범주형 변수를 인코딩하는 방법은 One-hot encoding, Dummy encoding, Effect encoding, Label encoding, Ordinal encoding, Count encoding, Binary encoding 등 크게 7가지가 있습니다. 보다 자세한 설명은 범주형 데이터 인코딩하기 포스팅 글을 참고하세요.
이번 포스팅에서는 이들 7가지 인코딩 기술에 대해 알아보겠습니다.
7가지 범주형 데이터 인코딩 기술
One-hot encoding
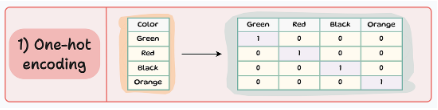
각 범주는 0과 1로 구성된 이진 벡터로 표현됩니다. 각 범주는 자체 바이너리 특징을 가지며 한 번에 하나만 “hot”(1로 설정)되어 해당 범주에 속함을 나타냅니다. 유니크한 범주형 레이블 수와 one-hot encoding된 변수의 수는 같습니다(위의 예시 그림에서는 4개로 같습니다.).
Dummy encoding

One-hot encoding과 동일하지만 단계 하나가 더 있습니다. One-hot encoding 후, 랜덤하게 하나의 변수를 삭제합니다. 이는 더미 변수 함정을 피하기 위해 수행됩니다(이에 대한 자세한 설명은 데이터 과학에서의 8가지 치명적(그러나 명확하지 않은) 함정과 주의 사항 포스팅글을 참고하시면 됩니다.).
유니크한 범주형 레이블 수보다 Dummy encoding된 변수의 수가 한 개 작습니다. (위의 예시 그림에서 보듯 3개입니다.).
Effect encoding
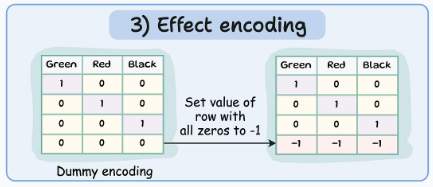
Dummy encoding과 비슷하지만 단계 하나가 더 있습니다. 모든 0이 있는 행을 -1로 변경합니다. 이를 통해 결과적으로 나오는 이진 변수가 특정 범주의 존재 또는 부재 뿐만 아니라 참조 범주와 범주의 부재 간의 대비도 나타내도록 할 수 있습니다.
유니크한 범주형 레이블 수보다 Dummy encoding된 변수의 수가 한 개 작습니다. Effect encoding과 동일합니다.
Label encoding
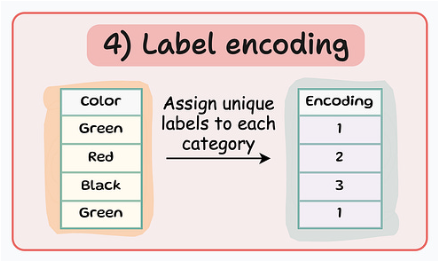
각 카테고리에 고유한 라벨을 지정하는 방법입니다. 라벨 인코딩은 범주 간에 본질적인 순서를 도입하는데, 이는 실제와 다를 수 있습니다. Encoding 변수는 1개입니다.
Ordinal encoding
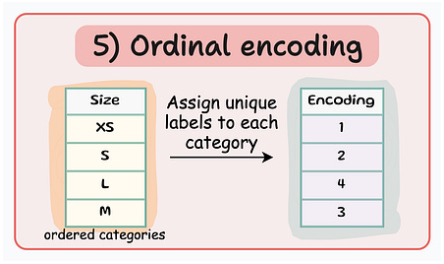
Label encoding과 유사합니다. 각 카테고리에 고유한 정수 값을 할당합니다. 할당된 값에는 내재적인 순서가 있는데, 즉 한 범주는 다른 범주보다 크거나 작은 것으로 간주된다는 것을 의미합니다. Encoding 변수는 1개입니다.
Count encoding

Frequency encoding이라고도 합니다. 각 범주의 빈도에 따라 범주별 특성을 인코딩합니다. 따라서 범주를 숫자 값이나 이진 표현으로 대체하는 대신, 카운트 인코딩은 각 범주에 해당 카운트를 직접 할당합니다. Encoding 변수는 1개입니다.
Binary encoding encoding
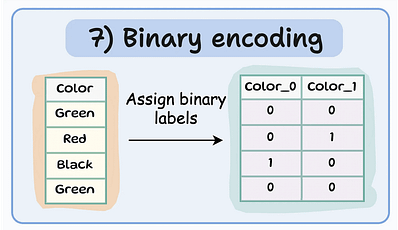
One-hot encoding과 Ordinal encoding의 조합입니다. 범주를 이진 코드로 나타냅니다. 각 범주에 먼저 순서형 값이 할당된 다음 해당 값이 이진 코드로 변환됩니다. 이진 코드는 별도의 이진 피처로 분할됩니다.
차원을 One-hot encoding에 비해 줄이기 때문에 높은 카디널리티 범주형 피처(또는 많은 수의 피처)를 처리할 때 유용합니다. Encoding 변수는 log(n) (n = base 2개)입니다.
결론
이번 포스팅에서 설명한 방범은 가장 인기 있는 기술 중 일부입니다. 이것들이 범주형 데이터를 인코딩하는 유일한 방법이 아니라는 점에 유의하세요. category-encoders 라이브러리로 다양한 방법을 시도할 수 있습니다.