결측치(Missing Data)는 모든 실제 데이터에서 거의 불가피하게 존재하며 일반적인 데이터 수집 과정에서 피할 수 없습니다. 이는 데이터 입력 중 오류, 데이터 수집 프로세스의 기술적 문제, 손실/손상된 파일 및 기타 다양한 이유로 발생할 수 있습니다. 실제 데이터 세트에는 일반적으로 데이터 과학자와 기계 학습 엔지니어가 처리해야 하는 일부 결측치 데이터가 있습니다. 만약, 결측치를 적당한 방법으로 처리하지 않으면 잠재적으로 데이터 파이프라인을 개발하는 데 몇 가지 문제가 발생할 수 있습니다.
따라서 이번 포스팅에서는 데이터 기반 프로젝트에서 결측치를 처리하고 데이터 파이프라인을 구축하는 동안 발생할 수 있는 결측치를 제거하는 데 사용할 수 있는 몇 가지 기술에 대해서 알아 보겠습니다.
포스팅의 목차는 다음과 같습니다.
결측치(Missing Data)를 처리해야 하는 이유
결측치 문제를 해결하기 전에 먼저 누락된 데이터를 처리해야 하는 이유를 이해하는 것이 중요합니다. 데이터는 실제로 모든 데이터 과학 및 기계 학습 프로젝트의 주요 원동력이고, 기계가 결정을 내리게 되는 모든 프로젝트의 핵심 요소입니다. 결측치의 존재는 정말 실망스러울 수 있지만 데이터 세트에서 완전히 제거하는 것이 항상 올바른 진행 방법은 아닐 수 있습니다. 아래 예시를 보시죠.
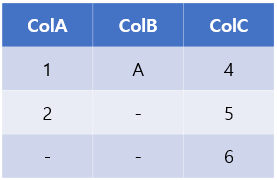
결측치가 하나 이상 있는 모든 행을 제거하는 것을 고려하는 경우,
1) 데이터 세트의 데이터 포인트 수를 줄입니다.
위의 예시 데이터에서 결측값이 포함된 행을 완전히 제거하면 데이터 세트의 행 수가 크게 줄어 1개의 데이터만 남게 됩니다.
2) 결측치가 아닌 다른 정확한 정보의 손실로 이어집니다.
예를 들어, 위의 DataFrame에서 가운데 행 ColB 값이 관찰되지 않았더라도 우리는 여전히 데이터 파이프라인에 매우 중요할 수 있는 ColA 및 ColC의 해당 값을 정확하게 알고 있습니다.
결측치 처리
앞에서 결측치를 처리해야 하는 이유에 대해서 알아 보았고, 이제 결측치를 처리하는 기술적 측면에 대해서 알아 보겠습니다.
테이블 형식 데이터에서 누락된 값이 발생할 때마다 기본적으로 아래와 같이 세 가지 옵션 중 하나를 결측치 처리 방법으로 선택할 수 있습니다.
결측치 유지
이름에서 알 수 있듯이 이 방법은 데이터 세트에서 결측치의 존재를 완전히 무시합니다.
이 경우 데이터세트 변환 방법은 결측치를 데이터로 간주하고, 데이터의 복사본을 반환하는 것입니다.
그러나 이러한 방법을 활용하기 위해서는 결측치가 데이터 파이프라인에서 문제를 일으키지 않으며 알고리즘이 결측치를 처리하는 데 문제가 되지 않는다고 가정해야 합니다.
따라서 결측치가 그대로 남아 있는 경우 알고리즘이 작동할 수 있는지 여부를 결정하는 것은 데이터 과학자 또는 기계 학습 엔지니어의 판단입니다.
누락된 데이터를 그대로 유지하는 방법은 아래에 정의되어 있습니다. 우리는 소스 DataFrame을 인수로 취하고 변환하지 않고 반환하는 handle_missing_data() 함수를 정의합니다.
def handle_missing_data(df):
ooooreturn df
import pandas as pd
import numpy as np
df = pd.DataFrame([[1, “A”, 4], [2, np.nan, 7], [np.nan, np.nan, 5]],
columns = [“colA”, “colB”, “colC”])
print(df)
dfNew = handle_missing_data(df)
print(dfNew)
colA colB colC 0 1.0 A 4 1 2.0 NaN 7 2 NaN NaN 5 colA colB colC 0 1.0 A 4 1 2.0 NaN 7 2 NaN NaN 5
위의 구현에서 볼 수 있듯이 원래 DataFrame은 변경되지 않은 상태로 유지됩니다.
결측치 삭제
다음으로 위에서 설명한 것처럼 결측치를 유지하는 것이 특정 사용 사례에 적합하지 않은 경우, 결측치를 모두 삭제하는 것이 진행 방향일 수 있습니다. 여기서의 아이디어는 결측치가 있는 DataFrame에서 전체 행(또는 사용 사례에 시리즈 기반 분석이 필요한 경우 열)을 제거하는 것입니다. 즉, 이 기술에서는 모든 열(또는 행)에 해당하는 null이 아닌 값이 있는 데이터의 행(또는 열)만 유지하고, 나머지는 모두 삭제합니다.
행 단위 삭제
이름에서 알 수 있듯이 여기의 목표는 결측치가 포함된 DataFrame의 행을 삭제하는 것입니다. 위의 예시 데이터에서는 첫번째 행만 남게 되는 것이죠. 열의 수는 행 단위 삭제 처리에서는 동일하게 유지됩니다.
열 단위 삭제
행 단위 삭제와 달리 열 단위 삭제에는 결측치가 포함된 DataFrame의 열(또는 계열)을 제거합니다. 위의 예시 데이터에서는 “ColC” 만 남게 되는 것이죠. 열 기준 삭제에서 행 수는 동일하게 유지됩니다.
구현
결측치가 있는 DataFrame에서 행(또는 열)을 삭제하는 handle_missing_data() 함수를 구현해 보겠습니다. 아래와 같이 dropna() 메서드를 사용하여 DataFrame에서 행을 삭제할 수 있습니다.
def handle_missing_data(df, axis = 0):
return df.dropna(axis = axis)
axis 인수는 DataFrame에서 누락된 값을 삭제하려는 방향(행 방향 또는 열 방향)을 지정합니다.
- axis=0은 행 중심 삭제를 수행합니다. 아래 코드를 보시죠.
df = pd.DataFrame([[1, “A”, 4], [2, np.nan, 7], [np.nan, np.nan, 5]],
columns = [“colA”, “colB”, “colC”])
print(df)
dfNew = handle_missing_data(df)
print(dfNew)
colA colB colC 0 1.0 A 4 1 2.0 NaN 7 2 NaN NaN 5 colA colB colC 0 1.0 A 4
- axis=1은 아래 코드와 같이 열 방향 삭제를 수행합니다.
df = pd.DataFrame([[1, “A”, 4], [2, np.nan, 7], [np.nan, np.nan, 5]],
columns = [“colA”, “colB”, “colC”])
print(df)
dfNew = handle_missing_data(df, axis = 1)
print(dfNew)
colA colB colC 0 1.0 A 4 1 2.0 NaN 7 2 NaN NaN 5 colC 0 4 1 7 2 5
결측치 채우기
마지막 기법은 아래와 같이 결측치에 대해 가장 잘 추정된 추측이 될 수 있는 합리적인 값으로 결측치를 채우는 것입니다.
전략에는 열의 값 유형에 따라 열의 평균, 중앙값 또는 열의 가장 빈번한 값(모드)으로 누락된 데이터를 채우는 작업이 포함될 수 있습니다. Mean, Median 및 Mode는 숫자 값에 대해서만 추정할 수 있기 때문입니다. 그러나 범주 열의 경우 평균과 중앙값은 의미가 없습니다.
또한 채우기 기준은 전적으로 특정 데이터 소스, 해결하려는 문제 및 누락된 특정 데이터 포인트를 평가하는 것이 얼마나 편한지에 따라 달라집니다.
구현
결측치에 대해 가장 잘 추정된 합리적인 값을 찾기 위해 가장 일반적으로 사용되는 기술 중에는 Mean, Median 및 Mode가 있으며 아래의 코드를 보면서 설명 하겠습니다.
평균값으로 채우기
평균값으로 채우는 전략은 결측치를 열의 평균값으로 바꿉니다.
df = pd.DataFrame([[1, “A”, 4], [2, np.nan, 7], [np.nan, np.nan, 5]],
columns = [“colA”, “colB”, “colC”])
print(df)
dfNew = df.fillna(df.mean())
print(dfNew)
colA colB colC 0 1.0 A 4 1 2.0 NaN 7 2 NaN NaN 5 colA colB colC 0 1.0 A 4 1 2.0 NaN 7 2 1.5 NaN 5
위에서 설명한 것처럼 평균값으로 채우는 전략은 colB의 누락된 값을 대체하지 않았습니다.
중앙값으로 채우기
다음으로 중앙값으로 채우는 전략은 열의 결측치를 중앙값으로 바꿉니다. 아래를 보시죠.
df = pd.DataFrame([[1, “A”, 4], [2, np.nan, 7], [np.nan, np.nan, 5]],
columns = [“colA”, “colB”, “colC”])
print(df)
dfNew = df.fillna(df.median())
print(dfNew)
colA colB colC 0 1.0 A 4 1 2.0 NaN 7 2 NaN NaN 5 colA colB colC 0 1.0 A 4 1 2.0 NaN 7 2 1.5 NaN 5
colB의 결측치는 여전히 NaN 값으로 채워져 있습니다.
최빈값으로 채우기
마지막으로 mode 값을 채우면 결측치가 아래와 같이 열의 가장 빈번한 값으로 대체됩니다.
df = pd.DataFrame([[1, “A”, 4], [2, np.nan, 7], [np.nan, np.nan, 5]],
columns = [“colA”, “colB”, “colC”])
print(df)
dfNew = df.fillna(df.mode().iloc[0])
print(dfNew)
colA colB colC 0 1.0 A 4 1 2.0 NaN 7 2 NaN NaN 5 colA colB colC 0 1.0 A 4 1 2.0 A 7 2 1.0 A 5
아래에 설명된 것처럼 열 별로 다른 채우기 전략을 적용할 수도 있습니다.
df = pd.DataFrame([[1, “A”, 4], [2, np.nan, 7], [np.nan, np.nan, 5]],
columns = [“colA”, “colB”, “colC”])
print(df)
dfNew = df.fillna({“colA”:df[‘colA’].mean(), “colB”: df[‘colB’].mode().iloc[0]})
print(dfNew)
colA colB colC 0 1.0 A 4 1 2.0 NaN 7 2 NaN NaN 5 colA colB colC 0 1.0 A 4 1 2.0 A 7 2 1.5 A 5
colA의 결측치는 평균으로 채우고,
colB의 결측치는 최빈값으로 채웠습니다.
결론
이번 포스팅에서는 Pandas DataFrame에서 누락된 데이터를 처리하는 방법에 대해서 알아 보았습니다. 결측치를 처리하는 것이 데이터 파이프라인에 필수적인 이유와 누락된 데이터를 처리하기 위해 일반적으로 사용되는 전략을 살펴보았습니다. 결측치를 처리할 때 이번 포스팅에서 논의한 세 가지 방법(Keep, Drop 및 Fill) 중 올바른 접근 방식은 없음을 염두에 두어야 합니다. 케이스마다 다르기 때문입니다. 상황에 따라 특정 방법을 선택하는 것은 항상 분석자의 선택에 달려 있습니다.