이번 포스팅에서는 데이터 시각화를 활용한 탐색적 자료 분석 방법에 대해서 알아 보겠습니다.
뉴욕시 Airbnb 데이터를 활용한 탐색적 자료 분석의 두번째 포스팅입니다. 포스팅 글을 읽기 전에 zzinnam.com/뉴욕시-airbnb-데이터를-활용한-탐색적-자료-분석-1-with-python/ 을 먼저 학습하여 파이썬 코드를 실행하시기 바랍니다. 그렇지 않으면 아래 파이썬 코드들이 모두 에러가 발생합니다.
뉴욕시 Airbnb 데이터를 활용한 탐색적 자료 분석 두번째 단계로 데이터 시각화를 활용한 탐색적 자료 분석 방법에 대해서 알아 보겠습니다.
도넛 차트 생성하기
# 도넛 차트 생성하기
fig = go.Figure(data = [go.Pie(labels = percentByRegion.index, values = percentByRegion, hole = .3)])
# 도넛 차트 꾸미기
fig.update_traces(textinfo = 'percent + label', marker = dict(colors = ['#636EFA','#EF553B','#00CC96','#AB63FA','#FFA15A'], line = dict(color='#FFFFFF', width=2)))
# 레이아웃 업데이트
fig.update_layout(showlegend = False)
# 차트 출력
fig.show()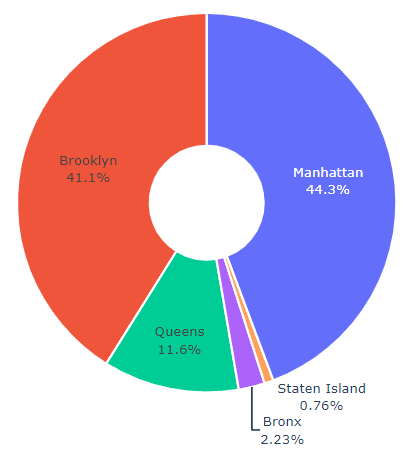
표준 편차
price = airbnbData.loc[:, 'price']
meanPrice = np.mean(price)
roundedMean = round(meanPrice, 2)
print('평균 임대 가격 : US$', roundedMean)
----------------------------------------------
평균 임대 가격 : US$ 152.72평균은 데이터의 평균 값을 나타내는 중심 경향의 척도입니다.
임대 가격의 맥락에서 평균 가격은 임대의 일반적인 가치에 대한 추정치를 제공하기 위해 계산됩니다.
평균 임대 가격은 대략 $152이며 소수점 이하 두 자리까지 반올림하였습니다.
standardDeviation = np.std(price)
roundedStdDev = round(standardDeviation, 2)
print('가격의 표준 편차 : US$', roundedStdDev)
--------------------------------------------------
가격의 표준 편차 : US$ 240.15표준편차는 값이 평균에서 얼마나 벗어났는지를 나타내는 분산 척도입니다.
즉, 표준편차는 평균을 중심으로 한 데이터의 변동성을 나타냅니다.
임대 가격의 표준 편차는 약 $240이며 소수점 이하 두 자리까지 반올림하였습니다.
$392의 상한선과 평균을 중심으로 $0에 가까운 하한선을 고려하면 대부분의 임대 가격이 이 범위에 속할 것이라고 말할 수 있습니다.
그러나 이러한 경계보다 높거나 낮은 일부 극단적인 값이 여전히 있을 수 있습니다.
이러한 통계적 측정은 임대 가격 분포를 이해하고 가치 변동에 대한 일반적인 감각을 제공하는 데 유용합니다.
그러나 이러한 값은 기술 통계일 뿐 렌탈 시장의 모든 측면과 뉘앙스를 포착할 수는 없다는 점을 기억해야 합니다.
minimumPrice = np.min(price)
print('최소 임대 가격 : US$', minimumPrice)
-----------------------------------------------
최소 임대 가격 : US$ 0이 데이터는 실제로 임대 가격이 0인 일부 속성이 있습니다.
이러한 값은 일종의 “무료 평가판” 또는 프로모션 제안에 해당할 수 있습니다.
maximumPrice = np.max(price)
print('최대 임대 가격 : US$', maximumPrice)
------------------------------------------------
최대 임대 가격 : US$ 10000임대료 분포
이 코드는 지정된 제목과 축 라벨이 있는 seaborn 라이브러리를 사용하여 히스토그램 플롯을 생성합니다.
plt.figure(figsize=(10, 6))
sns.histplot(airbnbData, x = 'price', bins = "doane", kde = False, color = 'blue')
plt.title('Rend Distribution')
plt.xlabel('Price')
plt.ylabel('Frequency')
plt.show()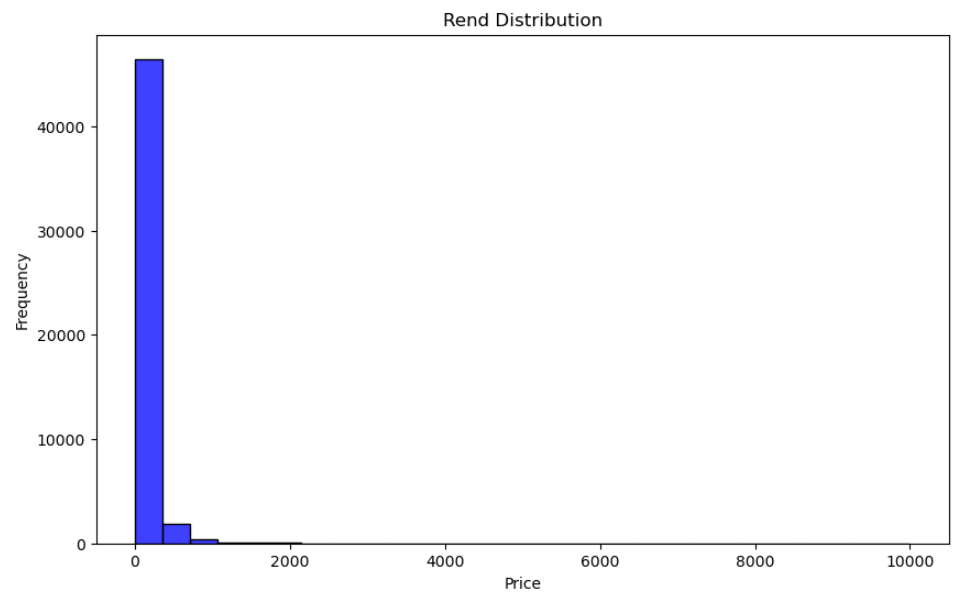
$10,000와 같은 이상치 값은 임대 가격 분포의 시각화, 분석 및 이해에 왜곡을 일으킬 수 있습니다.
따라서 이러한 값은 데이터 세트 전체를 대표하지 않으므로 분석에서 제거하는 것이 필요합니다.
plt.figure(figsize=(10, 6))
sns.histplot(airbnbData[airbnbData['price'] <= 1000], x = 'price', bins = "doane", kde = False, color = 'blue')
plt.title('Rend Distribution')
plt.xlabel('Price')
plt.ylabel('Frequency')
plt.show()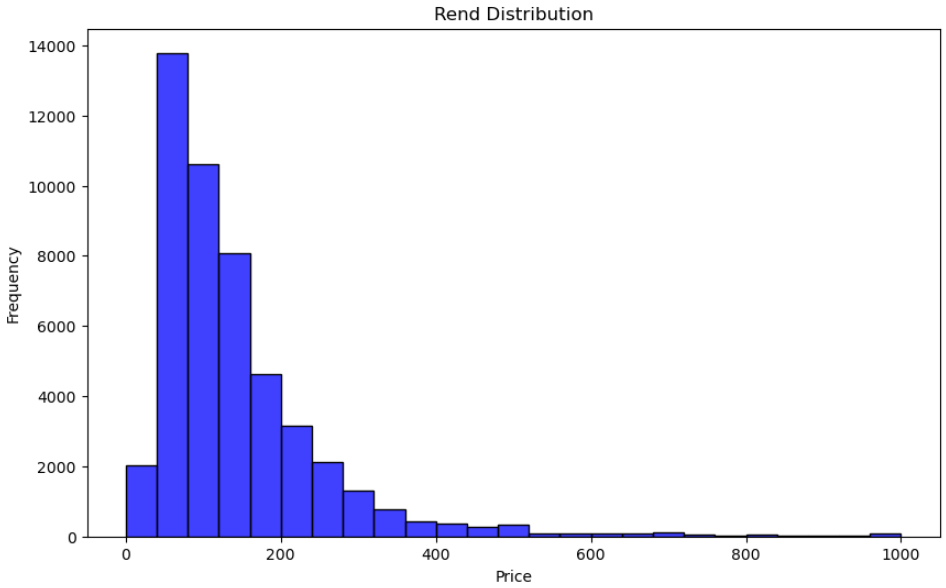
히스토그램을 통해 대부분의 임대 가격이 낮은 범위에 있고 일부 임대 가격이 매우 높은 것을 볼 수 있습니다.
이는 임대가격 분포가 오른쪽으로 치우쳐 있음을 의미한다.
분포의 정점은 저가 주변에 있으며, 이는 대부분의 임대 가격이 중저가에 있음을 나타냅니다.
더 높은 가격을 향한 긴 꼬리는 매우 높은 가격의 임대가 몇 개 있다는 것을 나타냅니다.
x축을 1000으로 제한함으로써 가장 일반적인 임대 가격에 초점을 맞추고 이 범위의 분포를 보다 명확하게 보여줍니다.
대부분의 임대는 여전히 낮은 가격 범위에 있지만 x축 제한과 더 많은 구간(bin)을 사용하면 가격 간격이 더 작은 빈도를 더 명확하게 볼 수 있습니다.
plt.figure(figsize=(10, 6))
sns.histplot(airbnbData[airbnbData['price'] <= 800], x = 'price', binwidth = 50, kde = False, color = 'blue')
plt.title('Distribution of Rental Prices')
plt.xlabel('Price')
plt.ylabel('Frequency')
plt.xticks(np.arange(0, 801, 50))
plt.show()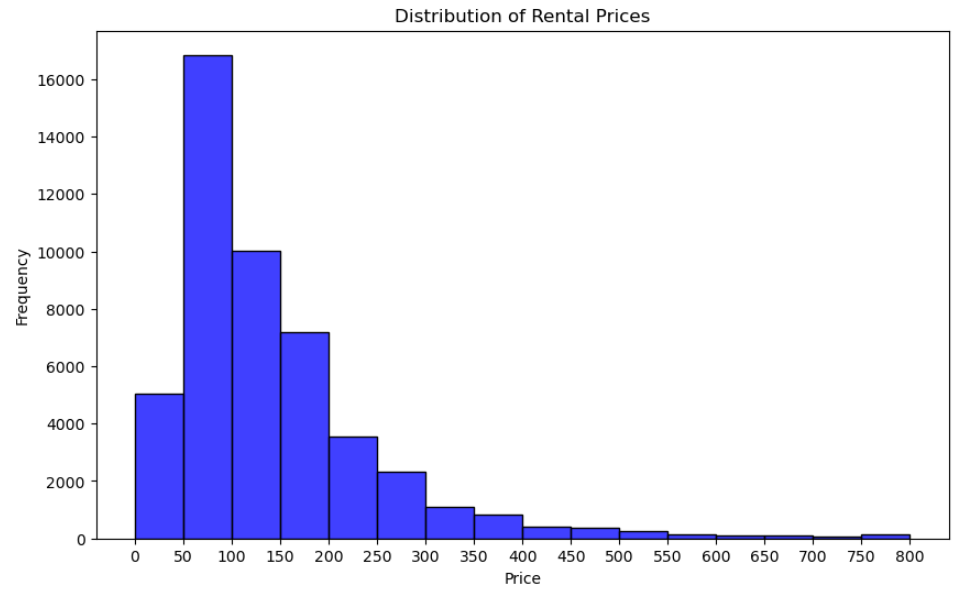
xticks을 50 간격으로 설정하면 x축에서 가격대를 명확하게 볼 수 있습니다.
이를 통해 임대 가격 분포를 보다 정확하게 이해할 수 있습니다.
대부분의 렌탈은 여전히 낮은 가격 범위에 있지만 x축 제한, 더 작은 상자 크기 및 명확한 x 표시를 통해 더 작은 가격 간격의 빈도를 더 명확하게 확인할 수 있습니다.
리뷰 수
단일 부동산의 리뷰 수에 대한 통계는 다음과 같습니다.
# 리뷰에 대한 통계
reviews = airbnbData.loc[: , 'number_of_reviews']
maxReviews = np.max(reviews)
print('단일 부동산에 대한 최대 리뷰 수: ', maxReviews)
minReviews = np.min(reviews)
print('단일 부동산에 대한 최소 리뷸 수: ', minReviews)
averageReviews = np.mean(reviews)
print('단일 부동산에 대한 평균 리뷰 수는 ', int(averageReviews), '입니다.')
stdDevReviews = np.std(reviews)
print('단일 부동산에 대한 리뷰 수에 대한 표준편차는 ', int(stdDevReviews), '입니다.')
----------------------------------------------------------------------------------------
단일 부동산에 대한 최대 리뷰 수: 629
단일 부동산에 대한 최소 리뷸 수: 0
단일 부동산에 대한 평균 리뷰 수는 23 입니다.
단일 부동산에 대한 리뷰 수에 대한 표준편차는 44 입니다.이 통계는 데이터 세트의 숙박 시설에 대한 리뷰 수 분포에 대한 개요를 제공합니다.
평균 리뷰수는 23개이나, 표준편차가 높아 리뷰수가 넓게 분포되어 있음을 알 수 있습니다.
일부 숙박 시설에는 리뷰가 없지만 다른 숙박 시설에는 리뷰가 629개나 있습니다.
plt.figure(figsize=(10, 6))
sns.histplot(airbnbData[airbnbData['number_of_reviews'] <= 100], x = 'number_of_reviews', binwidth = 5, kde = False, color = 'blue')
plt.title('Distribution of Number of Reviews')
plt.xlabel('Number of Reviews')
plt.ylabel('Frequency')
plt.xticks(np.arange(0, 101, 5))
plt.yticks(np.arange(0, 24001, 2000))
plt.show()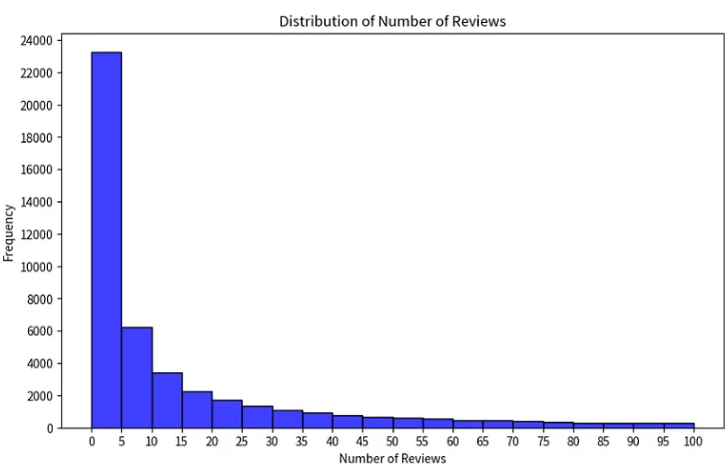
리뷰 수가 가장 높은 구간은 약 0~20개의 리뷰 범위인 것으로 보입니다.
이는 대부분의 숙박 시설의 리뷰 수가 낮거나 중간 정도이며 일부 숙박 시설의 리뷰 수가 높음을 나타냅니다.
최소 숙박일수에 대한 통계
# 변수 할당
minimumNights = airbnbData.loc[:, 'minimum_nights']
maxMinimumNights = np.max(minimumNights)
print('단일 부동산에 대한 최소 숙박일수의 최대값은 ', int(maxMinimumNights), '입니다.')
minMinimumNights = np.min(minimumNights)
print('단일 부동산에 대한 최소 숙박일수의 최소값은 ', int(minMinimumNights), '입니다.')
averageMinimumNights = np.mean(minimumNights)
print('단일 부동산에 대한 최소 숙박일수의 평균값은 ', int(averageMinimumNights), '입니다.')
stdDevMinimumNights = np.std(minimumNights)
print('단일 부동산에 대한 최소 숙박일수의 표준편차는 ', int(stdDevMinimumNights), '입니다.')
-------------------------------------------------------------------------------------------
단일 부동산에 대한 최소 숙박일수의 최대값은 1250 입니다.
단일 부동산에 대한 최소 숙박일수의 최소값은 1 입니다.
단일 부동산에 대한 최소 숙박일수의 평균값은 7 입니다.
단일 부동산에 대한 최소 숙박일수의 표준편차는 20 입니다.이러한 통계는 데이터 세트에 있는 숙박 시설의 최소 숙박 일수 분포에 대한 개요를 제공합니다.
평균 최소 숙박일수는 7박이나 표준편차가 높아 최소 숙박일수가 넓게 분포되어 있음을 알 수 있다.
일부 숙박 시설은 최소 1박을 제공하는 반면 다른 숙박 시설은 최대 1250박을 제공합니다.
plt.figure(figsize = (10, 6))
sns.histplot(airbnbData[airbnbData['minimum_nights'] <= 30], x = 'minimum_nights', binwidth=1, kde=False, color='blue')
plt.title('Distribution of Minimum Nights')
plt.xlabel('Minimum Nights')
plt.ylabel('Frequency')
plt.xticks(np.arange(0, 31, 1))
plt.show()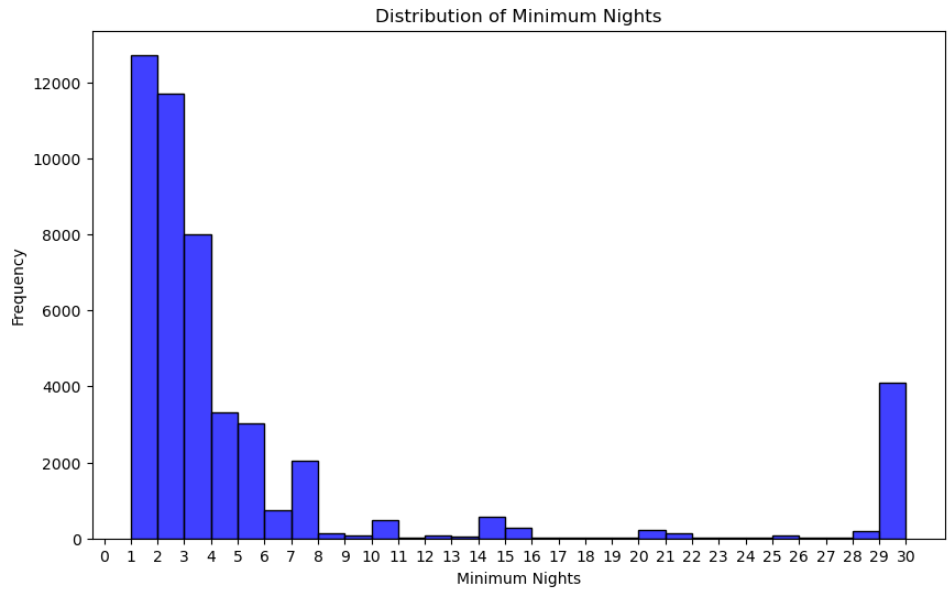
대부분의 숙박 시설은 1박에서 5박 사이로 낮은 최소 숙박 일수를 요구합니다.
이는 히스토그램 왼쪽의 높은 막대를 통해 알 수 있습니다. 많은 호스트가 주말 여행이나 단기 출장 등 단기 체류에 개방적이라는 것을 의미합니다.
필요한 최소 숙박 일수가 증가함을 나타내는 x축을 따라 오른쪽으로 이동하면 더 긴 최소 숙박 기간이 필요한 숙박 시설의 빈도가 감소하는 것을 알 수 있습니다.
이는 막대의 높이가 감소하는 것으로 표시됩니다. 이는 장기 임대가 가능한 숙소가 적거나 최소 숙박 기간이 더 길어야 하는 호스트 수가 적다는 것을 의미합니다.
히스토그램의 오른쪽 끝에 있는 막대로 표시된 것처럼 높은 최소 숙박 일수를 요구하는 몇 가지 숙박 시설이 있습니다.
그러나 이러한 숙박 시설은 단기 체류가 필요한 숙박 시설에 비해 상대적으로 드뭅니다.
전반적으로 히스토그램은 오른쪽으로 치우친 분포를 보여줍니다.
이는 대부분의 숙박 시설이 낮거나 중간 수준의 최소 숙박 일수를 요구하며, 더 긴 최소 숙박 기간을 요구하는 숙박 시설의 수가 적음을 나타냅니다.
소유 부동산과 호스트(host) 간 관계는?
propertiesHosts = airbnbData.loc[:, 'calculated_host_listings_count']
averagePropertiesHosts = np.mean(propertiesHosts)
print('호스트당 평균 부동산 보유 수 :', int(averagePropertiesHosts))
stdDevPropertieshosts = np.std(propertiesHosts)
print('호스트당 부동산 소유 수의 표준 편차 :', int(stdDevPropertieshosts))
medianPropertiesHosts = np.median(propertiesHosts)
print('호스트당 부동산 소유 수의 중위 수 : ', int(medianPropertiesHosts))
maxPropertiesHosts = np.max(propertiesHosts)
print('호스트당 부동산 소유 수의 최대값 :', int(maxPropertiesHosts))
minPropertiesHosts = np.min(propertiesHosts)
print('호스트당 부동산 소유 수의 최소값:', int(minPropertiesHosts))
---------------------------------------------------------------------------------
호스트당 평균 부동산 보유 수 : 7
호스트당 부동산 소유 수의 표준 편차 : 32
호스트당 부동산 소유 수의 중위 수 : 1
호스트당 부동산 소유 수의 최대값 : 327
호스트당 부동산 소유 수의 최소값: 1중위수는 특정 값이 아닌 데이터의 위치를 기반으로 하는 중심 경향의 측정값입니다.
중위수를 찾으려면 먼저 데이터를 가장 작은 것부터 가장 큰 것 순으로 정렬합니다.
중위수는 데이터를 절반으로 나누는 값입니다. 즉, 값의 절반은 중위수보다 작고 절반은 더 큽니다.
최대 327개의 부동산을 보유하고 있는 호스트가 있더라도 중앙값은 1입니다.
즉, 나열된 부동산 보유 수를 기준으로 호스트를 정렬하면 정확히 중간에 있는 호스트에는 1개의 부동산만 보유하고 있는 것입니다.
따라서 대다수의 호스트에는 단 1개의 숙소만 등록되어 있다고 결론을 내릴 수 있습니다.
이는 중앙값의 중요한 특징을 강조합니다. 즉, 극단값에 영향을 받지 않습니다.
일부 호스트에 소유하고 있는 부동산이 많더라도 이는 대부분의 호스트의 상황을 반영하는 중앙값에 영향을 미치지 않습니다.
# 데이터 라벨이 있는 최대 10개의 부동산을 소유하고 있는 호스트에 대한 Seaborn 히스토그램
# 한글 깨짐 현상 방지를 위한 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.figure(figsize = (10, 6))
ax = sns.histplot(airbnbData[airbnbData['calculated_host_listings_count'] <= 10], x = 'calculated_host_listings_count', binwidth = 1, kde = False, color = 'blue')
plt.title('호스트별 부동산 소유 수 분포')
plt.xlabel('부동산 소유 수')
plt.ylabel('분포')
plt.xticks(np.arange(0, 11, 1))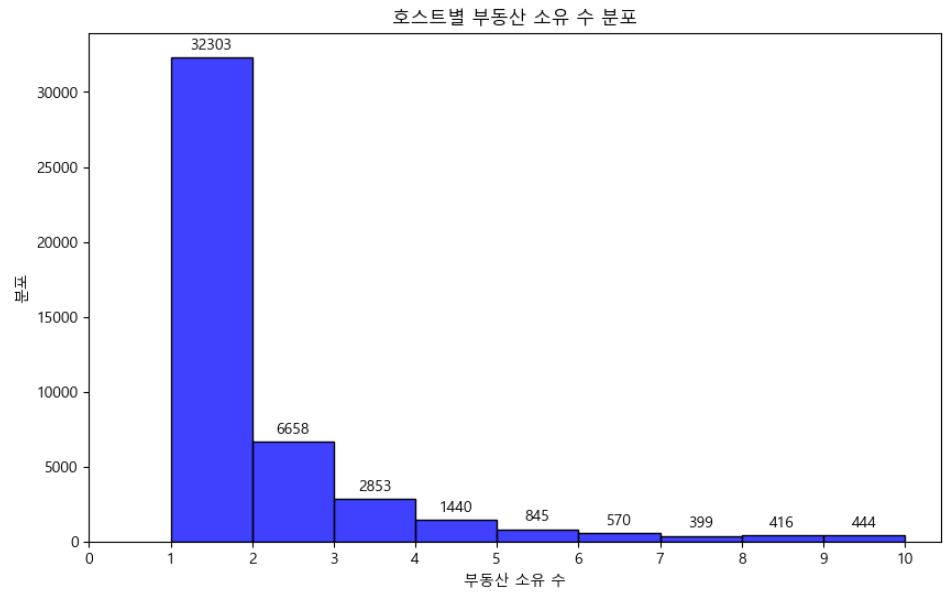
이 히스토그램에서 x축은 호스트 당 보유 부동산 수를 나타내고, y축은 해당 부동산 소유 수를 가진 호스트의 빈도를 나타냅니다. 히스토그램은 최대 10개의 부동산을 보유하고 있는 호스트에 대한 호스트 당 속성 수의 분포를 보여줍니다.
대부분의 호스트에는 X축의 1에 있는 높은 막대로 표시된 대로 부동산 소유 수가 1개 입니다. 호스트 당 보유 부동산 수가 증가하면 해당 부동산 소유 수를 가진 호스트의 빈도가 감소합니다. 이는 x축을 따라 오른쪽으로 이동할 때 막대의 높이가 감소하는 것으로 나타납니다.
이 히스토그램은 호스트당 속성 수 분포를 명확하게 시각화 합니다. 이는 대부분의 호스트가 소수의 부동산만 보유하고 있으며 소수의 호스트가 더 많은 부동산을 보유하고 있음을 보여줍니다.
지역별 최대 임대 가격
이 막대 그래프에서 x축은 뉴욕의 여러 지역을 나타내고 y축은 각 지역의 최대 임대 가격을 나타냅니다. 각 막대 상단의 데이터 라벨은 각 지역의 정확한 최대 임대 가격을 보여줍니다.
# 뉴욕 지역별 가장 비싼 렌트 가격
# 지역 유형별로 데이터를 그룹화하고 최대 임대 가격을 계산
maxRentalByRegion = airbnbData.loc[:, ['neighbourhood_group', 'price']].groupby('neighbourhood_group').max()
# 값을 정수로 변환
maxRentalByRegion = maxRentalByRegion.astype(int)
# 인덱스를 재설정하여 'neighbourhood_group'을 다시 열 생성
maxRentalByRegion.reset_index(inplace = True)
# 열 이름 변경
maxRentalByRegion.columns = ['Region', 'Maximum Rental']
# 지역별 최대 임대 가격에 대한 Seaborn 막대 그래프
plt.figure(figsize = (10, 6))
ax = sns.barplot(x = 'Region', y = 'Maximum Rental', data = maxRentalByRegion, palette = 'Blues_d')
plt.title('뉴욕 지역별 가장 비싼 렌트 가격')
plt.xlabel('지역')
plt.ylabel('최대 렌트 가격')
# 데이터 라벨 추가
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x() + p.get_width() / 2., p.get_height()), ha = 'center', va = 'center', xytext = (0, 7), textcoords = 'offset points')
plt.show()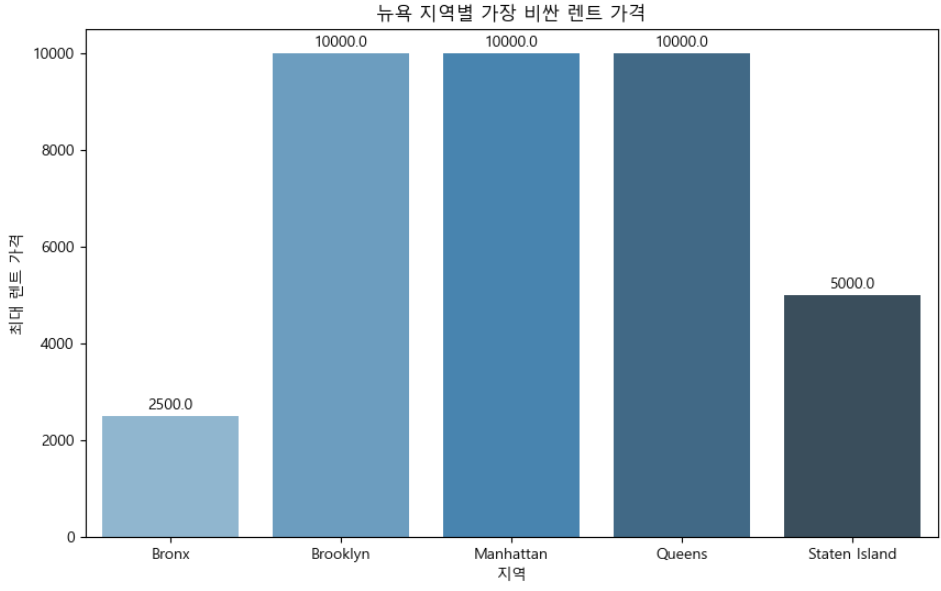
막대 그래프를 보면 맨해튼, 브루클린, 퀸즈의 최대 임대 가격이 모두 $10,000로 가장 높은 것을 알 수 있습니다. 브롱스의 최대 임대 가격은 $2,500이고, 스태튼 아일랜드의 최대 임대 가격은 $5,000입니다.
이 시각화는 뉴욕의 여러 지역에서 가장 비싼 임대료를 명확하게 비교합니다. 맨해튼, 브루클린, 퀸즈가 임대 가격이 가장 높은 지역임을 보여주고 있습니다.
지역별 평균 임대 가격
# 뉴욕시의 지역별 평균 임대 가격
# 지역 유형별로 데이터를 그룹화하고 평균 임대 가격 계산
averageRentalByRegion = airbnbData.loc[:, ['neighbourhood_group', 'price']].groupby('neighbourhood_group').mean()
# 값을 정수로 변환
averageRentalByRegion = averageRentalByRegion.astype(int)
# 인덱스를 재설정하여 'neighbourhood_group'을 다시 열로 변환
averageRentalByRegion.reset_index(inplace = True)
# 이해를 돕기 위한 열 이름 변환
averageRentalByRegion.columns = ['Region', 'Average Rental']
# 지역별 평균 임대 가격에 대한 Seaborn 막대 그래프 그리기
plt.figure(figsize = (10, 6))
ax = sns.barplot(x = 'Region', y = 'Average Rental', data = averageRentalByRegion, palette = 'Blues_d')
plt.title('뉴욕시의 지역별 평균 임대 가격')
plt.xlabel('지역')
plt.ylabel('평균 임대 가격')
# 데이터 라벨 추가
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x() + p.get_width() / 2., p.get_height()), ha = 'center', va = 'center', xytext = (0, 7), textcoords = 'offset points')
plt.show()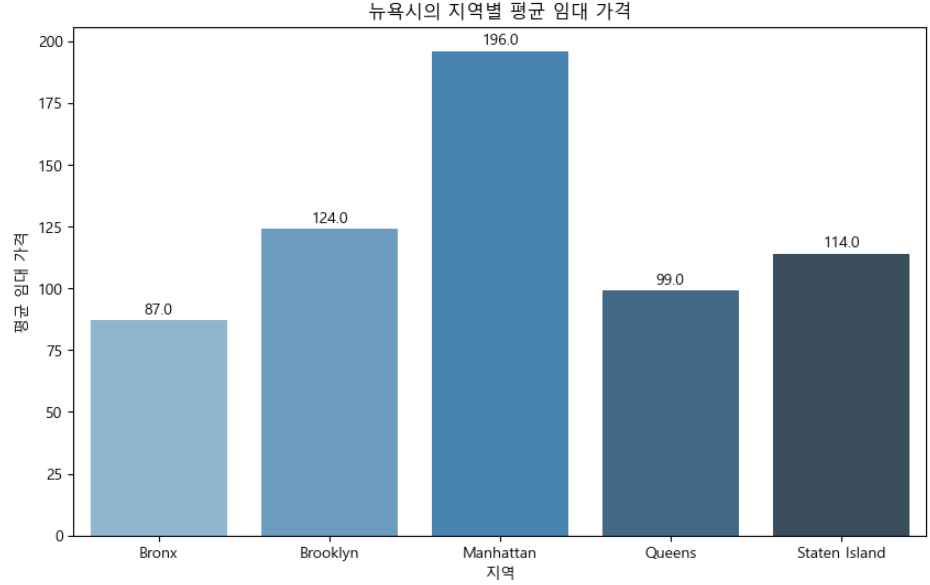
이 막대 그래프에서 x축은 뉴욕의 여러 지역을 나타내고 y축은 각 지역의 평균 임대 가격을 나타냅니다. 각 막대 상단의 데이터 라벨은 각 지역의 정확한 평균 임대 가격을 제공합니다.
맨해튼의 평균 임대 가격이 가장 높고 브루클린, 스태튼 아일랜드, 퀸즈, 브롱크스가 그 뒤를 잇는다는 것을 알 수 있습니다. 뉴욕 내 여러 지역의 평균 임대 가격을 명확하게 비교해 주고 있습니다. 맨해튼과 브루클린이 평균 임대 가격이 가장 높은 지역임을 보여줍니다.
객실 유형별 평균 리뷰
# 객실 유형별 평균 리뷰
# 객실 유형별로 데이터를 그룹화하고 평균 리뷰 수 계산
averageReviewsByType = airbnbData.loc[:, ['number_of_reviews', 'room_type']].groupby('room_type').mean()
# 값을 정수로 변환
averageReviewsByType = averageReviewsByType.astype(int)
# 'room_type'을 다시 열로 만들기 위해 인덱스 재설정
averageReviewsByType.reset_index(inplace = True)
# 이해를 돕기 위해 열 이름 변경
averageReviewsByType.columns = ['Room Type', 'Average Reviews']
# 데이터 라벨이 있는 객실 유형별 평균 리뷰에 대한 Seaborn 막대 그래프
plt.figure(figsize = (10, 6))
ax = sns.barplot(x = 'Room Type', y = 'Average Reviews', data = averageReviewsByType, palette = 'Blues_d')
plt.title('객실 유형 별 평균 리뷰')
plt.xlabel('객실 유형')
plt.ylabel('평균 리뷰')
# 데이터 라벨 추가
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x() + p.get_width() / 2., p.get_height()), ha = 'center', va = 'center', xytext = (0, 10), textcoords = 'offset points')
plt.show()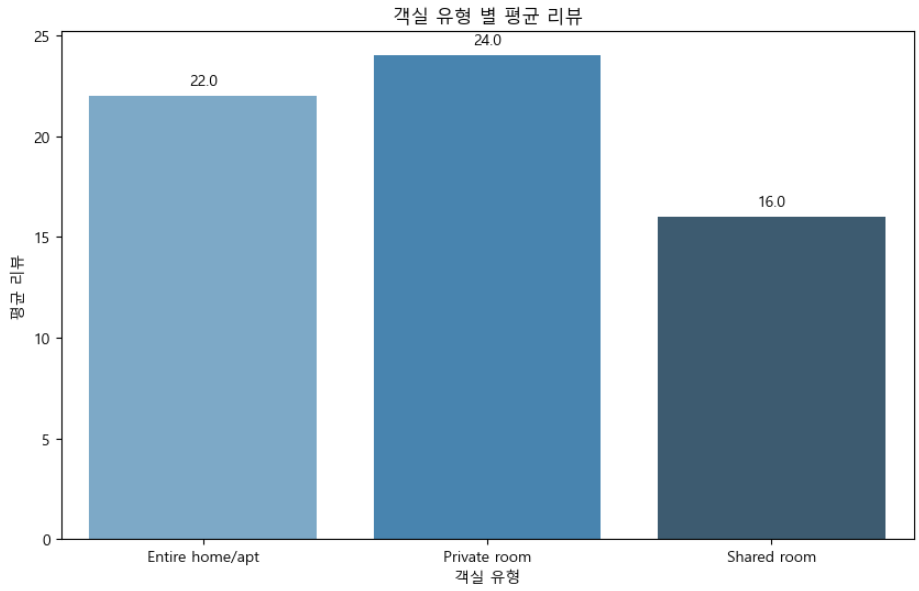
이 막대 그래프에서 x축은 다양한 유형의 객실을 나타내고 y축은 각 객실 유형의 평균 리뷰 수를 나타냅니다. 각 막대 상단의 데이터 라벨은 각 객실 유형에 대한 정확한 평균 리뷰 수를 제공합니다.
개인실의 평균 리뷰 수가 가장 많고, 전체 주택/아파트, 다인실이 그 뒤를 잇는다는 것을 알 수 있습니다. 다양한 객실 유형의 평균 리뷰 수를 명확하게 비교합니다. 이는 개인실이 평균적으로 더 많은 리뷰를 받는 경향이 있음을 보여주고 있습니다.
지역별 소유자 수
아래 코드는 먼저 관련 열 ‘host_id’ 및 ‘neighbourhood_group’을 선택한 다음 ‘neighbourhood_group’으로 그룹화합니다. nunique() 함수는 각 그룹의 고유한 ‘host_id’ 값 수를 계산하는 데 사용되며, 이는 각 지역의 고유한 부동산 소유자 수를 제공합니다.
# 지역별 소유자 수
# 열 선택 및 수학 연산자 실행
ownersByRegion = airbnbData.loc[:, ['host_id', 'neighbourhood_group']].groupby('neighbourhood_group').nunique()
# Plotly Express를 사용하여 막대 차트 만들기
fig = px.bar(ownersByRegion.reset_index(), x = 'neighbourhood_group', y = 'host_id',
title = '지역별 고유 소유자 수',
labels = {'host_id':'소유자 수', 'neighbourhood_group':'지역'},
color_discrete_sequence = ['#1f77b4'],
template = 'plotly_white')
# 데이터 라벨 추가
fig.update_traces(texttemplate = '%{y:.0f}', textposition = 'outside')
# Y축 제거
fig.update_yaxes(showticklabels = False)
# 그래프 출력
fig.show()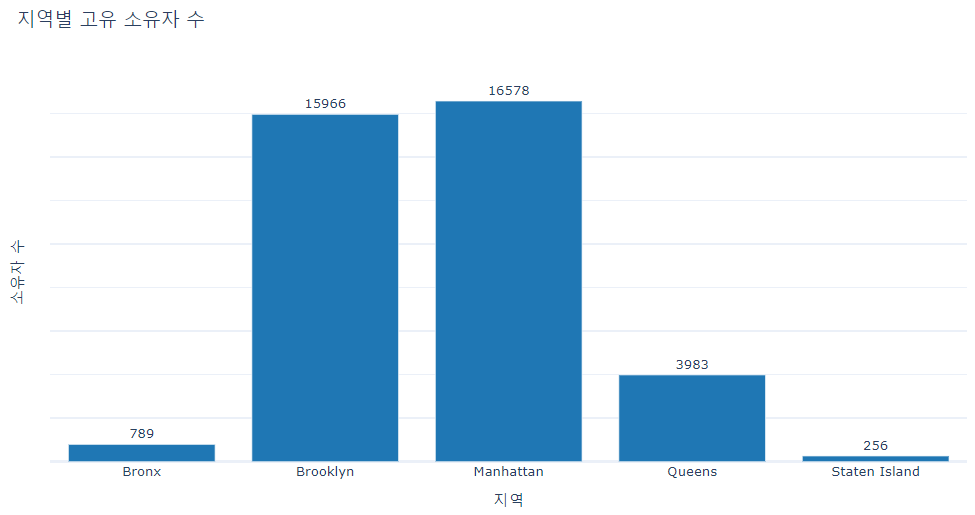
차트를 보면 맨해튼의 고유 부동산 소유자 수가 가장 많고 브루클린이 그 다음으로 높습니다. 퀸즈, 스태튼 아일랜드 및 브롬크스에는 고유 부동산 소유자가 훨씬 적습니다.
맨해튼과 브루클린에는 가장 고유한 부동산 소유자가 가장 많이 있지만 이것이 반드시 전체적으로 가장 많은 매물을 보유하고 있다는 의미는 아니라는 점에 유의해야 합니다. 한 명의 소유자가 에어비앤비에 여러 개의 숙소를 등록할 수 있기 때문입니다.
이 분석은 뉴욕시 여러 지역의 Airbnb 목록 분포에 대한 귀중한 통찰력을 제공하며, 이는 자신의 자산을 어디에 등록할지 고민하는 부동산 소유자와 숙박할 곳을 결정하는 여행자 모두에게 유용할 수 있습니다.
지역 및 숙박 유형별 최대 임대 가격
# 지역 및 객실 유형별로 데이터를 그룹화하고 최대 임대 가격 계산
maxValueRegionType = airbnbData.loc[:, ['neighbourhood_group', 'room_type', 'price']].groupby(['neighbourhood_group', 'room_type']).max().reset_index()
# 정수로 변환
maxValueRegionType['price'] = maxValueRegionType['price'].astype(int)
# 이해를 돕기 위해 열 이름 변경
maxValueRegionType.columns = ['Region', 'Type', 'Maximum Value']
import plotly.express as px
fig = px.bar(maxValueRegionType, x = 'Maximum Value', y = 'Region', color = 'Type', orientation = 'h',
labels = {'Maximum Value':'최대 임대 가격', 'Region':'지역', 'Type':'객실 유형'},
title = '뉴욕시 지역 및 객실 유형별 최대 임대 가격')
fig.update_traces(texttemplate = '%{x:.0f}', textposition = 'inside')
fig.show()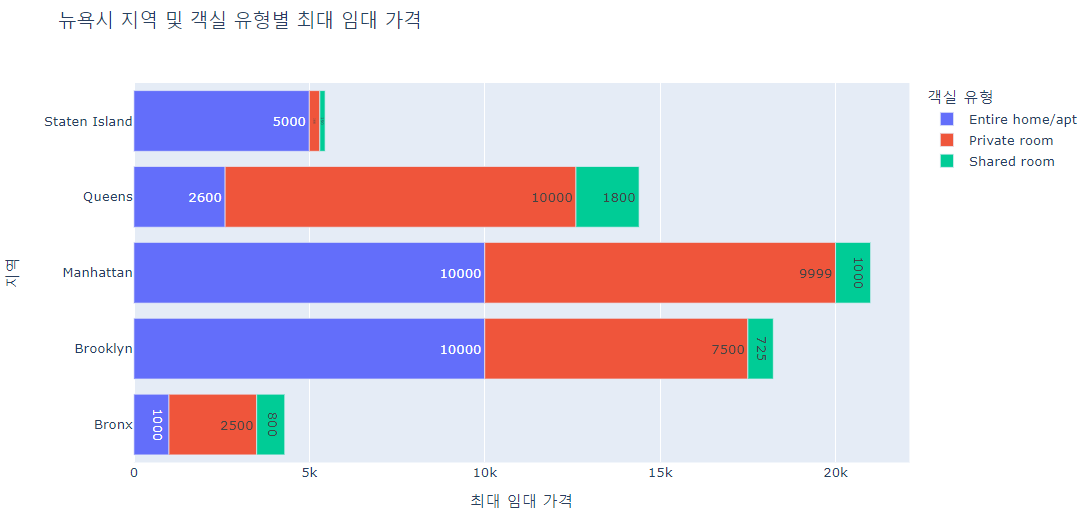
위의 막대 차트는 뉴욕시의 지역 및 객실 유형별 최대 임대 가격을 보여줍니다. 다양한 색상은 Entire home/apt, Private room, Shared room 등 다양한 객실 유형을 나타냅니다.
맨해튼은 모든 객실 유형에 걸쳐 최대 임대 가격이 가장 높습니다.
모든 지역에서 Entire home/apt의 최대 임대 가격이 가장 높고, Private room, Shared room 순입니다. Entire home/apt를 임대하는 것은 일반적으로 Private room이나 Shared room을 임대하는 것보다 비용이 더 많이 들기 때문에 이는 매우 합리적인 분석 결과라 할 수 있습니다.
Shared room의 최대 임대 가격은 모든 지역에서 Entire home/apt 또는 Private room의 최대 임대 가격보다 훨씬 낮습니다. 이는 Shared room이 임차인에게 더 저렴한 옵션임을 시사합니다.
Entire home/apt 및 Private room의 최대 임대 가격은 퀸즈와 스태튼 아일랜드에서 매우 유사하며, 이는 이 지역이 Entire home/apt를 임대하려는 사람들에게 좋은 가치를 제공할 수 있음을 시사합니다.
브롱크스는 모든 객실 유형에 걸쳐 최대 임대 가격이 가장 낮으며, 이는 5개 객실 중에서 가장 저렴한 지역임을 시사합니다.
이 차트는 임차인과 부동산 소유자 모두에게 귀중한 통찰력을 제공합니다. 임차인은 이 정보를 사용하여 예산 내에서 원하는 지역 및 객실 유형의 숙박 시설을 찾을 수 있습니다. 반면에 부동산 소유자는 이 정보를 사용하여 지역 및 객실 유형에 따라 경쟁력 있는 부동산 가격을 책정할 수 있습니다.
다음 포스팅에서는 데이터 시각화를 활용한 탐색적 자료 분석 마지막 포스팅(그래프를 활용한 탐색적 데이터 분석)으로 뉴욕 지도에 유형별 부동산 위치를 그래프로 출력하는 방법에 대해서 알아 보겠습니다.
감사합니다.