Pandas DataFrame은 다양한 테이블 형식의 데이터 분석, 관리 및 처리 작업을 위해 기계 학습 엔지니어와 데이터 과학자 사이에서 널리 사용되고 있는 데이터 유형입니다. Pandas 라이브러리는 수많은 사용 사례에 대해 자체 라이브러리로 대부분의 데이터 를 처리하지만, Python의 다른 라이브러리를 사용해야 하는 상황이 있을 수 있습니다. 이는 DataFrame을 지원하는 다른 형태의 데이터로 변환해야 하는 상황이 필요합니다. 이러한 변환에 대한 인식이 DataFrame의 일반적인 사용에 도움이 될 수 있다고 생각합니다. 따라서 이번 포스팅에서는 DataFrame을 Python 커뮤니티의 개발자가 널리 사용하는 다른 데이터 유형으로 변환하는 다양한 방법에 대해서 알아보겠습니다.
DataFrame 이해하기
DataFrame의 다양한 유형 변환을 진행하기 전에 이 데이터 구조에 대해서 설명해 드리겠습니다. Pandas DataFrame은 Python 환경 내에 있는 테이블 형식의 데이터 구조입니다. 필터링 작업, I/O 작업, 데이터 그룹화 및 집계, 테이블 조인, 열 배포 방법 등과 같은 다양한 테이블 형식의 데이터 작업을 능숙하게 수행할 수 있습니다. 물론 기존 Python 환경/세션에 Pandas DataFrame을 로드한 경우에만 위 작업을 수행할 수 있습니다. DataFrame을 생성하는 가장 기본적인 기술 중 하나는 아래에 설명된 대로 pd.DataFrame() 메서드를 사용하는 것입니다. 이를 위해 먼저 필요한 라이브러리를 가져옵니다.
import pandas as pd
import numpy as np
다음으로 아래와 같이 pd.DataFrame() 메서드를 사용하여 리스트의 리스트 구조를 이용해서 DataFrame df를 만듭니다.
data = [[1,”A”,4],
[2,”B”,5],
[3,”C”,6]]
df = pd.DataFrame(data, columns = [“ColA”, “ColB”, “ColC”])
print(df)
ColA ColB ColC 0 1 A 4 1 2 B 5 2 3 C 6
Python에서 type() 메서드를 사용하여 DataFrame의 클래스를 확인할 수 있습니다.
type(df)
pandas.core.frame.DataFrame
Numpy 배열로 변환
먼저 Pandas 데이터 개체를 NumPy 배열로 변환하는 방법을 알아보겠습니다. 여기서는 위에서 단순하게 생성한 DataFrame을 이용하겠습니다.
data = [[1,”A”,4],
[2,”B”,5],
[3,”C”,6]]
df = pd.DataFrame(data, columns = [“ColA”, “ColB”, “ColC”])
print(df)
ColA ColB ColC 0 1 A 4 1 2 B 5 2 3 C 6
방법1
values 속성을 사용하여 Pandas DataFrame을 Numpy 배열로 변환할 수 있습니다.
result = df.values
result
array([[1, 'A', 4],
[2, 'B', 5],
[3, 'C', 6]], dtype=object)
실제로 Numpy 배열인 결과 객체의 데이터 유형을 확인할 수 있습니다.
type(result)
numpy.ndarray
방법2
Pandas에서 사용할 수 있는 또 다른 방법은 to_numpy() 메서드 입니다.
df.to_numpy()
array([[1, 'A', 4],
[2, 'B', 5],
[3, 'C', 6]], dtype=object)
* 참고: Pandas 공식 문서에서는 방법 1에서 설명한 values 속성보다 df.to_numpy()를 사용할 것을 권장하고 있습니다.
방법3
마지막으로 Numpy의 기본 메서드인 np.array()를 사용하여 다음과 같이 Pandas DataFrame을 Numpy 배열로 변환할 수도 있습니다.
np.array(df)
array([[1, 'A', 4],
[2, 'B', 5],
[3, 'C', 6]], dtype=object)
NumPy 배열을 생성하는 다양한 방법에 대해 배우고 싶다면 아래 블로그 글에서 확인할 수 있습니다.
Numpy 프로가 되기 위해 반드시 알아야 하는 45가지 방법
Python List로의 변환
다음으로 Pandas DataFrame을 Python 리스트로 변환하는 몇 가지 방법에 대해서 알아보겠습니다. Pandas는 Pandas DataFrame을 Python 리스트로 직접 변환하는 방법을 제공하지 않습니다. 따라서 이를 해결하기 위해서는 먼저 1) DataFrame을 Numpy 배열로 변환한 다음, 2) Numpy의 tolist() 메서드를 사용하여 리스트로 변환해야 합니다.
# DataFrame을 Numpy 배열로 변환(df.values) 후 리스트로 추가 변환(.tolist())
result = df.values.tolist()
print(result)
print(type(result))
[[1, 'A', 4], [2, 'B', 5], [3, 'C', 6]] <class 'list'>
위에서 설명한 것처럼 변환 방식은 먼저 위에서 설명한 values 특성을 사용하여 DataFrame을 Numpy 배열로 변환하고, 이후 Numpy의 tolist() 메서드를 사용합니다.
Dictionary로의 변환
Pandas DataFrame의 자주 사용하는 또 다른 변환은 Python Dictionary를 생성하는 것입니다. 앞서 사용한 간단한 DataFrame을 계속 사용하겠습니다.
data = [[1,”A”,4],
[2,”B”,5],
[3,”C”,6]]
df = pd.DataFrame(data, columns = [“ColA”, “ColB”, “ColC”])
print(df)
ColA ColB ColC 0 1 A 4 1 2 B 5 2 3 C 6
Pandas에서는 to_dict() 메서드를 사용하여 DataFrame을 Dictionary로 변환할 수 있습니다. 아래에서는 이 방법을 활용하여 생성할 수 있는 Python Dictionary의 다양한 형식에 대해 설명합니다. 이러한 형식은 주로 메서드에서 반환된 key-value 쌍의 유형에 따라 다릅니다. Dictionary의 구조는 to_dict() 메서드의 orient 매개변수에 의해 결정됩니다.
방법1
orient=’dict'(매개 변수의 기본값이기도 함)를 사용하면 이 메서드는 중첩된 Dictionary를 반환합니다. 여기서 바깥쪽 Dictionary의 key는 열의 이름이고 안쪽 Dictionary의 key는 인덱스 값입니다. 기본 동작(orient=’dict’)의 그래프는 아래와 같습니다.
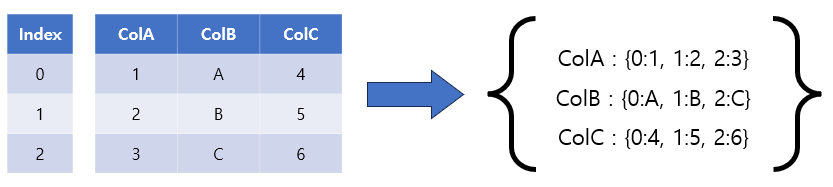
아래 코드 블록은 to_dict() 메서드의 결과를 보여줍니다.
df.to_dict()
{'ColA': {0: 1, 1: 2, 2: 3},
'ColB': {0: 'A', 1: 'B', 2: 'C'},
'ColC': {0: 4, 1: 5, 2: 6}}
방법2
방법 1에서와 같이 중첩된 Dictionary를 갖는 것과는 대조적으로 key를 열 이름으로 사용하고 value를 리스트로 표시되는 열로 사용하여 DataFrame에서 Dicionary를 생성할 수 있습니다.
orient=”list”를 to_dict() 메서드에 전달하여 이를 달성할 수 있습니다.
이는 아래 그래프로 설명할 수 있습니다.
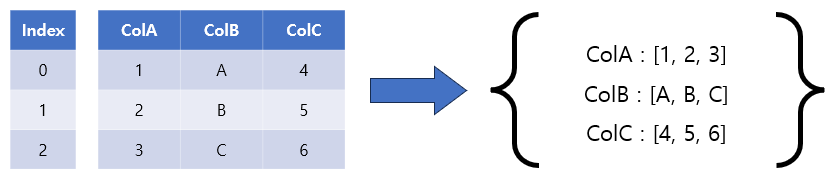
구현은 아래와 같습니다.
df.to_dict(“list”)
{'ColA': [1, 2, 3], 'ColB': ['A', 'B', 'C'], 'ColC': [4, 5, 6]}
to_dict() 메서드를 사용하여 Dicionary를 생성하는 또 다른 방법은 orient=”split” 매개변수를 지정하는 것입니다.
반환된 Dicionary에는 세 개의 key-value 쌍이 있습니다. 이것들은
- ‘index’: 이 값은 DataFrame의 인덱스를 Python 리스트로 보유합니다.
- ‘columns’: 열의 이름을 지정하는 리스트 입니다.
- ‘data’: 이 매개변수의 값은 DataFrame의 행을 나타내는 리스트의 리스트입니다. 이 key의 value는 ‘Python 리스트로 변환’ 에서 설명 드린 것과 동일합니다.
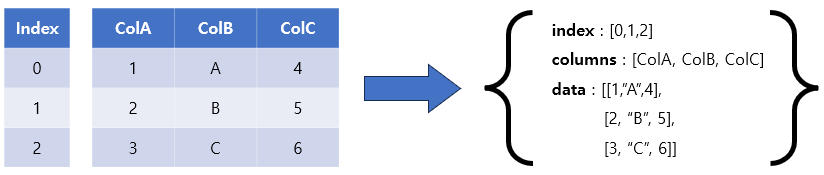
이 변환의 결과는 아래와 같습니다.
df.to_dict(“split”)
{'index': [0, 1, 2],
'columns': ['ColA', 'ColB', 'ColC'],
'data': [[1, 'A', 4], [2, 'B', 5], [3, 'C', 6]]}
결론
이번 포스팅에서는 Pandas DataFrame을 다른 Python Data 객체로 변환하는 다양한 방법에 대해서 알아 보았습니다. 구체적으로는 Pandas DataFrame을 NumPy 배열, Python 리스트 및 dictionary로 변환하는 방법에 대해 논의했습니다. DataTable DataFrame, Dask DataFrame 및 Spark DataFrame과 같은 다양한 다른 데이터 클래스(또는 데이터 유형/프레임워크 등)는 Pandas와의 변환을 지원합니다. 이는 별도 포스팅으로 자세히 알아 보겠습니다.
감사합니다!!!!