이번 포스팅은 Python pandas 마스터하기 위한 아홉 번째 포스팅입니다( python pandas 마스터하기 81~90 ).
이번 포스팅 내용을 학습하기 전에 이전 포스팅(Python pandas 마스터하기 1 ~10, Python pandas 마스터하기 11 ~20, Python pandas 마스터하기 21 ~30, Python pandas 마스터하기 31 ~40, Python pandas 마스터하기 41 ~50, Python pandas 마스터하기 51 ~60, Python pandas 마스터하기 61 ~70, Python pandas 마스터하기 71 ~80) 내용을 먼저 학습하시기 바랍니다.
간단한 예제 코드와 설명을 포함한 100가지 Python pandas 코드 중 No 81 ~ 90개에 대해서 살펴보겠습니다.
81. 데이터프레임에서 열의 자기상관 계산하기
실습을 위해 아래 데이터를 D드라이브에 다운로드 하시기 바랍니다.
import pandas as pd
titanicData = pd.read_csv("D:/titanic.csv")
# 자기상관 계산하기
columnName = 'Fare'
autocorrelation = titanicData[columnName].autocorr()
# 자기상관 출력하기
print(columnName,"열의 자기상관 : ", autocorrelation)
------------------------------------------------------------------------
Fare 열의 자기상관 : -0.011468971806148325Pandas에서 제공하는 autocorr() 메서드를 사용하여 해당 열의 자기상관을 계산할 수 있습니다.
82. 정방향 또는 역방향 채우기를 사용하여 데이터프레임에서 결측치 채우기
import pandas as pd
# 정방향 채우기를 사용한 결측치 채우기
forwardFilledDf = titanicData.fillna(method = 'ffill')
# 역방향 채우기를 사용한 결측치 채우기
backwardFilledDf = titanicData.fillna(method = 'bfill')
# 결과값 확인하기
print("원래 데이터프레임:")
titanicData.head()
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2.3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN Sprint("\n정방향 결측치 채우기 결과 데이터프레임:")
forwardFilledDf.head()
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2.3101282 7.9250 C85 S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 C123 S누락된 값을 채우기 위해 fillna() 메소드를 사용합니다. 정방향 채우기를 사용하여 누락된 값을 채우려면 인수 method = ‘ffill’을 fillna() 메서드에 전달해야 합니다. 그러면 마지막으로 관찰된 값이 앞으로 전파됩니다(Cabin 칼럼을 확인해 보세요).
print("\n역방향 결측치 채우기 결과 데이터프레임:")
backwardFilledDf.head()
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 C85 S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2.3101282 7.9250 C123 S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 E46 S후방 채우기를 사용하여 누락된 값을 채우려면 인수 method = ‘bfill’을 fillna() 메서드에 전달해야 합니다. 그러면 다음으로 관찰된 값이 뒤로 전파됩니다(Cabin 칼럼을 확인해 보세요).
83. 데이터프레임에 있는 열의 누적 평균 계산
import pandas as pd
# 누적 평균을 계산하고자 하는 열 이름 정의
columnName = 'Fare'
# 누적 평균 계산
cumulativeMean = titanicData[columnName].cumsum() / (titanicData.index + 1)
titanicData['cumulativeMean'] = cumulativeMean
# 누적 평균값 확인
titanicData[['Fare','cumulativeMean']]
----------------------------------------------
Fare cumulativeMean
0 7.2500 7.250000
1 71.2833 39.266650
2 7.9250 28.819433
3 53.1000 34.889575
4 8.0500 29.521660
... ... ...
886 13.0000 32.246617
887 30.0000 32.244087
888 23.4500 32.234195
889 30.0000 32.231685
890 7.7500 32.204208
891 rows × 2 columns누적 평균을 계산하려면 cumsum() 메서드를 사용하여 열 값의 누적 합계를 계산해야 합니다. 그런 다음 누적 합계를 index + 1로 나누어 누적 평균을 계산할 수 있습니다.
다음으로 titanicData[‘cumulativeMean’] = cumulativeMean을 사용하여 누적 평균을 데이터프레임에 ‘cumulativeMean’이라는 새 열로 추가합니다.
84. 데이터프레임에 있는 열의 누적 분산 계산
import pandas as pd
# 누적 분산을 계산하고자 하는 열 이름 정의
columnName = 'Fare'
# 누적 분산 계산
cumulativeVariance = titanicData[columnName].expanding().var()
titanicData['cumulativeVariance'] = cumulativeVariance
# 누적 분산 계산 확인하기
titanicData[['Fare','cumulativeVariance']]
-------------------------------------------------------------------
Fare cumulativeVariance
0 7.2500 NaN
1 71.2833 2050.131754
2 7.9250 1352.498885
3 53.1000 1049.052403
4 8.0500 930.861860
... ... ...
886 13.0000 2479.811327
887 30.0000 2477.021282
888 23.4500 2474.318836
889 30.0000 2471.541184
890 7.7500 2469.436846
891 rows × 2 columns누적 분산을 계산하려면 Expand() 함수를 사용하여 확장 창을 계산해야 합니다. 그런 다음 var() 메서드를 확장 창에 적용하여 분산을 계산합니다.
85. 데이터프레임에 있는 열의 누적 표준 편차 계산
import pandas as pd
# 누적 표준편차를 계산하고자 하는 열 이름 정의
columnName = 'Fare'
# 누적 표준편차 계산
cumulativeStd = titanicData[columnName].expanding().std()
titanicData['cumulativeStd'] = cumulativeStd
# 누적 분산 계산 확인하기
titanicData[['Fare','cumulativeStd']]
--------------------------------------------------------------
Fare cumulativeStd
0 7.2500 NaN
1 71.2833 45.278381
2 7.9250 36.776336
3 53.1000 32.389078
4 8.0500 30.510029
... ... ...
886 13.0000 49.797704
887 30.0000 49.769682
888 23.4500 49.742525
889 30.0000 49.714597
890 7.7500 49.693429
891 rows × 2 columns누적 표준 편차를 계산하려면 Expand() 함수를 사용하여 확장 창을 계산해야 합니다. 그런 다음 확장 창에 std() 메서드를 적용하여 표준 편차를 계산합니다.
86. 데이터프레임의 연속 열 사이의 백분율 변화 계산
import pandas as pd
def calculate_percentage_change(df):
"""
데이터 프레임에서 연속 열 사이의 백분율 변화 계산
인수:
- df: 데이터프레임
The input DataFrame.
결과값:
- 데이터프레임
연속 열 사이의 백분율 변화를 계산한 칼럼을 포함하는 새로운 데이터프레임
"""
return df.pct_change(axis=1) * 100
# 위에서 정의한 함수 호출
percentage_change_df = calculate_percentage_change(titanicData[['Age','Fare']])
# 새로운 데이터프레임 확인
percentage_change_df
-----------------------------------------------------------------------------------
Age Fare
0 NaN -67.045455
1 NaN 87.587632
2 NaN -69.519231
3 NaN 51.714286
4 NaN -77.000000
... ... ...
886 NaN -51.851852
887 NaN 57.894737
888 NaN NaN
889 NaN 15.384615
890 NaN -75.781250
891 rows × 2 columnsPandas 라이브러리에서 제공하는 pct_change() 함수를 사용하여 데이터프레임의 연속 열 사이의 백분율 변화를 계산합니다.
87. 데이터프레임의 두 열 사이의 백분율 차이 계산
import pandas as pd
percentage_difference_series = ((titanicData['Fare'] - titanicData['Age']) / titanicData['Age']) * 100
percentage_difference_series
--------------------------------
0 -67.045455
1 87.587632
2 -69.519231
3 51.714286
4 -77.000000
...
886 -51.851852
887 57.894737
888 NaN
889 15.384615
890 -75.781250
Length: 891, dtype: float64위 코드는 아래 공식을 사용하여 데이터프레임에 있는 두 열 간의 백분율 차이를 계산합니다.
((column2 – column1) / column1) * 100
88. Pandas 데이터프레임을 사용한 Line Plot
import pandas as pd
titanicData.sort_values('Age').plot(x = 'Age', y = 'Fare', kind = 'line')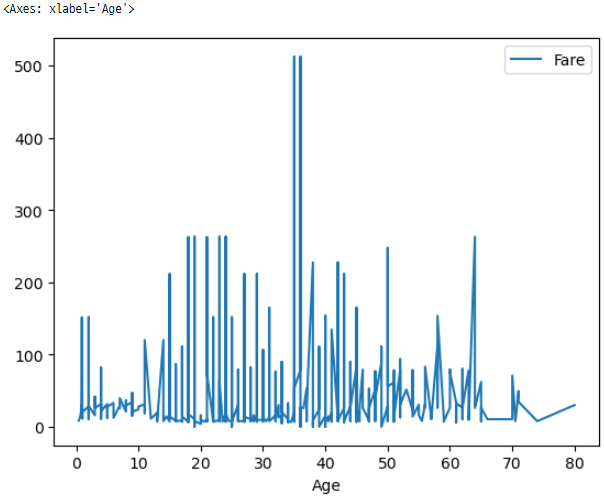
이 코드는 ‘Age’ 열을 x축 값으로, ‘Fare’ 열을 y축 값으로 사용하여 선 그래프를 만듭니다.
89. Pandas 데이터프레임을 사용한 막대 그래프
import pandas as pd
titanicData.groupby('Pclass')[['Fare']].mean().reset_index().plot(x = 'Pclass', y = 'Fare', kind = 'bar')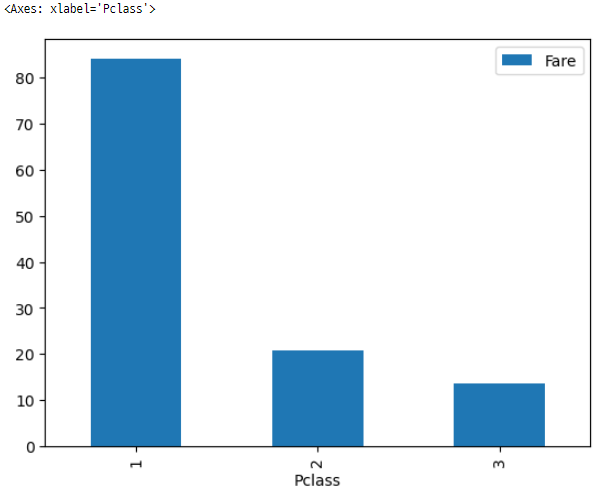
이 코드는 titanicData 의 ‘Pclass’ 열을 그룹으로 ‘Pclass’ 범주별 평균 ‘Fare’을 산출한 후에(titanicData.groupby(‘Pclass’)[[‘Fare’]].mean().reset_index()) 막대 그래프를 생성하는 코드입니다.
90. Pandas 데이터프레임을 사용한 히스토그램
import pandas as pd
titanicData.plot(y = 'Fare', kind = 'hist')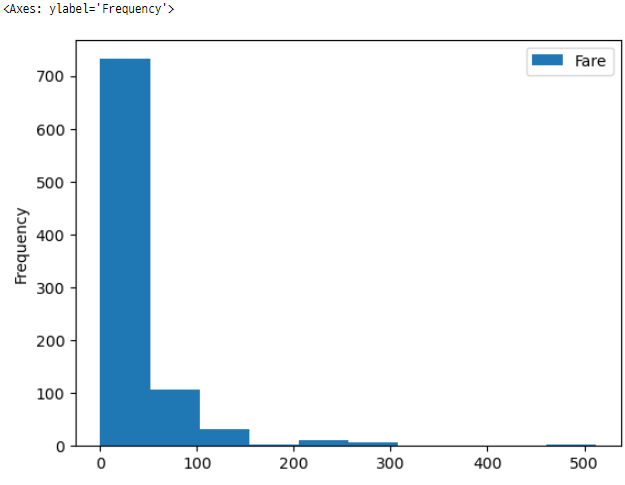
이 코드는 ‘Fare’ 열의 값을 사용하여 히스토그램을 생성하는 코드입니다.
이번 포스팅에서는 Python Pandas 마스터하기 위한 아홉 번째 시간을 가졌습니다( python pandas 마스터하기 81~90 ).
다음 포스팅은 Python Pandas 마스터하기 마지막 포스팅을 작성하겠습니다.
(Python Pandas 마스터하기 91~100 바로가기)
감사합니다!!