Pandaralllel 라이브러리는 Pandas가 가지는 데이터 처리 방식의 한계를 일정 부분 해결해 주는 라이브러리입니다. 매우 직관적이고 우아하며 초보자에게 친숙한 API를 갖춘 Pandas 라이브러리는 Python에서 최고의 테이블 형식 데이터 랭글링 라이브러리 중 하나이지만, 데이터 처리 면에서 한계가 있습니다. 특히 이러한 현상은 대용량 데이터를 처리할 때 확연히 나타날 수 있습니다.
오늘날 테이블 형식 데이터 세트로 작업하는 거의 모든 데이터 과학자는 모든 종류의 데이터 작업을 위해 Pandas에 의지합니다. API는 세련된 디자인과 다양한 기능을 제공하지만 소수의 데이터 기반 상황에서 Pandas를 적용할 수 없거나 비효율적으로 만드는 수많은 제한 사항이 있습니다.
다시 말하면 Pandas의 거의 모든 한계는 단일 코어 계산 프레임워크에서 발생합니다. 즉, CPU에 사용 가능한 코어가 여러 개 있어도 Pandas는 항상 단일 코어에 의존하므로 성능이 저하됩니다.
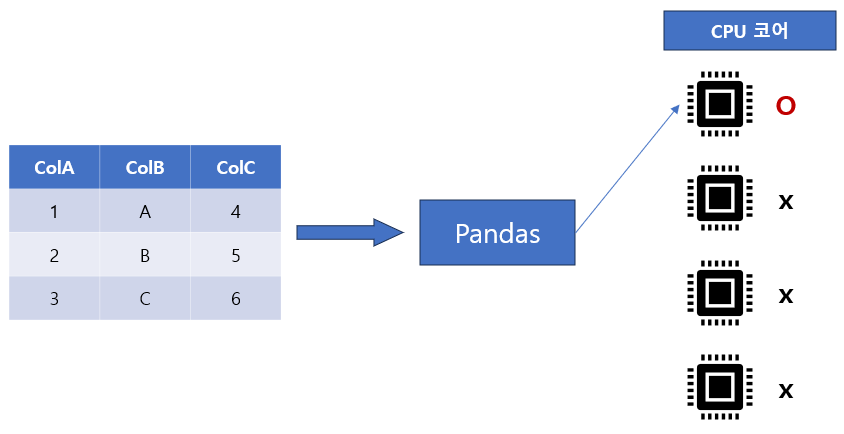
Pandas 공식 라이브러리에서는 이러한 내용을 찾아볼 수 없습니다. 현재 대부분의 사용자가 Pandas를 그대로, 즉 비효율적으로 활용하고 있는 것이 안타까운 현실입니다. 하지만, 고맙게도 지난 몇 년 동안 Pandas 외부의 많은 개발자들이 이 문제를 다루었습니다. 결과적으로 우리는 Pandas로 여러 코어를 활용하여 더 효율적으로 만들 수 있는 몇 가지 도구를 마음대로 사용할 수 있게 되었습니다.
이번 포스팅에서 설명 드릴 라이브러리 도구 중 하나는 Pandarallel입니다!!!
Pandarallel (Pandas + Parallel) 소개
Pandarallel은 Pandas의 작업을 사용 가능한 모든 CPU 코어에 병렬화할 수 있는 오픈 소스 Python 라이브러리입니다. 사용법은 매우 간단합니다. 코드 한 줄만 변경하면 됩니다.
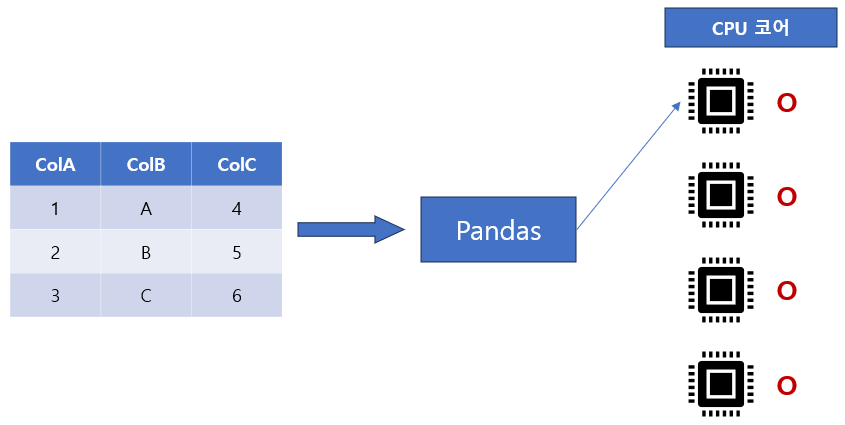
또한 pandarallel은 남은 계산량을 추정하기 위해 멋진 진행률 표시줄(tqdm에서 얻는 것처럼)도 제공합니다.
현재 지원되는 메서드에는 apply(), applymap(), groupby(), map() 및 rolling()이 포함됩니다.
Pandarallel 설치하기
pip install pandarallel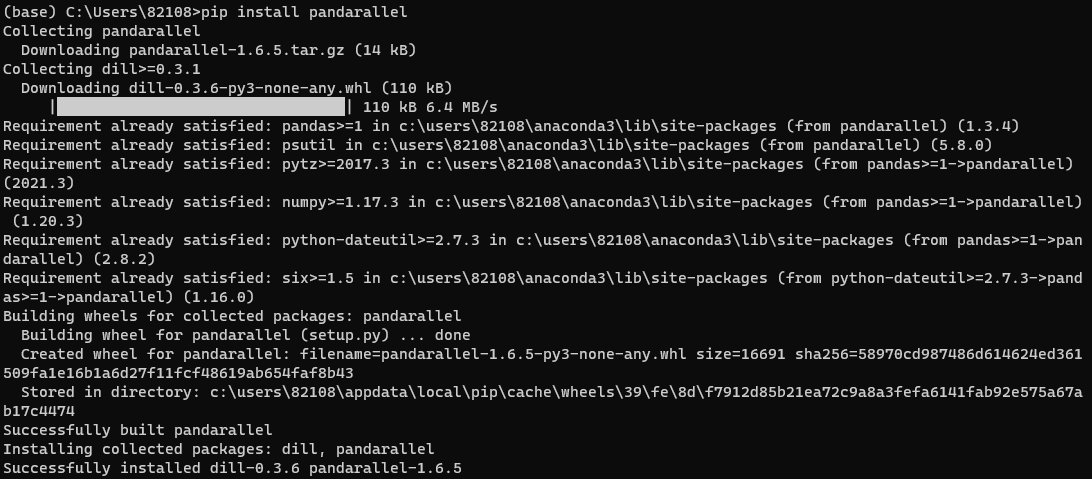
Pandarallel 로딩하기
다음 단계는 라이브러리를 가져오고 초기화하는 것입니다.
from pandarallel import pandarallel
pandarallel.initialize()
----------------------------------------
INFO: Pandarallel will run on 6 workers.
INFO: Pandarallel will use standard multiprocessing data transfer (pipe) to transfer data between the main process and workers.
WARNING: You are on Windows. If you detect any issue with pandarallel, be sure you checked out the Troubleshooting page:
https://nalepae.github.io/pandarallel/troubleshooting/결과 화면에서 볼 수 있듯이 initialize()는 작업을 실행할 작업자 수를 설정합니다(이 경우 6).
여기에서 초기화에 대한 자세한 내용을 읽을 수 있습니다.
이와 함께 Pandas 라이브러리도 가져와야 합니다.
import pandas as pdPandas to Pandarallel
위에서 언급했듯이 Pandas에서 Pandarallel로의 전환은 간단하며 코드 한 줄만 변경하면 됩니다.
이들 중 몇 가지가 아래에 설명되어 있습니다.
| Pandas | Pandarallel |
| df.apply(함수) | df.parallel_apply(함수) |
| df.applymap(함수) | df.parallel_applymap(함수) |
| df.groupby(인수).applymap(함수) | df.groupby(인수).parallel_applymap(함수) |
| series.map(함수) | series.parallel_map(함수) |
| series.apply(함수) | series.parallel_apply(함수) |
핵심은 apply를 parallel_apply로 바꾸고 map을 parallel_map으로 바꾸는 것입니다.
실험
다음으로 Pandas의 apply()와 Pandaralll의 parallel_apply()의 성능을 비교해 보겠습니다. Pandarallel은 사용 가능한 모든 코어를 활용하므로 이상적으로는 Pandarallel이 Pandas보다 더 나은 성능을 보여야 합니다. 정말 더 나은 성능을 보이는지 확인해 보겠습니다.
실험 설정
이 실험을 위해서 가변 행과 5개의 열이 있는 더미 DataFrame을 만들겠습니다. 보다 구체적으로 행 수를 100만에서 1000만까지 변경하고 apply() 및 parallel_apply()의 성능을 그래프로 나타내 보겠습니다. 이 실험의 함수는 아래와 같이 정의되어 있으며 행의 합계를 반환합니다.
def add_row(row):
return sum(row)임의성을 제거하기 위해 특정 수의 행으로 실험을 10회 반복했습니다. 이 실험의 코드는 아래와 같습니다.
import numpy as np
import time as time
results = [["Rows", "Apply() Time", "Parallel_apply() Time"]]
repeat = 10
for idx in range(1, 11):
rows = idx*(10**6) ## 1M ~ 10M 에 해당하는 행의 수
data = np.random.randint(low = 1, high = 1000, size = (rows, 5))
df = pd.DataFrame(data, columns = ["col1", "col2", "col3", "col4", "col5"])
applyTime, parallelApplyTime = 0, 0
for _ in range(repeat):
## calculate time for apply()
start = time.time()
sumApply = df.apply(add_row, axis = 1)
applyTime += (time.time() - start)
## calculate time for parallel_apply()
start = time.time()
sumParallelApply = df.parallel_apply(add_row, axis = 1)
parallelApplyTime += (time.time() - start)
## take average
applyTime = applyTime/repeat
parallelApplyTime = parallelApplyTime/repeat
results.append([rows, applyTime, parallelApplyTime])
pd.DataFrame(results, columns = ["Rows", "Apply() Time", "Parallel_apply() Time"]).iloc[1:]실험 결과
다음으로 결과를 살펴보겠습니다.
| Rows | Apply() Time | Parallel_apply() Time | |
|---|---|---|---|
| 1 | 1000000 | 5.979842 | 5.225464 |
| 2 | 2000000 | 11.965855 | 6.204605 |
| 3 | 3000000 | 17.983735 | 7.205971 |
| 4 | 4000000 | 24.136618 | 8.50846 |
| 5 | 5000000 | 30.075886 | 9.977927 |
| 6 | 6000000 | 36.409807 | 10.700252 |
| 7 | 7000000 | 41.589157 | 11.458047 |
| 8 | 8000000 | 315.755965 | 13.482018 |
| 9 | 9000000 | 55.729558 | 16.23115 |
| 10 | 10000000 | 59.483545 | 15.721631 |
- ‘Apply() Time’ 열은 apply() 메서드의 실행 시간을 나타내고, ‘Parallel_apply() Time’ 열은 parallel_apply() 메서드의 실행 시간을 나타냅니다.
- 행 수를 100만에서 1000만까지 다양하게 하고 두 방법의 실행 시간이 행의 수에 비례함을 알 수 있습니다.
- 그러나 parallel_apply() 메서드는 기존의 apply() 메서드에 비해 런타임에서 상당한 개선 효과가 있었습니다.
- 행 수가 증가함에 따라 두 메서드의 실행 시간 차이도 늘어납니다. 이는 특히 더 큰 데이터 세트의 경우 DataFrame에 함수를 적용하기 위해 항상 parallel_apply()를 사용해야 함을 나타냅니다.
결론
이번 포스팅에서는 Pandas의 apply() 성능을 더미 DataFrame 세트에서 Pandallel의 parallel_apply() 메서드와 비교했습니다. 실험 결과는 parallel_apply() 메서드를 사용하는 것이 apply() 메서드에 비해 런타임 측면에서 최대 4~5배 더 효율적이라는 점을 확인할 수 있었습니다.