이번 포스팅에서는 데이터 시각화를 활용한 탐색적 자료 분석 방법에 대해서 알아 보겠습니다.
뉴욕시 Airbnb 데이터를 활용한 탐색적 자료 분석의 세번째 포스팅입니다. 포스팅 글을 읽기 전에 뉴욕시 Airbnb 데이터를 활용한 탐색적 자료 분석 1 (with Python) 과 뉴욕시 Airbnb 데이터를 활용한 탐색적 자료 분석 2 (with Python) 을 순차적으로 먼저 학습하여 파이썬 코드를 실행하시기 바랍니다. 그렇지 않으면 아래 포스팅 글의 파이썬 코드들이 모두 에러가 발생합니다.
그럼 뉴욕시 Airbnb 데이터를 활용한 탐색적 자료 분석 세번째 단계로 위치 기반의 데이터 시각화를 활용한 탐색적 자료 분석 방법에 대해서 알아 보겠습니다.
뉴욕에서 가장 물가가 비싼 지역에 위치한 아파트
아래 코드를 활용하면 뉴욕에서 가장 비싼 지역에 있는 50개 부동산 위치를 시각적으로 보여줍니다.
지도의 각 핀은 부동산을 나타냅니다. 부동산이 지역 전체에 분산 되어 있어,
고가 부동산이 해당 지역 내 특정 지역에 집중되어 있는 것이 아니라 전체적으로 분산되어 있음을 알 수 있습니다.
# 가장 비용이 많이 드는 지역 데이터에서 50개 데이터 표본 추출
dataSample = airbnbData.sort_values(by = 'price', ascending = False).iloc[:50,].sample(50, random_state=1)
# 지도 객체 생성
mapSample = fl.Map(location = [dataSample.latitude.iloc[0], dataSample.longitude.iloc[0]], zoom_start = 14, control_scale = True)
# Add markers to the map
for _, locationInfo in dataSample.iterrows():
markerLocation = [locationInfo['latitude'], locationInfo['longitude']]
markerPopup = locationInfo['neighbourhood']
fl.Marker(location = markerLocation, popup = markerPopup).add_to(mapSample)
# 지도 출력
mapSample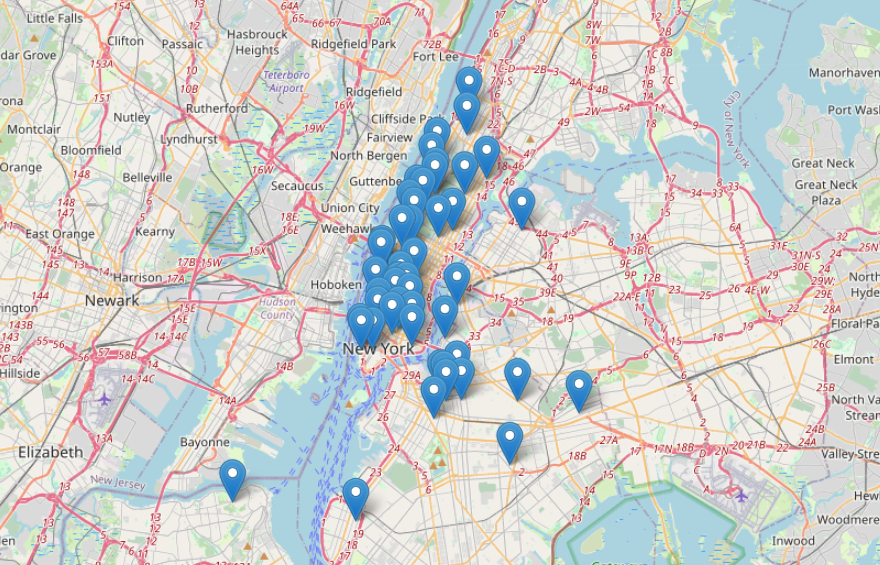
이러한 종류의 시각화는 부동산의 지리적 분포를 이해하는 데 매우 효과적입니다.
부동산 가격 및 위치와 관련된 패턴에 대한 인사이트를 제공할 수 있습니다.
예를 들어, 고가의 부동산이 특정 편의 시설이나 랜드마크에 더 가깝다는 것을 알 수 있습니다.
부동산 가격 상위 50개의 샘플에 대한 결과이므로 해당 지역의 부동산 분포에 대한 전체 그림을 나타내지 않을 수도 있다는 점에 유의하는 것이 중요합니다.
보다 정확한 이해를 위해서는 더 큰 샘플이나 전체 데이터세트를 사용하여 대표성을 높혀야 합니다.
유형별 부동산 위치
아래 코드로 산출되는 지도는 데이터 세트에서 무작위로 추출한 50개 부동산 표본 기반으로 뉴욕시의 다양한 유형의 부동산 분포를 지리적으로 표현하고 있습니다.
# 열 선택 및 50개 행 샘플링
columns = ['neighbourhood_group', 'room_type', 'latitude', 'longitude']
dataPlot = airbnbData.loc[:, columns].sample(50, random_state = 1)
# 'color'라는 새로운 열 생성
dataPlot.loc[:, 'color'] = 'NA'
# 각 객실 유형에 대한 조건 정의
rowsPrivateRoom = dataPlot.loc[:, 'room_type'] == 'Private room'
rowsEntireApt = dataPlot.loc[:, 'room_type'] == 'Entire home/apt'
rowsSharedRoom = dataPlot.loc[:, 'room_type'] == 'Shared room'
# 객실 유형에 따라 색상 지정
dataPlot.loc[rowsPrivateRoom, 'color'] = 'darkgreen'
dataPlot.loc[rowsEntireApt, 'color'] = 'darkred'
dataPlot.loc[rowsSharedRoom, 'color'] = 'purple'
# 지도 그리기
map = fl.Map(location = [dataPlot.latitude.iloc[0], dataPlot.longitude.iloc[0]], zoom_start = 14, control_scale = True)
for index, locationInfo in dataPlot.iterrows():
fl.Marker(
[locationInfo['latitude'], locationInfo['longitude']],
popup = locationInfo[['neighbourhood_group', 'room_type']].to_string(),
icon = fl.Icon(color = locationInfo['color'])
).add_to(map)
map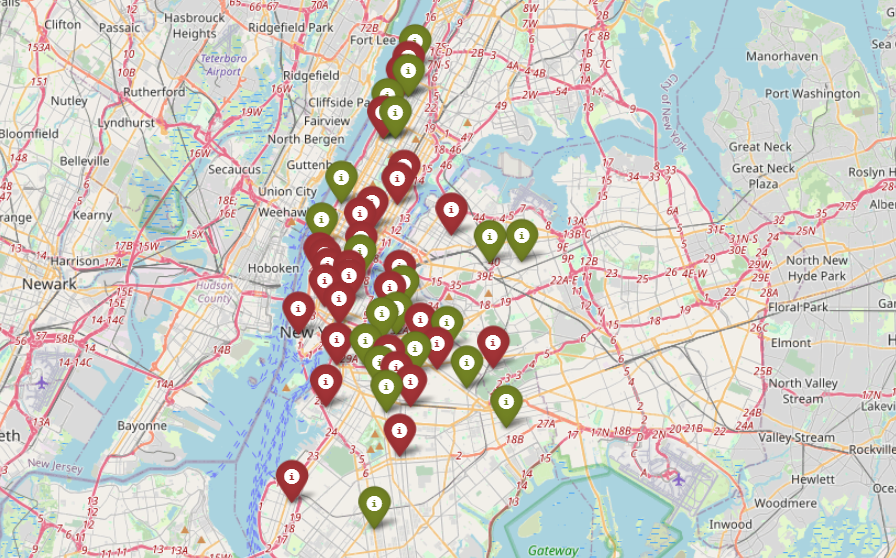
위치 기반의 데이터 시각화를 통해 부동산 유형 및 위치와 관련된 패턴에 대한 인사이트를 얻을 수 있습니다. 예를 들어, 특정 지역에는 특정 유형의 부동산이 더 많이 집중되어 있음을 알 수 있습니다.
그러나 이 지도는 단지 50개 속성의 무작위 샘플을 기반으로 하기 때문에 전체 데이터 세트를 완전히 나타내지 못할 수도 있습니다.
보다 정확한 표현을 위해 더 큰 샘플이나 전체 데이터 세트를 사용해야 합니다.
결론
지난 3번의 포스팅을 통해 뉴욕시의 Airbnb 리스트에 대한 대략적인 분석을 제공하여 도시의 임대 환경에 대한 인사이트를 얻을 수 있었습니다. 이 분석을 통해 얻은 인사이트는 호스트와 임차인 모두가 데이터 분석에 입각한 의사 결정을 하는 데 유용할 수 있습니다.
호스트의 경우 평균 임대 가격과 다양한 유형의 부동산 분포를 이해하면 경쟁력 있는 숙소 가격을 책정하는 데 도움이 될 수 있습니다.
임차인의 경우 가격, 위치 및 부동산 유형 측면에서 중요한 정보를 얻을 수 있을 것으로 기대합니다.
감사합니다.