Polars 라이브러리 시작하기 에 도움이 되고자 하는 마음에 이번 포스팅 글을 작성하였습니다. Polars 라이브러리의 모든 기본 특징과 기능을 다루기 때문에, 신규 사용자가 초기 설치 및 설정부터 핵심 기능까지 기본 사항을 쉽게 익힐 수 있도록 하기 위해 작성하였습니다.
Polars 라이브러리 설치하기
일반적인 라이브러리 설치 방법과 동일합니다.
pip install polars읽고 쓰기
Polars는 일반적인 파일 형식(예: csv, json, parquet), 클라우드 스토리지(S3, Azure Blob, BigQuery) 및 데이터베이스(예: postgres, mysql)에 대한 읽기 및 쓰기를 지원합니다. 아래 예시는 디스크를 읽고 쓰는 개념을 보여주고 있습니다.
import polars as pl
from datetime import datetime
tempData = pl.DataFrame(
{
"integer": [1, 2, 3],
"date": [
datetime(2025, 1, 1),
datetime(2025, 1, 2),
datetime(2025, 1, 3),
],
"float": [4.0, 5.0, 6.0],
"string": ["a", "b", "c"],
}
)
tempData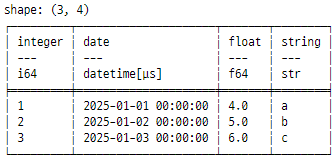
아래 예시에서는 DataFrame을 data.csv라는 csv 파일에 작성합니다. 그런 다음 read_csv를 사용하여 다시 읽은 다음 검사를 위해 제대로 읽었는지 결과를 출력합니다.
# tempData 데이터 프레임을 D드라이브에 "output.csv" 파일 쓰기
tempData.write_csv("D:/output.csv")
# D드라이브에 "output.csv" 파일을 tempDataCsv 데이터 프레임으로 읽기
tempDataCsv = pl.read_csv("D:/output.csv")
# tempDataCsv 데이터 프레임 확인
tempDataCsv
표현식
표현식은 Polars 라이브러리의 핵심 강점입니다. 표현식은 간단한 개념을 복잡한 쿼리로 결합할 수 있는 모듈식 구조를 제공합니다. 아래에서는 모든 쿼리에 대한 빌딩 블록(또는 Polars 용어 컨텍스트) 역할을 하는 기본 구성 요소를 다룹니다.
selectfilterwith_columnsgroup_by
select
데이터 프레임에서 열을 선택하려면 두 가지 작업을 수행해야 합니다.
- 얻고자 하는 데이터를 원하는 DataFrame을 정의합니다.
- 필요한 데이터를 선택합니다.
아래 예에서는 col(‘*’)을 선택했습니다. 별표는 데이터 프레임에 포함되어 있는 모든 열을 나타냅니다.
print(tempData.select(pl.col("*")))반환하려는 특정 열을 지정할 수도 있습니다. 이를 수행하는 방법에는 두 가지가 있습니다. 첫 번째 옵션은 아래와 같이 열 이름을 전달하는 것입니다.
print(tempData.select(pl.col("float", "string")))
filter
필터 옵션을 사용하면 DataFrame의 하위 집합을 만들 수 있습니다. 아래 예시 코드는 이전과 동일한 DataFrame을 사용하여 지정된 두 날짜 사이 필터링합니다.
print(
tempData.filter(
pl.col("date").is_between(datetime(2025, 1, 1), datetime(2025, 1, 2))
)
)
여러 열을 포함하는 더 복잡한 필터를 만들 수도 있습니다.
print(tempData.filter((pl.col("float") <= 4) & (pl.col("integer").is_not_nan())))
열 추가
with_columns를 사용하면 분석을 위한 새 열을 생성할 수 있습니다. 아래 코드는 두 개의 새로운 열 e와 b+42를 만듭니다. 먼저 b 열의 모든 값을 합산하고 그 결과를 e 열에 저장합니다. 그런 다음 b 값에 42를 더합니다. 이를 저장하기 위한 새 열 b+42 를 생성합니다.
print(tempData.with_columns(pl.col("float").sum().alias("e"), (pl.col("float") + 42).alias("b+42")))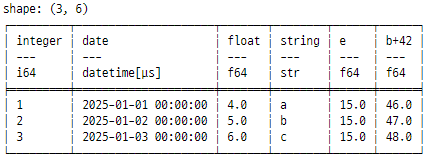
Group by
Group by 함수를 위한 새로운 DataFrame을 생성합니다. 이 새로운 DataFrame에는 그룹화하려는 여러 ‘groups’가 포함됩니다.
tempData2 = pl.DataFrame(
{
"x": range(8),
"y": ["A", "A", "A", "B", "B", "C", "X", "X"]
}
)
print(tempData2)
--------------------------------------------------------------

Group by 사용 예시
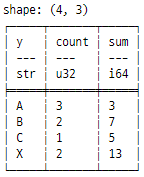
print(tempData2.group_by("y", maintain_order = True).len())
print(
tempData2.group_by("y", maintain_order = True).agg(
pl.col("*").count().alias("count"),
pl.col("*").sum().alias("sum")
)
)
Combination
아래 코드는 결합하여 필요한 DataFrame을 생성하는 방법에 대한 몇 가지 예입니다.
tempDataX = tempData.with_columns((pl.col("integer") * pl.col("float")).alias("integer * float")).select(
pl.all().exclude(["date"])
)
print(tempDataX)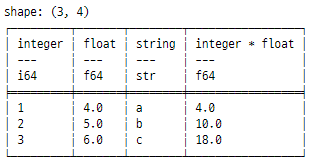
DataFrame 결합
DataFrame을 결합하는 방법에는 조인(join)과 연결(concat)이라는 두 가지 방법이 있습니다.
Join
Polars는 모든 유형의 조인(예: 왼쪽, 오른쪽, 내부, 외부)을 지원합니다. 두 개의 DataFrame을 단일 DataFrame으로 결합하는 방법을 자세히 살펴보겠습니다.
두 개의 DataFrame에는 모두 ‘id’와 같은 열인 a와 x가 있습니다. 이 예에서는 해당 열을 사용하여 DataFrame을 조인할 수 있습니다.
import numpy as np
temp1 = pl.DataFrame(
{
"a": range(8),
"b": np.random.rand(8),
"d": [1, 2.0, float("nan"), float("nan"), 0, -5, -42, None],
}
)
temp2 = pl.DataFrame(
{
"x": range(8),
"y": ["A", "A", "A", "B", "B", "C", "X", "X"],
}
)
joined = temp1.join(temp2, left_on="a", right_on="x")
print(joined)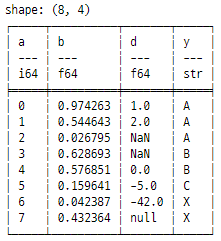
Concat
두 개의 DataFrame을 연결할 수도 있습니다. 수직 연결은 DataFrame을 더 길게 만듭니다. 가로 연결을 사용하면 DataFrame은 더 넓어집니다. 아래에서는 두 DataFrame을 가로로 연결한 결과를 볼 수 있습니다.
stacked = temp1.hstack(temp2)
print(stacked)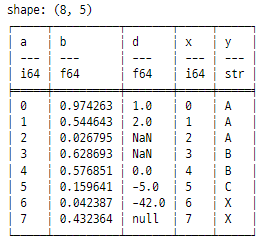
결론
이번 포스팅에서는 Polars 라이브러리 사용법에 대한 기초 사항을 알아보았습니다. 다음 포스팅에서는 Polars 라이브러리의 기본 연산에 대해서 알아보겠습니다.
감사합니다!