이번 포스팅에서는 파이썬을 활용한 데이터 전처리 방법에 대해서 알아보겠습니다. 실습에 활용할 데이터는 구인공고 데이터(indeed_job_data.csv) 입니다.
데이터 전처리를 위한 실습 데이터 확인
# 필수 라이브러리 임포트
import pandas as pd
import numpy as np
import re
# D드라이브에 있는 indeed_job_data.csv 데이터 읽어들이기
job = pd.read_csv('D:/indeed_job_data.csv')
# 데이터 확인
job.head()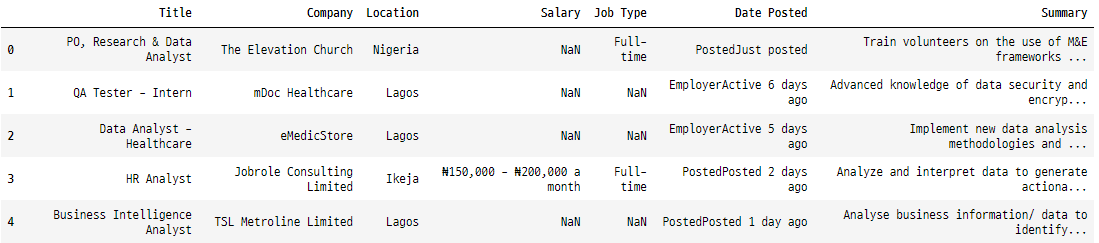
# 데이터 세트에 대한 정보 확인
job.info()
----------------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 203 entries, 0 to 202
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Title 203 non-null object
1 Company 200 non-null object
2 Location 203 non-null object
3 Salary 15 non-null object
4 Job Type 101 non-null object
5 Date Posted 203 non-null object
6 Summary 203 non-null object
dtypes: object(7)
memory usage: 11.2+ KB데이터 행은 203개, 열은 7개입니다. 모든 열은 객체(문자열) 데이터 유형으로 되어 있습니다. 급여(salary)와 게시 날짜(Date Posted)의 데이터 유형은 각각 float와 Datetime이어야 합니다. 결측치도 존재합니다.
데이터 전처리
데이터 전처리 작업은 아래 5가지 입니다.
- 결측치 처리: 특히 급여(salary), 회사(Company), 직무 유형(Job Type)과 같은 열에서 데이터 세트의 결측치를 식별하고 처리합니다.
- 급여에서 숫자 값 추출: 급여 열에서 숫자 값을 추출하여 통화 기호, 텍스트 또는 공백을 제거하고 급여 범위를 처리하는 등 통일된 형식으로 변환합니다.
- ‘직무 유형’ 열의 일관되지 않은 값을 교체합니다.
- 게시 날짜 구문 분석: 게시 날짜 열을 구문 분석하여 날짜를 일관된 형식(예: YYYY-MM-DD)으로 변환합니다.
- 요약(Summary) 열 표준화: 일관성을 보장하기 위해 요약 열을 표준화합니다. 예를 들어 선행/후행 공백을 제거하고 인코딩 문제를 수정합니다(예: …와 같은 문자 수정).
결측치 처리
# 결측치 확인
missingValues = job.isnull().sum()
print("Missing Values:\n", missingValues)
------------------------------------------------
Missing Values:
Title 0
Company 3
Location 0
Salary 188
Job Type 102
Date Posted 0
Summary 0
dtype: int64데이터 세트의 각 열에서 누락된 값의 수를 보여줍니다.
# Company 열의 결측치를 'Unknown'으로 대체
job['Company'].fillna('Unknown', inplace = True)
# Job Type 열의 결측치를 'Unknown'으로 대체
job['Job Type'].fillna('Unknown', inplace = True)급여에서 숫자 값 추출
# Salary 열의 고유한 값 확인
job["Salary"].unique()
----------------------------------------------------------------------------------
array([nan, '₦150,000 - ₦200,000 a month', '₦100,000 - ₦150,000 a month',
'₦200,000 a month', '₦70,000 - ₦150,000 a month',
'₦90,000 - ₦130,000 a month', '₦300,000 - ₦350,000 a month',
'₦450,000 - ₦600,000 a month', '₦200,000 - ₦250,000 a month',
'₦220,000 a month', '₦60,000 - ₦80,000 a month'], dtype=object)# 나이라 기호, 쉼표, 공백 및 숫자가 아닌 문자 제거
job['Salary'] = job['Salary'].str.replace('[₦,a-zA-Z\s]', '', regex = True)
job["Salary"].unique()
----------------------------------------------------------------------------------
array([nan, '150000-200000', '100000-150000', '200000', '70000-150000',
'90000-130000', '300000-350000', '450000-600000', '200000-250000',
'220000', '60000-80000'], dtype=object)# 범위 내의 값을 평균으로 변환
def convert_to_average(salary):
if isinstance(salary, str) and '-' in salary:
# 하위 및 상위 범위 값 추출
lower, upper = map(int, salary.split('-'))
return (lower + upper) / 2
else:
return salary
job['Salary'] = job['Salary'].apply(convert_to_average)
job["Salary"].unique()
----------------------------------------------------------------------------------
array([nan, 175000.0, 125000.0, '200000', 110000.0, 325000.0, 525000.0,
225000.0, '220000', 70000.0], dtype=object)# 숫자형으로 변환
job['Salary'] = job['Salary'].astype(float)
job["Salary"].unique()
----------------------------------------------------------------------------------
array([ nan, 175000., 125000., 200000., 110000., 325000., 525000.,
225000., 220000., 70000.])# Salary의 결측치를 중앙값(median)으로 대체
job['Salary'].fillna(job['Salary'].median(), inplace = True)
job["Salary"].unique()
----------------------------------------------------------------------------------
array([175000., 125000., 200000., 110000., 325000., 525000., 225000.,
220000., 70000.])Salary 열에 대해서 수행한 데이터 정리 프로세스는 다음과 같습니다.
- ‘Salary’ 열에서 고유한 값을 검색하여 급여 데이터 분포를 파악합니다.
- 정규 표현식을 사용하여 나이라 기호, 쉼표, 공백 및 숫자가 아닌 문자를 제거하여 ‘급여’ 열을 정리합니다.
- 급여 범위를 평균 값으로 변환하여 보다 정확한 표현을 제공합니다.
- 정리된 급여 값을 부동 소수점으로 캐스팅하여 숫자 형식으로 변환합니다.
- ‘급여’ 열에 남아 있는 누락된 값을 중간 급여로 채웁니다.
- 마지막으로 ‘급여’ 열에서 고유한 값을 다시 검색하여 정리 및 변환 프로세스를 확인합니다.
# 결측치 확인
missing_values = job.isnull().sum()
print("Missing Values:\n", missing_values)
----------------------------------------------------
Missing Values:
Title 0
Company 0
Location 0
Salary 0
Job Type 0
Date Posted 0
Summary 0
dtype: int64결측치를 처리한 후 이전 코드를 다시 실행하면 이제는 더 이상 결측치가 남아 있지 않습니다.
급여에서 숫자 값 추출
# 'Job Type' 열의 고유한 값 확인
job['Job Type'].unique()
-------------------------------------------------------------------------------
array(['Full-time', 'Unknown', 'Temporary', 'Full-time +1', 'Contract',
'Permanent'], dtype=object)# 'Job Type' 열의 일관되지 않은 값 대체
job['Job Type'] = job['Job Type'].replace({'Contract +1': 'Contract', 'Full-time +1': 'Full-time'})
job['Job Type'].unique()
--------------------------------------------------------------------------------------------------------------
array(['Full-time', 'Unknown', 'Temporary', 'Contract', 'Permanent'],
dtype=object)
게시일자(Date Posted) 분석
# 게시일자(Date Posted) 의 이상치 대체
job['Date Posted'] = job['Date Posted'].str.replace('Posted', '')
job['Date Posted'] = job['Date Posted'].str.replace('EmployerActive', '')
job['Date Posted'] = job['Date Posted'].str.replace('Today', '0 days ago')
job['Date Posted'] = job['Date Posted'].str.replace('Just posted', '0 days ago')
job['Date Posted'].unique()
# "30+ days ago"을 처리하기 위한 사용자 정의 함수 정의
def convert_to_date(value):
if '+' in value:
return pd.Timestamp.now().normalize() - pd.Timedelta(days = 30)
else:
return pd.Timestamp.now().normalize() - pd.Timedelta(days = int(value.split()[0]))
job['Date Posted'] = job['Date Posted'].apply(convert_to_date)
job['Date Posted'].unique
-------------------------------------------------------------------------------------------------------
array(['2024-08-15T00:00:00.000000000', '2024-08-09T00:00:00.000000000',
'2024-08-10T00:00:00.000000000', '2024-08-13T00:00:00.000000000',
'2024-08-14T00:00:00.000000000', '2024-07-16T00:00:00.000000000',
'2024-07-20T00:00:00.000000000', '2024-08-03T00:00:00.000000000',
'2024-07-22T00:00:00.000000000', '2024-08-08T00:00:00.000000000',
'2024-07-27T00:00:00.000000000', '2024-07-28T00:00:00.000000000',
'2024-07-21T00:00:00.000000000', '2024-08-02T00:00:00.000000000',
'2024-07-26T00:00:00.000000000', '2024-08-07T00:00:00.000000000',
'2024-08-01T00:00:00.000000000', '2024-08-04T00:00:00.000000000',
'2024-08-11T00:00:00.000000000', '2024-07-17T00:00:00.000000000',
'2024-07-18T00:00:00.000000000', '2024-08-05T00:00:00.000000000',
'2024-07-25T00:00:00.000000000', '2024-07-19T00:00:00.000000000',
'2024-07-31T00:00:00.000000000', '2024-08-12T00:00:00.000000000',
'2024-08-06T00:00:00.000000000', '2024-07-30T00:00:00.000000000',
'2024-07-24T00:00:00.000000000'], dtype='datetime64[ns]')‘Summary’ 열 표준화
# 특수문자 및 비문자 제거 함수
def clean_summary(summary):
# 문자가 아닌 문자와 일치하도록 정규 표현식 패턴 정의
pattern = r'[^a-zA-Z\s]'
# 문자가 아닌 문자를 공백으로 바꾸기
cleaned_summary = re.sub(pattern, ' ', summary)
# 추가 공백 제거
cleaned_summary = ' '.join(cleaned_summary.split())
return cleaned_summary
# 'summary' 열에 clean_summary 함수 적용
job['Summary'] = job['Summary'].apply(clean_summary)
# 데이터 확인
job.head()
job.info()
----------------------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 203 entries, 0 to 202
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Title 203 non-null object
1 Company 203 non-null object
2 Location 203 non-null object
3 Salary 203 non-null float64
4 Job Type 203 non-null object
5 Date Posted 203 non-null datetime64[ns]
6 Summary 203 non-null object
dtypes: datetime64[ns](1), float64(1), object(5)
memory usage: 11.2+ KB# 전처리 완료한 데이터를 CSV 파일로 저장
job.to_csv("D:/cleaned_job_data.csv", index = False)다음 포스팅에서는 위에서 생성한 전처리 완료된 데이터를 활용하여 탐색적 자료 분석을 수행하겠습니다.
감사합니다.