이번 포스팅에서는 파이썬의 판다스 데이터프레임과 다른 유형의 데이터구조 간의 데이터 변환 방법에 대해서 알아보겠습니다.
판다스를 사용하면 Excel, CSV, 데이터베이스와 같은 다양한 소스에서 데이터를 읽어 데이터프레임을 구성할 수 있습니다. 때로는 데이터가 이러한 외부에서 나오지 않고 리스트나 딕셔너리와 같은 기존 판다스 데이터 구조에서 나오는 경우도 있습니다.
데이터프레임을 내보내야 할 때 항상 외부 파일에 쓸 필요는 없습니다. 파이썬의 딕셔너리나 리스트를 생성하고 싶을 수도 있습니다. 이를 어떻게 처리해야 할까요?
하나씩 살펴보겠습니다.
데이터프레임을 내장 데이터 구조로 변환
다음과 같은 데이터프레임이 있다고 가정해 보겠습니다.
import pandas as pd
df = pd.DataFrame({"product": ["Laptop", "Smartphone", "Tablet"],
"price": [1500, 800, 600],
"quantity": [5, 10, 7]})
df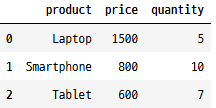
이제 데이터프레임이 제공하는 메서드와 이를 파이썬에 내장된 데이터 구조로 변환한 후의 모습을 살펴보겠습니다.
df.to_records()
이 방법은 데이터프레임을 넘파이 배열로 변환하는데 사용되며, 배열의 각 요소는 튜플 형식입니다.
# 인덱스를 포함하는 출력
print(df.to_records())
------------------------------------------------------------------------
[(0, 'Laptop', 1500, 5) (1, 'Smartphone', 800, 10)
(2, 'Tablet', 600, 7)]
# 인덱스 없이 출력
print(df.to_records(index = False))
------------------------------------------------------------------------
[('Laptop', 1500, 5) ('Smartphone', 800, 10) ('Tablet', 600, 7)]
# 인덱스 없이 리스트로 변환하여 출력
print(df.to_records(index = False).tolist())
------------------------------------------------------------------------
[('Laptop', 1500, 5), ('Smartphone', 800, 10), ('Tablet', 600, 7)]이런 유형의 데이터 구조는 매우 흔하고 실무에서 자주 사용됩니다.
df.to_dict()
이 방법은 데이터프레임을 파이썬 딕셔너리 구조로 변환합니다.
# 딕셔너리(키 -> 칼럼명 , 값 -> 대응되는 칼럼) 반환
print(df.to_dict())
---------------------------------------------------------------------------------------------------------------------------------
{'product': {0: 'Laptop', 1: 'Smartphone', 2: 'Tablet'}, 'price': {0: 1500, 1: 800, 2: 600}, 'quantity': {0: 5, 1: 10, 2: 7}}
# 딕셔너리에서 인덱스 제거
print(
{k: tuple(v.values()) for k, v in df.to_dict().items()}
)
---------------------------------------------------------------------------------------------------------------------------------
{'product': ('Laptop', 'Smartphone', 'Tablet'), 'price': (1500, 800, 600), 'quantity': (5, 10, 7)}
# 각 열을 튜플로 변환하여 to_dict() 구현
print(
{col: tuple(df[col]) for col in df.columns}
)
---------------------------------------------------------------------------------------------------------------------------------
{'product': ('Laptop', 'Smartphone', 'Tablet'), 'price': (1500, 800, 600), 'quantity': (5, 10, 7)}이 형식의 데이터는 많이 사용되지 않습니다. 다음 형식이 더 자주 사용됩니다.
df.to_dict(orient=”records”)
이 방법은 데이터프레임을 파이썬 리스트로 변환하는데, 리스트의 각 요소는 각 데이터 행을 나타내는 딕셔너리입니다.
# 데이터프레임을 리스트로 변환(리스트 요소: 데이터 행을 나타내는 딕셔너리)
print(df.to_dict(orient = "records"))
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
[{'product': 'Laptop', 'price': 1500, 'quantity': 5}, {'product': 'Smartphone', 'price': 800, 'quantity': 10}, {'product': 'Tablet', 'price': 600, 'quantity': 7}]내장된 데이터 구조를 데이터프레임으로 변환
내장된 데이터 구조를 데이터프레임으로 변환하는 가장 일반적인 사례를 알아보겠습니다.
import pandas as pd
data = [{'product': 'Laptop', 'price': 1500, 'quantity': 5},
{'product': 'Smartphone', 'price': 800, 'quantity': 10},
{'product': 'Tablet', 'price': 600, 'quantity': 7}]
print(pd.DataFrame.from_records(data))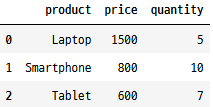
# pd.DataFrame을 직접 호출
pd.DataFrame(data)# 리스트에 있는 딕셔너리에 동일한 키가 없다면?
data[2]["discount"] = 50 # 딕셔너리 마지작에 새로운 키 추가
pd.DataFrame(data)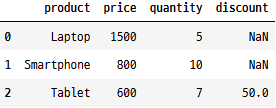
이는 단순히 사전에 있는 모든 키를 고려합니다. 특정 행에 지정된 키가 없는 경우 해당 값은 NaN이 됩니다.
물론, 데이터는 다음과 같은 형식일 수도 있습니다.
import pandas as pd
data = {'2024-10-01': {'product': 'Laptop', 'price': 1500, 'quantity': 5},
'2024-10-02': {'product': 'Smartphone', 'price': 800, 'quantity': 10},
'2024-10-03': {'product': 'Tablet', 'price': 600, 'quantity': 7}}
# 날짜를 키로 하는 딕셔너리에서 데이터프레임 생성
# The orient="index" 매개변수는 키를 인덱스로 사용
pd.DataFrame.from_dict(data, orient="index")
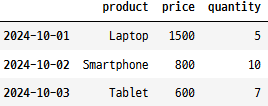
마지막 유형의 데이터 변환입니다.
import pandas as pd
data = {'product': ['Laptop', 'Smartphone', 'Tablet'],
'price': [1500, 800, 600],
'quantity': [5, 10, 7]}
# 데이터프레임을 호출하여 딕셔너리에서 데이터프레임을 생성
pd.DataFrame(data)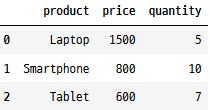
결론
이번 포스팅에서는 파이썬을 활용하여 데이터구조 간의 데이터 변환 방법에 대해서 알아보았습니다.