Numpy 라이브러리는 Python으로 구축된 가장 중요하고 판도를 바꾸는 핵심 라이브러리 중 하나로 모든 데이터 과학 및 기계 학습 프로젝트의 핵심입니다. 전체 데이터 기반 생태계는 어떤 식으로든 NumPy와 그 핵심 기능에 의존하고 있습니다.
비교할 수 없는 잠재력으로 인해 산업 및 학계에서 폭넓게 적용할 수 있다는 점을 감안할 때 Numpy의 메서드 및 구문에 대한 지식은 Python 프로그래머에게 가장 필요합니다. 처음 학습하고자 하는 경우 Numpy의 공식 문서로 시작하면 내용이 매우 방대하여 벅차고 압도적으로 보일 수 있습니다.
이번 포스팅에서는 Numpy를 처음 배우기 시작하는 데 도움을 주기 위한 것입니다. Numpy에서 자주 사용하는 45가지 구체적인 방법에 대해서 알아보고자 합니다.
라이브러리 가져오기
통상적으로 numpy 라이브러리의 별칭을 np로 설정하여 가져옵니다. 우리는 여기저기서 Pandas도 사용할 것이므로 Pandas 라이브러리도 import하겠습니다.
Numpy 배열 생성 방법
다음은 Numpy 배열을 만드는 가장 일반적인 방법 중 일부입니다.
(1) Python 리스트 활용
Python 리스트를 Numpy 배열로 변환하려면 np.array() 메서드를 사용하시면 됩니다.
pythonList = [1, 2, 3]
np.array(pythonList)
------------------------------
array([1, 2, 3])Python에서 사용할 수 있는 type 메서드를 사용하여 생성된 객체의 데이터 유형을 확인할 수 있습니다.
type(np.array(pythonList))
-----------------------------
numpy.ndarray
위의 예시에서는 1차원 배열을 만들었습니다.

그러나 np.array() 메서드가 있는 리스트안에 리스트를 사용하여 다차원 Numpy 배열을 만들 수도 있습니다.
twoDimensionArray = [[1,2,3], [4,5,6]]
np.array(twoDimensionArray)
-----------------------------------------
array([[1, 2, 3],
[4, 5, 6]])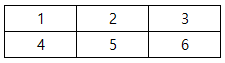
특정 데이터 유형의 Numpy 배열을 만들려면 dtype 인수를 전달하시면 됩니다.
np.array(twoDimensionArray, dtype = np.float32)
---------------------------------------------------
array([[1., 2., 3.],
[4., 5., 6.]], dtype=float32)(2) 0으로 구성된 배열 생성
0으로 채워진 Numpy 배열을 매우 자주 생성하게 됩니다. 다음과 같이 NumPy에서 np.zeros() 메서드를 사용하여 생성할 수 있습니다.
np.zeros(5)
---------------------------------
array([0., 0., 0., 0., 0.])다차원 NumPy 배열은 아래와 같이 생성합니다.
np.zeros((2, 3))
----------------------------
array([[0., 0., 0.],
[0., 0., 0.]])(3) 1로 구성된 배열 생성
np.ones((2, 3))
----------------------------
array([[1., 1., 1.],
[1., 1., 1.]])(4) Identity 배열 만들기
항등 행렬에서 대각선은 “1”로 채워지고 대각선을 제외한 모든 항목은 다음과 같이 “0”입니다.
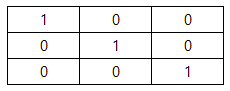
np.eye() 메서드를 사용하여 항등 행렬을 생성합니다.
np.eye(3)
-----------------------
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])(5) 특정 단계로 균일한 간격의 배열 만들기
주어진 간격 내에서 균일한 간격의 값을 생성하려면 np.arange() 메서드를 사용하면 됩니다.
- start=0부터 stop=10까지 값 생성, step=1
np.arange(10)
------------------------------------------
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])- start=5에서 stop=11까지 값 생성, step=1
np.arange(5, 11)
-------------------------------
array([ 5, 6, 7, 8, 9, 10])- start=5에서 stop=11까지 값 생성, step = 2
np.arange(5, 11, 2)
---------------------
array([5, 7, 9])stop 값은 최종 배열에 포함되지 않으며 step=1이 기본값 입니다.
(6) 특정 배열 크기로 균일한 간격의 배열 생성
위에서 설명한 np.arange()와 유사하지만 np.linspace()를 사용하면 일정한 간격으로 숫자를 생성할 수 있으며, 이 때 숫자의 간격은 균일합니다.
np.linspace(start = 10, stop = 20, num = 5)
-----------------------------------------------
array([10. , 12.5, 15. , 17.5, 20. ])(7)(8) 임의의 배열 생성
- 임의의 정수 배열을 생성하려면 np.random.randint() 메서드를 사용하시면 됩니다.
np.random.randint(low = 5, high = 16, size = 5)
----------------------------------------------------
array([ 7, 11, 15, 9, 15])- 무작위 부동 샘플을 생성하려면 np.random.random() 메서드를 사용하시면 됩니다.
np.random.random(size = 10)
------------------------------------------------------------------------
array([0.42106158, 0.14156227, 0.94124528, 0.64084569, 0.15624377,
0.09835155, 0.80636444, 0.90832958, 0.68976214, 0.06137972])(9)(10) Pandas series에서 배열 생성
Pandas series를 Numpy 배열로 변환하려면 np.array() 또는 np.asarray() 메서드를 사용하시면 됩니다.
pandasSeries = pd.Series([1,2,3,4], name = "col")
np.array(pandasSeries)
-------------------------------------------------------
array([1, 2, 3, 4], dtype=int64)np.asarray(pandasSeries)
-------------------------------------
array([1, 2, 3, 4], dtype=int64)Numpy 배열 조작 방법
다음은 Numpy 배열을 조작하기 위해 가장 널리 사용되는 몇 가지 방법에 대해 설명합니다.
(11) 배열의 모양
다음과 같이 Numpy 배열의 ndarray.shape 속성의 np.shape() 메서드를 사용하여 Numpy 배열의 모양을 결정할 수 있습니다.
tempOne = np.ones((2, 3))
print("Shape of the array - Method 1:", np.shape(tempOne))
print("Shape of the array - Method 2:",tempOne.shape)
--------------------------------------------------------------
Shape of the array - Method 1: (2, 3)
Shape of the array - Method 2: (2, 3)(12) 배열 재구성
모양 변경은 데이터를 변경하지 않고 Numpy 배열에 새로운 모양을 부여하는 것을 말합니다. np.reshape() 메서드를 사용하여 모양을 변경할 수 있습니다.
tempTrans = np.arange(10)
tempTrans
----------------------------------------
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])tempTrans.reshape((2, 5))
------------------------------
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])(13)(14) 배열 바꾸기
Numpy 배열을 바꾸려면 np.transpose() 메서드 또는 ndarray.T를 사용하여 아래와 같이 변경할 수 있습니다.
tempReshape = np.arange(12).reshape((6, 2))
tempReshape
------------------------------------------------
array([[ 0, 1],
[ 2, 3],
[ 4, 5],
[ 6, 7],
[ 8, 9],
[10, 11]])tempReshape.transpose()
------------------------------------
array([[ 0, 2, 4, 6, 8, 10],
[ 1, 3, 5, 7, 9, 11]])tempT = np.arange(12).reshape((6, 2))
tempT
---------------------------------------
array([[ 0, 1],
[ 2, 3],
[ 4, 5],
[ 6, 7],
[ 8, 9],
[10, 11]])tempT.T
-------------------------------------
array([[ 0, 2, 4, 6, 8, 10],
[ 1, 3, 5, 7, 9, 11]])(15)(16)(17) 여러 배열을 연결하여 하나의 배열로 만들기
np.concatenate() 메서드를 사용하여 일련의 배열을 결합하고 새로운 배열을 얻을 수 있습니다.
## 행 단위로 연결
a = np.array([[1, 2], [3, 4]])
a
----------------------------------
array([[1, 2],
[3, 4]])b = np.array([[5, 6]])
b
-------------------------------------
array([[5, 6]])np.concatenate((a, b), axis=0)
----------------------------------
array([[1, 2],
[3, 4],
[5, 6]])## 열 단위로 연결
np.concatenate((a, b.T), axis=1)
---------------------------------
array([[1, 2, 5],
[3, 4, 6]])np.concatenate((a, b), axis=None)
------------------------------------
array([1, 2, 3, 4, 5, 6])- axis=0은 np.vstack()과 동일하고,
- axis=1은 np.hstack()과 동일합니다.
(18) 배열 병합
전체 배열을 단일 차원으로 축소하려면 아래와 같이 ndarray.flatten() 메서드를 사용할 수 있습니다.
a = np.array([[1,2], [3,4]])
a
--------------------------------
array([[1, 2],
[3, 4]])a.flatten()
------------------------
array([1, 2, 3, 4])(19) 배열의 고유 요소
NumPy 배열의 고유한 요소를 확인하려면 아래와 같이 np.unique() 메서드를 사용합니다.
a = np.array([[1, 2], [2, 3]])
a
-------------------------------------
array([[1, 2],
[2, 3]])np.unique(a)
--------------------------------
array([1, 2, 3])## 고유 행 반환
a = np.array([[1, 2, 3], [1, 2, 3], [2, 3, 4]])
a
-------------------------------------------------
array([[1, 2, 3],
[1, 2, 3],
[2, 3, 4]])np.unique(a, axis=0)
---------------------------
array([[1, 2, 3],
[2, 3, 4]])## 고유 열 반환
a = np.array([[1, 1, 3], [1, 1, 3], [1, 1, 4]])
a
--------------------------------------------------
array([[1, 1, 3],
[1, 1, 3],
[1, 1, 4]])np.unique(a, axis=1)
--------------------------
array([[1, 3],
[1, 3],
[1, 4]])(20) 배열 짜기
Numpy 배열에서 길이가 1인 축을 제거하려면 아래와 같이 np.squeeze() 메서드를 사용하시면 됩니다.
x = np.array([[[0], [1], [2]]])
x
-------------------------------------
array([[[0],
[1],
[2]]])x.shape
---------------
(1, 3, 1)np.squeeze(x).shape
------------------------
(3,)(21) 배열을 Python 리스트로 변환
Numpy 배열에서 Python 리스트를 얻으려면 아래와 같이 ndarry.tolist() 메서드를 사용하시면 됩니다.
a = np.array([[1, 1, 3], [1, 1, 3], [1, 1, 4]])
a
--------------------------------------------------
array([[1, 1, 3],
[1, 1, 3],
[1, 1, 4]])a.tolist()
-----------------------------------
[[1, 1, 3], [1, 1, 3], [1, 1, 4]]Numpy 배열에 대한 수학적 연산
Numpy는 Numpy 배열에 적용할 수 있는 다양한 요소별 수학 함수를 제공합니다. 아래는 가장 일반적으로 사용되는 몇 가지 수학 함수에 대해 설명하겠습니다.
(22)(23)(24) 삼각함수
a = np.array([1,2,3])
print("Trigonometric Sine :", np.sin(a))
print("Trigonometric Cosine :", np.cos(a))
print("Trigonometric Tangent:", np.tan(a))
----------------------------------------------------------------
Trigonometric Sine : [0.84147098 0.90929743 0.14112001]
Trigonometric Cosine : [ 0.54030231 -0.41614684 -0.9899925 ]
Trigonometric Tangent: [ 1.55740772 -2.18503986 -0.14254654](25)(26)(27)(28) 라운딩 함수
- np.floor() : 요소별 버림값 반환
- np.ceil(): 요소별 올림값 반환
- np.rint(): 요소별 가장 가까운 정수값 반환
np.floor(a)
-------------------------------
array([1., 1., 1., 1., 2.])np.ceil(a)
--------------------------------
array([1., 2., 2., 2., 2.])np.rint(a)
------------------------------
array([1., 1., 2., 2., 2.])np.round_() 메서드를 사용하여 주어진 소수점 이하 자릿수로 반올림할 수도 있습니다.
a = np.linspace(1, 2, 7)
np.round_(a, 2) # 소숫점 2자리로 반올림
--------------------------------------------------------
array([1. , 1.17, 1.33, 1.5 , 1.67, 1.83, 2. ])(29)(30) 지수와 로그
- np.exp(): 요소별 지수 값 계산하여 반환
- np.log(): 요소별 자연로그 값 계산한여 반환
a = np.arange(1, 6)
np.exp(a).round(2)
--------------------------------------------------
array([ 2.72, 7.39, 20.09, 54.6 , 148.41])np.log(a).round(2)
-----------------------------------------
array([0. , 0.69, 1.1 , 1.39, 1.61])(31)(32) 합과 곱
np.sum() 메서드를 사용하여 배열 요소의 합을 계산합니다.
a = np.array([[1, 2], [3, 4]])
np.sum(a, axis = 0)
----------------------------------
array([4, 6])np.sum(a, axis = 1)
----------------------------------
array([3, 7])np.prod() 메서드를 사용하여 배열 요소의 곱을 계산합니다.
a = np.array([[1, 2], [3, 4]])
np.prod(a)
--------------------------------------
24np.prod(a, axis = 0)
-------------------------
array([3, 8])np.sum(a, axis = 1)
----------------------------
array([3, 7])(33) 제곱근
np.sqrt() 메서드를 사용하여 배열 요소의 제곱근을 계산합니다.
a = np.array([[1, 2], [3, 4]])
np.sqrt(a)
-----------------------------------
array([[1. , 1.41421356],
[1.73205081, 2. ]])(34)(35)(36) 행렬 및 벡터 연산
(34) 내적
np.dot() 메서드를 사용하여 Numpy 배열의 내적을 계산합니다.
a = np.array([[1, 2], [3, 4]])
b = np.array([[1, 1], [1, 1]])
np.dot(a, b)
------------------------------------
array([[3, 3],
[7, 7]])(35) 행렬 곱
두 Numpy 배열의 행렬 곱을 계산하려면 Python에서 thenp.matmul() 또는 @ 연산자를 사용하시면 됩니다.
a = np.array([[1, 2], [3, 4]])
b = np.array([[1, 1], [1, 1]])
np.matmul(a, b)
------------------------------------
array([[3, 3],
[7, 7]])a@b
-----------------
array([[3, 3],
[7, 7]])이 예에서 np.matmul() 및 np.dot()의 결과는 동일하지만 크게 다를 수 있습니다.
(36) Vector Norm
Vector Norm은 벡터의 길이를 측정하는 데 사용되는 함수 집합을 나타냅니다.
np.linalg.norm() 메서드를 사용하여 행렬 또는 벡터 Norm을 찾습니다.
a = np.arange(-4, 5)
np.linalg.norm(a) ## L2 Norm
-----------------------------------
7.745966692414834np.linalg.norm(a, 1) ## L1 Norm
-------------------------------------
20.0(37)(38) 정렬 방법
(37) Numpy 배열 정렬
배열을 정렬하려면 ndarray.sort() 메서드를 사용하시면 됩니다.
a = np.array([[1,4],[3,1]])
np.sort(a) ## 행 기준으로 정렬
-----------------------------------
array([[1, 4],
[1, 3]])np.sort(a, axis=None) ## 병합된 배열 정렬
-------------------------------------------
array([1, 1, 3, 4])np.sort(a, axis=0) ## 열 기준 정렬
----------------------------------------
array([[1, 1],
[3, 4]])(39)(40)(41)(42) 검색 방법
(39) 최대값에 해당하는 인덱스 산출
축을 따라 최대값의 인덱스를 반환하려면 아래와 같이 np.argmax() 메서드를 사용하시면 됩니다.
a = np.random.randint(1, 20, 10).reshape(2,5)
np.argmax(a) ## flattend 배열 기준 인덱스 반환
-------------------------------------------------
8np.argmax(a, axis=0) ## 열 기준의 인덱스 반환
--------------------------------------------------
array([1, 1, 1, 1, 0], dtype=int64)np.argmax(a, axis=1) ## 행 기준의 인덱스 반환
--------------------------------------------------
array([4, 3], dtype=int64)non-flattened 배열에서 인덱스를 찾으려면 아래와 같이 수행하세요.
ind = np.unravel_index(np.argmax(a), a.shape)
ind
------------------------------------------------
(1, 3)(40) 최소값에 해당하는 인덱스 산출
마찬가지로 축을 따라 최소값의 인덱스를 반환하려면 아래와 같이 np.argmin() 메서드를 사용하시면 됩니다.
a = np.random.randint(1, 20, 10).reshape(2,5)
np.argmin(a) ## flattend 배열 기준 인덱스 반환
--------------------------------------------------
array([3, 4], dtype=int64)np.argmin(a, axis=0) ## 열 기준의 인덱스 반환
--------------------------------------------------
array([0, 1, 0, 0, 1], dtype=int64)np.argmin(a, axis=1) ## 행 기준의 인덱스 반환
-----------------------------------------------
array([3, 4], dtype=int64)(41) 조건에 따라 검색
조건에 따라 두 배열 중에서 선택하려면 아래와 같이 np.where() 메서드를 사용하시면 됩니다.
a = np.random.randint(-10, 10, 10)
a
-----------------------------------------------------------
array([ 6, 8, 5, 2, -4, 3, 6, 4, 0, -7])np.where(a < 0, 0, a)
-----------------------------------------
array([6, 8, 5, 2, 0, 3, 6, 4, 0, 0])(42) 0이 아닌 요소의 인덱스 확인
Numpy 배열에서 0이 아닌 요소의 인덱스를 확인하려면 np.nonzero() 메서드를 사용하시면 됩니다.
a = np.array([[3, 0, 0], [0, 4, 0], [5, 6, 0]])
a
---------------------------------------------------
array([[3, 0, 0],
[0, 4, 0],
[5, 6, 0]])np.nonzero(a)
------------------------------------------------------------------------
(array([0, 1, 2, 2], dtype=int64), array([0, 1, 0, 1], dtype=int64))(43)(44)(45) 통계적 방법
다음으로 Numpy 배열에서 통계값을 계산하는 방법을 살펴보겠습니다.
(43) 평균
축을 따라 Numpy 배열에 있는 값의 평균을 찾으려면 아래와 같이 np.mean() 메서드를 사용하시면 됩니다.
a = np.array([[1, 2], [3, 4]])
np.mean(a)
---------------------------------
2.5np.mean(a, axis = 1) ## 행 축을 따라 계산
---------------------------------------------
array([1.5, 3.5])np.mean(a, axis = 0) ## 열 축을 따라 계산
--------------------------------------------------
array([2., 3.])(44) 중앙값
Numpy 배열의 중앙값을 계산하려면 np.median() 메서드를 사용하시면 됩니다.
a = np.array([[1, 2], [3, 4]])
np.median(a)
-----------------------------------
2.5np.median(a, axis = 1) ## 행 축을 따라 계산
---------------------------------------------
array([1.5, 3.5])np.median(a, axis = 0) ## 열 축을 따라 계산
-----------------------------------------------
array([2., 3.])(45) 표준 편차
지정된 배열을 따라 Numpy 배열의 표준 편차를 계산하려면 np.std() 메서드를 사용하시면 됩니다.
a = np.array([[1, 2], [3, 4]])
np.std(a)
----------------------------------
1.118033988749895np.std(a, axis = 1) ## 행 축을 따라
-------------------------------------
array([0.5, 0.5])np.std(a, axis = 0) ## 열 축을 따라
------------------------------------
array([1., 1.])이번 포스팅에서는 Numpy에서 가장 많이 사용하는 45가지 방법에 대해 배웠습니다.
Numpy로 작업하는 시간의 약 90% 이상은 이러한 방법을 사용할 것이라고 자신 있게 말할 수 있습니다.
감사합니다!