 예를 들어, RAD를 3과 같은 조건으로 사용하면 cond는 부울 Series를 나타냅니다. 3이 아닌 값에는 기본 NaN 값이 할당됩니다.
cond = rawDfFinal['RAD'] == 3
rawDfFinal['RAD'].where(cond, inplace=True)
rawDfFinal.head()
다른 것을 사용하여 지정된 값을 할당할 수도 있습니다.
cond = rawDfFinal['RAD'] == 3
rawDfFinal['RAD'].where(cond, other = 9999, inplace=True)
rawDfFinal.head()
쿼리를 사용한 데이터 필터링
이것은 데이터를 필터링하는 매우 우아한 방법입니다. 모든 필터링 작업은 ” 내에서 완료됩니다.
# Normal way
rawDfFinal[rawDfFinal.PTRATIO > 18]
# Query way
rawDfFinal.query('PTRATIO > 18')
위의 두 가지 방법은 동일한 결과를 얻습니다. 예를 들어, 더 복잡한 시나리오의 경우 위에서 설명한 대로 str.contains를 사용하여 조건을 결합합니다. 조건에 ‘’가 포함된 경우에는 “”로 묶어야 합니다.
rawDfFinal.query("name.str.contains('Tiffany') & PTRATIO >= 21")
query에서는 @를 사용하여 변수를 설정할 수도 있습니다.
name = 'James'
rawDfFinal.query("name.str.contains(@name)")
필터 사용
filter는 또 다른 고유한 필터링 기능입니다. 특정 데이터를 필터링하는 것과 달리 filter는 특정 행이나 열을 선택합니다. 세 가지 필터링 방법을 지원합니다.
items: 고정된 열 이름regex: 정규 표현식like: 퍼지 쿼리
axis: 행 인덱스 또는 열 이름을 쿼리하는지 여부를 제어합니다.
rawDfFinal.filter(items = ['RM', 'AGE']) # RM 과 AGE 열만 keep 하기 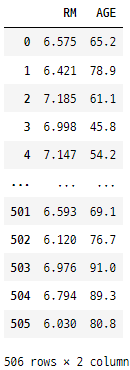
rawDfFinal.filter(regex = 'T', axis = 1) # 대문자 T 를 포함하는 열 선택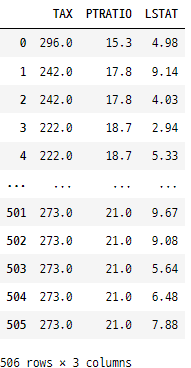
rawDfFinal.filter(like = '2', axis = 0) # 2가 포함된 인덱스 행만 keep
데이터 필터링을 위한 any 또는 all 사용
any 메서드는 적어도 하나의 값이 True이면 결과도 True임을 의미합니다. all 메서드는 결과가 True가 되려면 모든 값이 True여야 합니다.
rawDfFinal['DIS'].all()
-------------------------------
True‘DIS’ 열의 모든 값이 null이 아니기 때문에 True를 반환합니다. any와 all은 일반적으로 각 열에서 누락된 값을 확인하는 등의 다른 작업과 함께 사용됩니다.
rawDfFinal.isnull().any(axis = 0)
---------------------------------------------
CRIM False
ZN False
INDUS False
CHAS False
NOX False
RM False
AGE False
DIS False
RAD False
TAX False
PTRATIO False
B False
LSTAT False
MEDV False
name False
dtype: bool예를 들어, 누락된 값이 포함된 행의 수를 찾는 경우입니다.
rawDfFinal.isnull().any(axis = 1).sum()
----------------------------------------------------
0결론
이상으로 특정 조건에 맞는 데이터를 선택하는 필터링 방법에 대해서 알아보았습니다. 데이터 필터링 방법은 데이터 분석을 위한 전처리 시 필수적으로 수행해야 합니다. 다양한 데이터를 가지고, 많은 연습을 하여 습득할 수 있도록 노력해야 합니다.
감사합니다.