이번 포스팅에서는 범주형 데이터 인코딩 방법에 대해 알아보겠습니다. 우선, 범주형 데이터에 대해 간단히 설명하고, 인코딩이 필요한 이유에 대해 예제 데이터와 함께 설명하겠습니다.
범주형 데이터 정의 및 범주형 데이터에 인코딩이 필요한 이유
데이터 세트와 인코딩 방법을 살펴보기 전에 범주형 데이터가 무엇이고 머신 러닝 분야에서 왜 특별한 처리 필요한지 잠시 알아보겠습니다.
범주형 데이터란 무엇인가
범주형 데이터는 우리가 일상생활에서 사용하는 라벨과 같습니다. 범주로 그룹화할 수 있는 특성이나 품질을 나타냅니다.
범주형 데이터에 인코딩이 필요한 이유
대부분의 머신 러닝 알고리즘은 숫자만 인식합니다. “맑음”과 “비”가 다르다는 것을 직접 이해할 수 없습니다. 여기서 인코딩이 등장합니다. 인코딩 이러한 범주를 머신 러닝 알고리즘이 이해하고 작업할 수 있는 언어로 번역하는 것과 같습니다.
범주형 데이터의 유형
일반적으로 두 가지 유형이 있습니다.
- 명목형: 이는 고유한 순서가 없는 범주입니다. 예를 들어, “날씨 전망” (맑음, 흐림, 비)이 여기에 속합니다. 이러한 날씨 조건 사이에는 자연스러운 순서가 없습니다.
- 순서형: 이러한 범주에는 의미 있는 순서가 있습니다. “온도”(매우 낮음, 낮음, 높음, 매우 높음)는 순서형입니다. 가장 추운 것에서 가장 더운 것까지 명확히 순서화하여 정의할 수 있습니다.
적절한 인코딩이 중요한 이유
- 데이터에 중요한 정보를 보존합니다.
- 모델의 성능에 상당한 영향을 미칠 수 있습니다.
- 잘못된 인코딩은 의도치 않은 편향이나 관계를 도입할 수 있습니다.
“맑음”을 1로, “비”를 2로 인코딩한다고 가정하면, 모델은 비오는 날이 맑은 날보다 “더 크다”고 생각할 수 있는데, 이는 우리가 원하는 바가 당연히 아닙니다.
이제 범주형 데이터가 무엇이고 왜 인코딩이 필요한지 이해했으니, 데이터 세트를 살펴보고 여섯 가지 다른 인코딩 방법을 사용하여 범주형 변수를 처리하는 방법에 대해 알아보겠습니다.
범주형 변수를 처리하는 방법
실습을 위해 예제 데이터를 사용하겠습니다.
데이터 세트
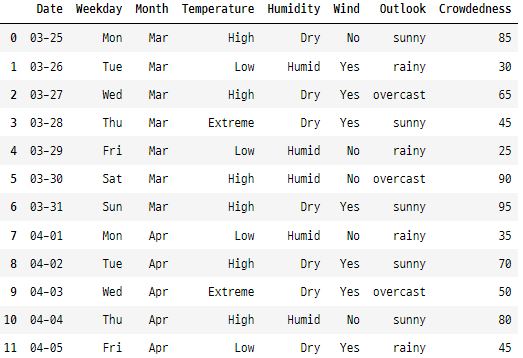
간단한 골프 데이터 세트를 사용하여 인코딩 방법을 설명하겠습니다(대부분 범주형 열이 있습니다). 이 데이터 세트는 다양한 날씨 조건과 골프장의 혼잡도를 나타냅니다.
import pandas as pd
import numpy as np
data = {
'Date': ['03-25', '03-26', '03-27', '03-28', '03-29', '03-30', '03-31', '04-01', '04-02', '04-03', '04-04', '04-05'],
'Weekday': ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri'],
'Month': ['Mar', 'Mar', 'Mar', 'Mar', 'Mar', 'Mar', 'Mar', 'Apr', 'Apr', 'Apr', 'Apr', 'Apr'],
'Temperature': ['High', 'Low', 'High', 'Extreme', 'Low', 'High', 'High', 'Low', 'High', 'Extreme', 'High', 'Low'],
'Humidity': ['Dry', 'Humid', 'Dry', 'Dry', 'Humid', 'Humid', 'Dry', 'Humid', 'Dry', 'Dry', 'Humid', 'Dry'],
'Wind': ['No', 'Yes', 'Yes', 'Yes', 'No', 'No', 'Yes', 'No', 'Yes', 'Yes', 'No', 'Yes'],
'Outlook': ['sunny', 'rainy', 'overcast', 'sunny', 'rainy', 'overcast', 'sunny', 'rainy', 'sunny', 'overcast', 'sunny', 'rainy'],
'Crowdedness': [85, 30, 65, 45, 25, 90, 95, 35, 70, 50, 80, 45]
}
# 골프 데이터 세트 생성
golfData = pd.DataFrame(data)
golfData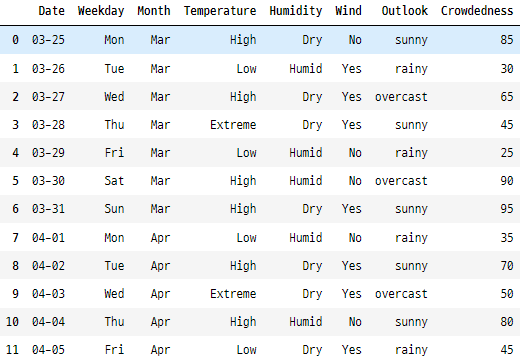
위의 데이터는 많은 범주형 변수를 가지고 있습니다. 이제 이 데이터를 가지고 머신 러닝 모델이 골프장의 혼잡도를 예측할 수 있도록 이러한 변수를 인코딩하겠습니다.
방법 1 – 라벨 인코딩
레이블 인코딩은 범주형 변수의 각 범주에 고유한 정수를 할당합니다. 교육 수준(예: 초등학교, 중학교, 고등학교) 또는 제품 평가(예: 1점, 2점, 3점)와 같이 범주에 명확한 순서가 있는 순서형 변수에 자주 사용됩니다.
골프 데이터 세트의 ‘Weekday’ 열에 라벨 인코딩을 사용할 수 있습니다. 각 요일에 고유한 번호를 할당합니다(예: Mon(월요일) = 0, Tue(화요일) = 1 등). 그러나 Sun(일요일)(6)이 Sat(토요일)(5)보다 “크다”는 것을 의미하지 않습니다.
Mon(월요일) -> 0, Tue(화요일) -> 1, Wed(수요일) -> 2, Thu(목요일) -> 3, Fri(금요일) -> 4, Sat(토요일) -> 5, Sun(일요일) -> 6 으로 인코딩하겠습니다.
golfData['WeekdayLabel'] = pd.factorize(golfData['Weekday'])[0]
golfData[['WeekdayLabel','Weekday']]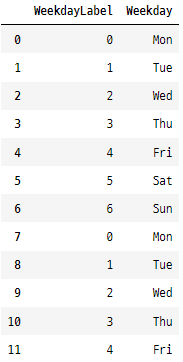
방법 2: 원핫 인코딩
원-핫 인코딩은 범주형 변수의 각 범주에 대해 새로운 이진(binary) 열을 생성합니다. 일반적으로 범주에 고유한 순서가 없는 명목형 변수에 사용합니다. 비교적 적은 수의 범주를 가지는 변수를 처리할 때 유용합니다.
위의 골프 예제 데이터에서 원-핫 인코딩은 ‘Outlook’ 열에 적합해 보입니다. ‘Outlook_sunny’, ‘Outlook_overcast’, ‘Outlook_rainy’라는 세 개의 새 열을 만듭니다. 각 행에는 이러한 열 중 하나에 1이 있고 다른 열에는 0이 있어 해당 날짜의 날씨 상태를 나타냅니다.
| 구분 | Outlook_sunny | Outlook_overcast | Outlook_rainy |
| sunny | 1 | 0 | 0 |
| overcast | 0 | 1 | 0 |
| rainy | 0 | 0 | 1 |
# 2. outlook 변수에 대한 원-핫 인코딩
golfData = pd.get_dummies(golfData, columns = ['Outlook'], prefix = 'Outlook', dtype = int)
golfData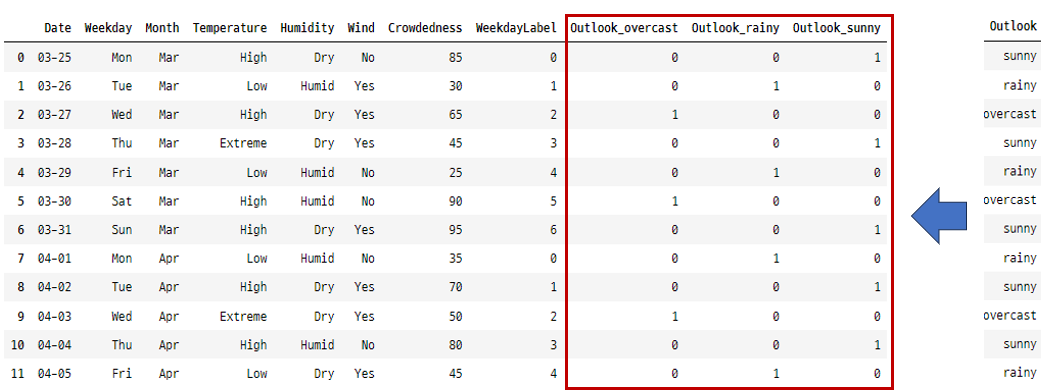
방법 3: 바이너리 인코딩
이진(binary) 인코딩은 각 범주를 이진수(0과 1)로 표현합니다. 두 가지 범주만 있는 경우에 사용합니다. ‘Windy’ 열이 적당해 보입니다. 이진 열이 생성되고, 한 범주(예: No)는 0으로, 다른 범주(Yes)는 1로 표현합니다.
# 3. Wind 변수에 대한 이진 인코딩
golfData['Wind_binary'] = (golfData['Wind'] == 'Yes').astype(int)
golfData[['Wind','Wind_binary']]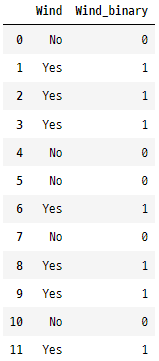
방법 4: 타겟 인코딩
타겟 인코딩은 각 범주를 해당 범주의 평균값으로 대체합니다. 범주형 변수와 타겟 변수 사이에 관계가 있을 가능성이 있을 때 사용합니다.
‘Crowdedness’를 대상으로 사용하여 ‘Humidity’ 열에 타겟 인코딩을 적용할 수 있습니다. ‘Humidity’ 열의 각 ‘Dry’ 또는 ‘Humid’는 각각 습한 날과 건조한 날에 관찰된 평균 혼잡도로 대체됩니다.
# 4. Humidity 변수에 대한 타겟 인코딩
golfData['Humidity_target'] = golfData.groupby('Humidity')['Crowdedness'].transform('mean')
golfData[['Humidity_target','Crowdedness','Humidity_target']]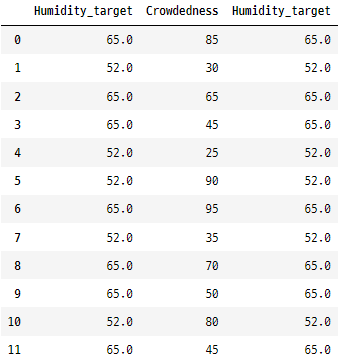
방법 5: 순서 인코딩
순서형 인코딩은 고유한 순서에 따라 순서형 정수를 순서형 범주에 할당합니다. 범주의 순서가 의미 있고, 이 순서 정보를 유지하려는 순서형 변수에 사용됩니다.
순서형 인코딩은 ‘Temperature’ 열에 적용할 수 있습니다. 순서를 나타내는 정수를 할당할 수 있습니다. Low = 1, High = 2, Extreme = 3으로 인코딩 하면 온도 범주의 자연스러운 순서를 유지할 수 있습니다.
# 5. Temperature 변수에 대한 순서 인코딩
tempOrder = {'Low': 1, 'High': 2, 'Extreme': 3}
golfData['Temperature_ordinal'] = golfData['Temperature'].map(tempOrder)
golfData[['Temperature','Temperature_ordinal']]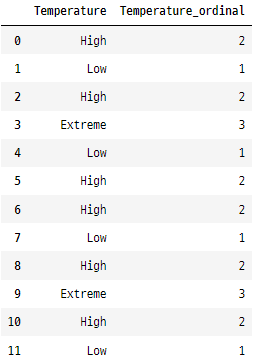
방법 6: 순환 인코딩
순환 인코딩/변환은 순환 범주형 변수를 변수의 순환적 특성을 유지하는 두 개의 숫자적 특징을 가지는 값으로 변환합니다. 일반적으로 사인 및 코사인 변환을 사용하여 순환적 패턴을 나타냅니다.
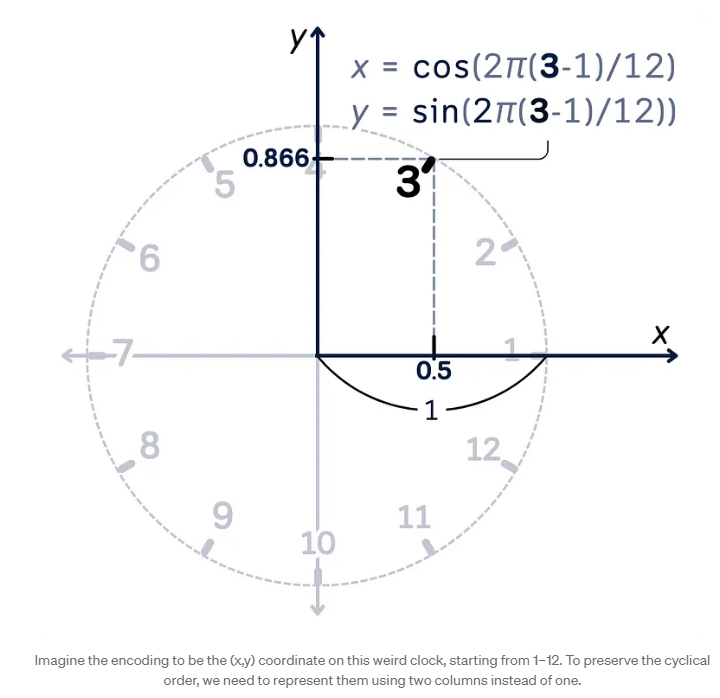
예를 들어, “Mon” 열의 경우 먼저 각 월에 대응하는 숫자를 매핑한 다음(Jan -> 1, Feb ->2,…) 두 개의 새로운 함수를 생성합니다.
- Mon_cos = cos(2π(m-1)/12)
- Mon_sin = sin(2π(m-1)/12)
여기서 m은 1월에서 12월을 나타내는 1에서 12까지의 숫자를 의미합니다.
import numpy as np
# 6. Month 열에 대한 순환 인코딩
monthOrder = {'Jan': 1, 'Feb': 2, 'Mar': 3, 'Apr': 4, 'May': 5, 'Jun': 6,
'Jul': 7, 'Aug': 8, 'Sep': 9, 'Oct': 10, 'Nov': 11, 'Dec': 12}
golfData['MonthNum'] = golfData['Month'].map(monthOrder)
golfData['MonthSin'] = np.sin(2 * np.pi * (golfData['MonthNum']-1) / 12)
golfData['MonthCos'] = np.cos(2 * np.pi * (golfData['MonthNum']-1) / 12)
golfData[['Month','MonthNum','MonthSin','MonthCos']]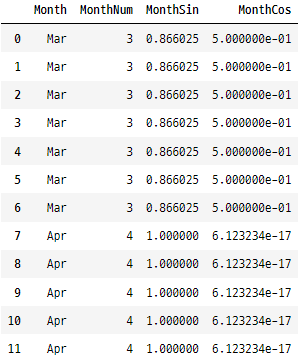
결론
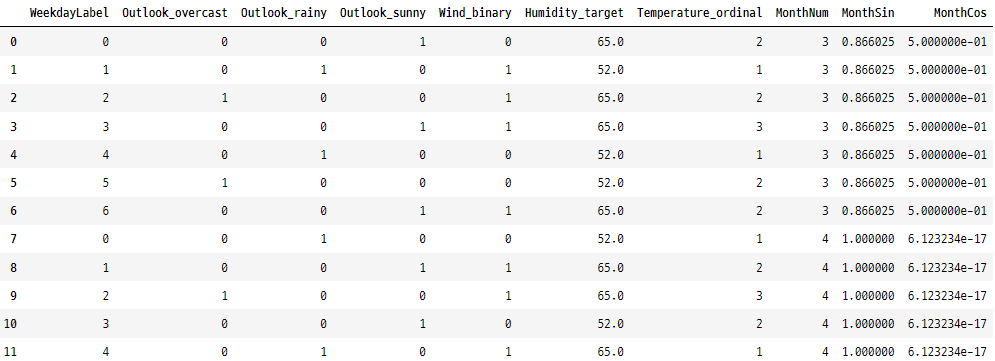
골프장 데이터 세트에 범주형 데이터를 인코딩하는 여섯 가지 다른 방법을 모두 적용하였습니다. 아래 데이터를 보시면, 모든 범주가 숫자로 변환되었음을 확인할 수 있습니다
<변환 전>
<변환 후>
인코딩 방법 요약
각 방법이 데이터를 처리하는 방식입니다.
- 레이블 인코딩: ‘Weekday’을 숫자로 바꾸어 월요일을 0으로, 일요일을 6으로 만들었습니다. 숫자는 단지 범주일 뿐, 월요일이 일요일의 크기 비교 및 측정이 가능하다는 뜻은 아닙니다.
- 원핫 인코딩: ‘Outlook’에 별도의 열을 추가하여 ‘맑음’, ‘흐림’, ‘비’를 독립적으로 두었습니다.
- 이진 인코딩: ‘Humidity’를 효율적인 이진 코드로 압축하여 정보를 잃지 않고 공간을 절약했습니다.
- 타겟 인코딩: ‘Wind’ 범주를 평균 ‘Crowdedness’으로 대체하여 숨겨진 관계를 포착했습니다.
- 순서 인코딩: ‘Temperature’의 자연스러운 순서를 ‘매우 낮음’에서 ‘매우 높음’으로 크기 비교를 표현하였습니다.
- 순환 인코딩: ‘Mon’을 Sin 및 Cos 구성 요소로 변환하여 순환적 특성을 유지했습니다.
범주형 인코딩에는 완벽한 솔루션이 없습니다. 가장 좋은 방법은 데이터, 범주의 특성, 머신 러닝 모델의 요구 사항 등 상황에 따라 달라집니다.
범주형 데이터를 인코딩하는 것은 머신 러닝 프로젝트의 거대한 계획에서 작은 단계처럼 보일 수 있지만, 종종 이러한 사소해 보이는 세부 사항이 모델의 성능을 만들거나 망칠 수 있습니다.
주의: 범주형 인코딩의 주요 고려 사항
이번 포스팅에서는 범주형 데이터 인코딩 방법에 대해 알아보았습니다. 인코딩 방법에 대한 설명을 마무리하면서, 염두에 두어야 할 몇 가지 중요한 사항을 강조해 보겠습니다.
- 정보 손실: 일부 인코딩 방법은 정보 손실을 초래할 수 있습니다. 예를 들어, 레이블 인코딩은 의도치 않은 순서 관계를 부과할 수 있습니다.
- 새로운 범주 문제: 대부분의 인코딩 기술은 테스트 데이터에는 존재하지 않았던 범주에 직면했을 때 이슈가 발생할 수 있습니다. 항상 이러한 예상치 못한 데이터를 처리할 수 있게 인코딩해야 합니다.
- 차원성의 저주: 원핫 인코딩과 같은 기술은 피처 수를 매우 극단적으로 늘릴 수 있습니다.
- 문서화: 인수인계를 위해 인코딩 결정을 명확하게 기록해야 합니다. 이러한 투명성은 재현성과 결과의 잠재적 편향을 이해하기 위한 것입니다.
따라서 인코딩은 범주형 데이터를 기계가 이해할 수 있는 언어로 번환하는 동시에 가능한 한 많은 의미를 보존해야 합니다. 완벽한 인코딩을 찾는 것이 아니라, 특정 요구 사항과 제약에 가장 적합한 방법을 선택해야 합니다.
신중하게 접근하면 머신 러닝 작업의 배경지식에 대한 강력한 기반을 가지고 있어야 합니다.