이번 포스팅에서는 파이썬 스크래핑 실습 첫 포스팅으로 파이썬을 활용해서 네이버 증권 메뉴에 있는 국내증시 거래량 기준 top 100 종목과 종목에 대한 기본 정보를 스크랩핑해서 엑셀 파일로 저장하는 방법에 대해서 알아 보겠습니다. 이를 수행하려면 스크랩핑 개념과 기본적인 html 구문에 대한 이해, 그리고 관련 파이썬 모듈을 이해하고 있어야 합니다. 자세한 설명은 별도 포스팅을 통해 설명 드리고, 여기에서는 정보를 가져오는 방법에 초첨을 맞춰 설명 드리겠습니다.
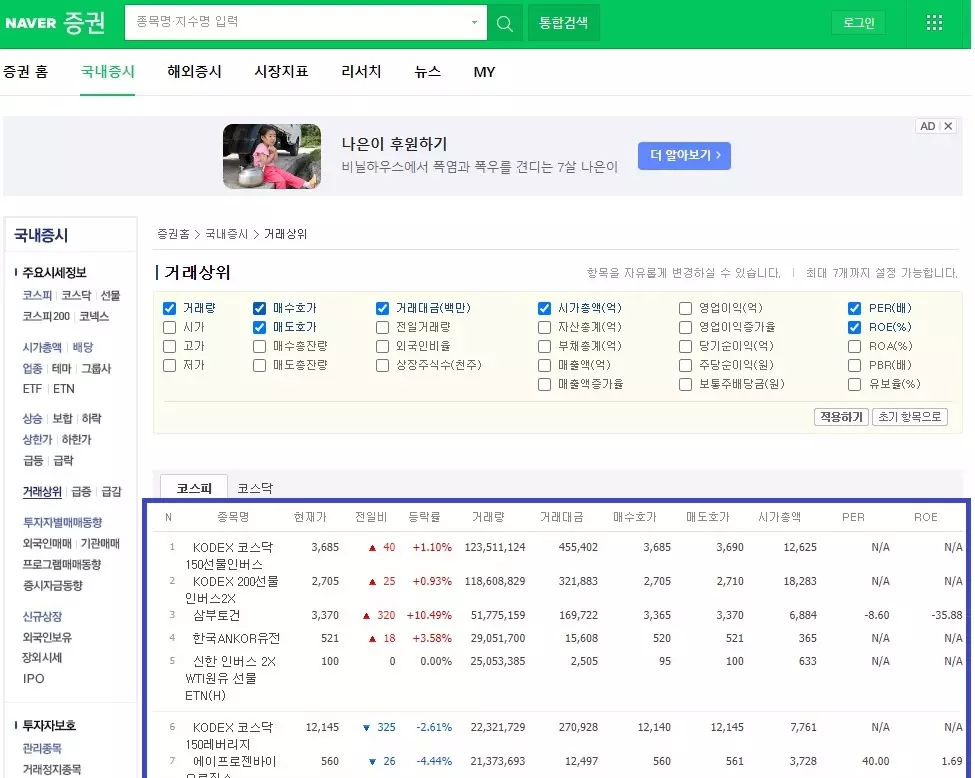
가져오고자 하는 최종 데이터
이번 포스팅의 목표는 아래 그림의 파란색 테두리에 있는 표 형태의 데이터를 가져와서 엑셀로 저장하는 것입니다. 아래 화면에서는 거래량 기준 상위 12개의 종목만 보이지만, 실제로는 100개의 종목이 있습니다. (
정보 추출을 위한 html 구문 확인하기
위의 그림에 있는 화면은 인터넷 주소창에서 https://finance.naver.com/sise/sise_quant.naver?sosok=0 를 입력했을 때 보이는 화면입니다. 인터넷 웹에서는 위와 같이 보이나, 실제 화면을 구성하는 모든 데이터는 html 구문으로 이루어져 있습니다.
이를 확인하려면,
- 크롬을 실행 한 후 인터넷 주소창에서 https://finance.naver.com/sise/sise_quant.naver?sosok=0 을 입력합니다.
- F12를 클릭합니다.
그러면 아래와 같은 화면이 보입니다.
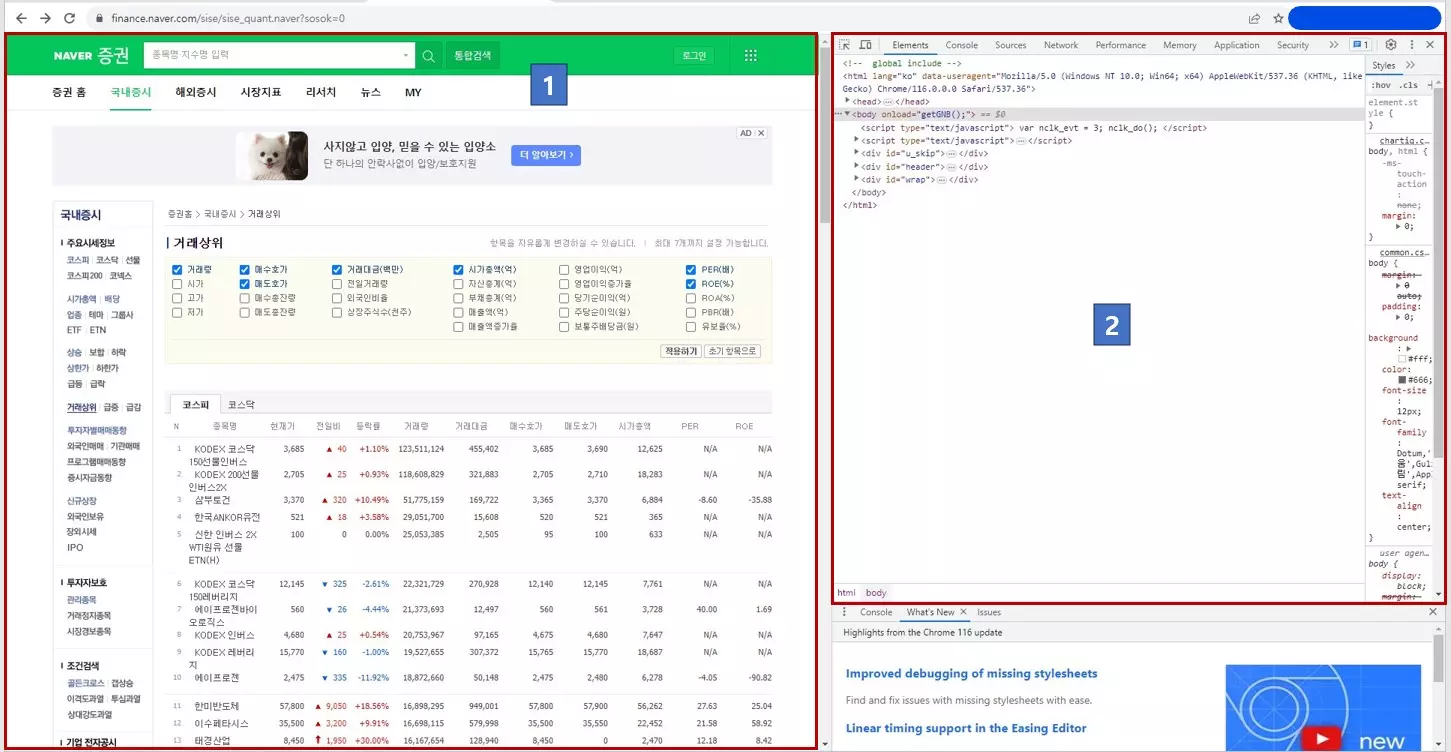
1번 영역이 우리가 보는 화면이고, 2번 영역이 1번 영역을 구성하고 있는 html 코드입니다. 2번 영역의 html 코드가 웹상에서는 1번처럼 보인다고 이해하시면 됩니다.
이번 포스팅의 최종 목표는 파이썬을 활용해서 2번 영역의 데이터에 접근하여 최종적으로 원하는 데이터를 추출하는 것입니다.
국내증시 거래량 top 100 정보 위치 확인하기
우리가 원하는 정보의 위치를 확인해 보겠습니다. 위의 그림과 같은 화면에서 Ctrl+Shift+C를 동시에 누릅니다. 왼쪽 화면에서 마우스를 놓고 움직이면, 파란색 사각형의 영역이 선택이 보입니다. 해당 영역의 html코드를 오른쪽 화면에서 보여 줍니다. 반대로 오른쪽 화면의 html코드에 마우스를 놓고 움직이면, 그에 해당하는 웹화면의 정보가 왼쪽에 보입니다.
마우스를 움직이면 우리가 추출하고자 하는 데이터는 <table cellpadding=”0″ cellspacing=”0″ class=”type_2″> == $0 영역에 있음을 확인할 수 있습니다. 파이썬으로 해당 영역에 접근해서 데이터를 추출하면 됩니다.
지금까지 설명 드린 내용을 이해하기 어려우시다면, 아래 동영상 참고 부탁 드립니다.
국내증시 거래량 top 100 정보 추출하기
필수 패키지 로딩
작업에 필요한 모듈을 로딩합니다.
import requests
from bs4 import BeautifulSoup- reguests : 파이썬에서 HTTP 요청을 보내는 데 사용되는 라이브러리입니다. 이 라이브러리는 웹 페이지에서 데이터를 가져오거나 웹 서버와 상호 작용하는 데 사용됩니다. 웹 스크래핑, 웹 API와의 통신, 웹 페이지 테스팅 등 다양한 웹 관련 작업을 수행할 수 있습니다.
- BeautifulSoup : 파이썬으로 웹 스크래핑(웹 페이지에서 데이터 추출)을 수행하는 데 사용되는 라이브러리 중 하나입니다. 주로 HTML 및 XML 문서를 구문 분석하고 데이터를 추출하기 위해 사용됩니다. BeautifulSoup은 파이썬에서 웹 데이터를 쉽게 탐색하고 조작할 수 있는 강력한 도구로 널리 사용되고 있습니다. 다른 웹 스크래핑 라이브러리와 함께 사용할 수 있으며, 주로 requests와 함께 사용하여 웹 페이지에서 데이터를 가져온 후 BeautifulSoup으로 데이터를 처리하는 것이 일반적입니다.
url 접속 및 정보 요청
특정 url에 접속하여 정보를 요청하여 받아옵니다.
# 접속하고자 하는 url 주소 입력
url = "https://finance.naver.com/sise/sise_quant.naver?sosok=0"
# url에 접속하여 정보를 요청합니다.
response = requests.get(url)
# 정상적으로 요청되었는지 확인합니다.
# 정상적으로 요청되었다면 Response 값이 200이 나와야 합니다.
response
--------------------------------------------
<Response [200]>정상적으로 요청되었음을 확인할 수 있습니다(Response : 200 확인). 요청하여 가져온 정보(텍스트)를 확인합니다.
요청 정보 확인
요청한 정보(텍스트)를 저장하고, 확인합니다.
# 요청하여 가져온 정보(텍스트)를 data에 저장
data = response.text
# 저장된 정보(텍스트) 확인
data
----------------------------------------------
'\n\n\n\n\n\n<!-- global include -->\n\n\t\n\t\n\t\n\t\n\t\n<html lang=\'ko\'>\n<head>\n\n\n\t\n\t\n\t\t\n\t\t\t\n\t\t\t\n\t\t\t\t<title>거래상위 종목 : 네이버 증권</title>\n\t\t\t\n\t\t\n\t\n\n\n\n\n\n\t\n\t\n\t\t<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />\n\t\n\n\n<meta http-equiv="Content-Script-Type" content="text/javascript">\n<meta http-equiv="Content-Style-Type" content="text/css">\n<meta name="apple-mobile-web-app-title" content="네이버 증권" />\n\n\n\n\n\n\t\n \n <meta property="og:url" content="http://finance.naver.com/sise/sise_quant.naver"/>\n \n\t\t\t\n\t\t \n\t\t \t<meta property="og:title" content="거래상위 종목 : 네이버 증권"/>\n\t\t \n\t\t\n\t\t\n\t\t\t\n\t\t\t <meta property="og:description" content="관심종목의 실시간 주가를 가장 빠르게 확인하는 곳"/>\n\t\t \n\t\t \n\t\t\n\t\t \n\t\t\t\n\t\t\t <meta property="og:image" content="https://ssl.pstatic.net/static/m/stock/im/2016/08/og_stock-200.png"/>\n\t\t \n\t\t \n\t\t\n \n\n<meta property="og:type" content="article"/>\n<meta property="og:article:thumbnailUrl" content=""/>\n<meta property="og:article:author" content="네이버 증권"/>\n<meta property="og:article:author:url" content="http://FINANCE.NAVER.COM"/>\n\n\n\n\n\n\n<link rel=\'stylesheet\' type=\'text/css\' href=\'https://ssl.pstatic.net/imgstock/static.pc/20230808201105/css/finance_header.css\'>\n\n\t\n\t\n\t\n\t\n\t\t\n\t\t<link rel="stylesheet" type="text/css" href="https://ssl.pstatic.net/imgstock/static.pc/20230808201105/css/newstock.css">\n\t\t<link rel="stylesheet" type="text/css" href="https://ssl.pstatic.net/imgstock/static.pc/20230808201105/css/common.css">\n\t\t<link rel="stylesheet" type="text/css" href="https://ssl.pstatic.net/imgstock/static.pc/20230808201105/css/layout.css">\n\t\t<link rel="stylesheet" type="text/css" href="https://ssl.pstatic.net/imgstock/static.pc/20230808201105/css/main.css">\n\t\t<link rel="stylesheet" type="text/css" href="https://ssl.pstatic.net/imgstock/static.pc/20230808201105/css/newstock2.css">\n\t\t<link rel="stylesheet" type="text/css" href="http
......정보를 가져왔지만, 위의 그림에 보이는 html 코드 형태와는 많이 다릅니다.
BeautifulSoup 함수를 활용하여 html코드를 파싱할 수 있는 형태로 변환하겠습니다.
BeautifulSoup을 활용한 데이터 처리
BeautifulSoup 함수를 활용하여 html 구문을 확인하고, 데이터 처리 작업을 준비합니다.
soup = BeautifulSoup(data, 'html.parser')
soup
---------------------------------------------
<!-- global include -->
<html lang="ko">
<head>
<title>거래상위 종목 : 네이버 증권</title>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>
<meta content="text/javascript" http-equiv="Content-Script-Type"/>
<meta content="text/css" http-equiv="Content-Style-Type"/>
<meta content="네이버 증권" name="apple-mobile-web-app-title">
<meta content="http://finance.naver.com/sise/sise_quant.naver" property="og:url">
<meta content="거래상위 종목 : 네이버 증권" property="og:title"/>
<meta content="관심종목의 실시간 주가를 가장 빠르게 확인하는 곳" property="og:description"/>
<meta content="https://ssl.pstatic.net/static/m/stock/im/2016/08/og_stock-200.png" property="og:image"/>
<meta content="article" property="og:type"/>
<meta content="" property="og:article:thumbnailUrl"/>
<meta content="네이버 증권" property="og:article:author"/>
<meta content="http://FINANCE.NAVER.COM" property="og:article:author:url"/>
<link href="https://ssl.pstatic.net/imgstock/static.pc/20230808201105/css/finance_header.css" rel="stylesheet" type="text/css"/>
<link href="https://ssl.pstatic.net/imgstock/static.pc/20230808201105/css/newstock.css" rel="stylesheet" type="text/css"/>
......F12 버튼을 눌러서 확인한 html구조 형태로 저장된 것을 확인할 수 있습니다.
추출하고자 하는 데이터 요소에 접근
BeautifulSoup의 select 함수를 사용하여 추출하고자 하는 요소에 접근합니다. select 함수는 웹 페이지에서 원하는 요소를 선택하는 데 사용되는 도구 중 하나 입니다. 이 함수를 사용하면 CSS 선택자를 활용하여 요소를 찾을 수 있습니다. 메서드는 주어진 CSS 선택자에 일치하는 모든 요소를 리스트로 반환합니다. 우리가 추출하고자 하는 데이터는 class가 “type_2” 인 table 태그안에 tr 태그 안에 있습니다.
# class가 "type_2" 인 table 태그안에 있느 tr 태그 선택
stockTable = soup.select("table.type_2 tr")
stockTable
-------------------------------------------------------
[<tr>
<th>N</th>
<th>종목명</th>
<th>현재가</th>
<th class="tr" style="padding-right:8px">전일비</th>
<th>등락률</th>
<th>거래량</th>
<th>거래대금</th>
<th>매수호가</th>
<th>매도호가</th>
<th>시가총액</th>
<th>PER</th>
<th>ROE</th>
</tr>,
<tr><td class="blank_08" colspan="10"></td></tr>,
<tr>
<td class="no">1</td>
<td><a class="tltle" href="/item/main.naver?code=251340">KODEX 코스닥150선물인버스</a></td>
<td class="number">3,685</td>
<td class="number">
<img alt="상승" height="6" src="https://ssl.pstatic.net/imgstock/images/images4/ico_up.gif" style="margin-right:4px;" width="7"/><span class="tah p11 red02">
40
</span>
</td>
<td class="number">
<span class="tah p11 red01">
+1.10%
</span>
</td>
<td class="number">123,511,124</td>
<td class="number">455,402</td>
<td class="number">3,685</td>
<td class="number">3,690</td>
<td class="number">12,625</td>
<td class="number">N/A</td>
<td class="number">N/A</td>
</tr>,
<tr>
<td class="no">2</td>
<td><a class="tltle" href="/item/main.naver?code=252670">KODEX 200선물인버스2X</a></td>
<td class="number">2,705</td>
<td class="number">
<img alt="상승" height="6" src="https://ssl.pstatic.net/imgstock/images/images4/ico_up.gif" style="margin-right:4px;" width="7"/><span class="tah p11 red02">
25
</span>
</td>
<td class="number">
<span class="tah p11 red01">
+0.93%
</span>
</td>
<td class="number">118,608,829</td>
<td class="number">321,883</td>
<td class="number">2,705</td>
<td class="number">2,710</td>
<td class="number">18,283</td>
<td class="number">N/A</td>
<td class="number">N/A</td>
</tr>,
...
]stockTable 객체 안에 우리가 선택한 요소들이 리스트로 저장되어 있음을 확인할 수 있습니다.
칼럼명 추출하기
최종 엑셀 파일로 데이터를 저장할 때, 데이터의 헤더명(칼럼명)이 필요합니다. 제일 먼저 칼럼명을 추출해서 저장하겠습니다. 칼럼명에 해당하는 정보는 stockTable 의 첫번째 요소에 저장되어 있습니다.
# stockTable의 첫번째 요소 확인
stockTable[0]
---------------------------------
<tr>
<th>N</th>
<th>종목명</th>
<th>현재가</th>
<th class="tr" style="padding-right:8px">전일비</th>
<th>등락률</th>
<th>거래량</th>
<th>거래대금</th>
<th>매수호가</th>
<th>매도호가</th>
<th>시가총액</th>
<th>PER</th>
<th>ROE</th>
</tr>stockTable[0]을 확인해 보니, 칼럼명은 <th> 태그안에 존재합니다. select 함수를 사용해서 <th> 태그안에 요소를 가져옵니다.
stockTable[0].select('th')
-------------------------------------
[<th>N</th>,
<th>종목명</th>,
<th>현재가</th>,
<th class="tr" style="padding-right:8px">전일비</th>,
<th>등락률</th>,
<th>거래량</th>,
<th>거래대금</th>,
<th>매수호가</th>,
<th>매도호가</th>,
<th>시가총액</th>,
<th>PER</th>,
<th>ROE</th>]stockTable[0].select(‘th’) 의 반환값은 리스트 형태입니다. 우리가 원하는 최종 칼럼명을 추출하려면 이 리스트 안에 있는 각각의 요소에 접근하여 <th>태그안에 있는 텍스트를 가져와야 합니다.
# 첫번째 요소에 접근하여 text 추출
stockTable[0].select('th')[0].text
----------------------------------
<th>N</th>
# 두번째 요소에 접근하여 text 추출
stockTable[0].select('th')[1].text
----------------------------------
<th>종목명</th>
....위의 과정을 stockTable[0].select(‘th’) 안에 존재하는 모든 요소에 대해서 접근해야 합니다. for문을 활용하여 최종 칼럼명을 colName에 저장하겠습니다.
# 칼럼명 추출하여 저장할 리스트 생성
colNames = []
# stockTable[0].select('th') 리스트 요소에 접근하여 텍스트 추출하여 저장
for tempColnames in stockTable[0].select('th') :
colNames.append(tempColnames.text)
colNames
----------------
['N',
'종목명',
'현재가',
'전일비',
'등락률',
'거래량',
'거래대금',
'매수호가',
'매도호가',
'시가총액',
'PER',
'ROE']최종 데이터 추출하기
최종 데이터는 stockTable 리스트의 두번째 요소부터 시작합니다.
# stockTable 리스트의 두번째 요소 확인
stockTable[1]
---------------------------------------------------
<tr><td class="blank_08" colspan="10"></td></tr>
# stockTable 리스트의 세번째 요소 확인
stockTable[2]
---------------------------------------------------
<tr>
<td class="no">1</td>
<td><a class="tltle" href="/item/main.naver?code=251340">KODEX 코스닥150선물인버스</a></td>
<td class="number">3,685</td>
<td class="number">
<img alt="상승" height="6" src="https://ssl.pstatic.net/imgstock/images/images4/ico_up.gif" style="margin-right:4px;" width="7"/><span class="tah p11 red02">
40
</span>
</td>
<td class="number">
<span class="tah p11 red01">
+1.10%
</span>
</td>
<td class="number">123,511,124</td>
<td class="number">455,402</td>
<td class="number">3,685</td>
<td class="number">3,690</td>
<td class="number">12,625</td>
<td class="number">N/A</td>
<td class="number">N/A</td>
</tr>
# stockTable 리스트의 네번째 요소 확인
stockTable[3]
----------------------------====-----
<tr>
<td class="no">2</td>
<td><a class="tltle" href="/item/main.naver?code=252670">KODEX 200선물인버스2X</a></td>
<td class="number">2,705</td>
<td class="number">
<img alt="상승" height="6" src="https://ssl.pstatic.net/imgstock/images/images4/ico_up.gif" style="margin-right:4px;" width="7"/><span class="tah p11 red02">
25
</span>
</td>
<td class="number">
<span class="tah p11 red01">
+0.93%
</span>
</td>
<td class="number">118,608,829</td>
<td class="number">321,883</td>
<td class="number">2,705</td>
<td class="number">2,710</td>
<td class="number">18,283</td>
<td class="number">N/A</td>
<td class="number">N/A</td>
</tr>
# stockTable 리스트의 여덟번째 요소 확인
stockTable[7]
-------------------
<tr><td class="blank_06" colspan="12"></td></tr>두번째 요소는 건너띄고, 세번째 요소부터 추출하고자 하는 데이터가 존재합니다. 세번째 요소에 대해서 select 함수를 활용하여 <td>태그를 선택하겠습니다. 아래 bold체로 표시된 데이터를 추출해야 합니다.
# stockTable 세번째 요소에 접근
# select 함수를 활용하여 <td>태그를 선택
stockTable[2].select("td")
-----------------------------------------
[<td class="no">1</td>,
<td><a class="tltle" href="/item/main.naver?code=251340">KODEX 코스닥150선물인버스</a></td>,
<td class="number">3,685</td>,
<td class="number">
<img alt="상승" height="6" src="https://ssl.pstatic.net/imgstock/images/images4/ico_up.gif" style="margin-right:4px;" width="7"/><span class="tah p11 red02">
40
</span>
</td>,
<td class="number">
<span class="tah p11 red01">
+1.10%
</span>
</td>,
<td class="number">123,511,124</td>,
<td class="number">455,402</td>,
<td class="number">3,685</td>,
<td class="number">3,690</td>,
<td class="number">12,625</td>,
<td class="number">N/A</td>,
<td class="number">N/A</td>]stockTable[2].select(“td”) 요소 중 4번째 요소를 제외한 모든 요소에 대해서 <td> 태그에 있는 text만 가져오면 됩니다. 4번째 요소에서 원하는 정보를 가져오려면 1) <span>에 포함된 텍스트(40)를 가져오고, 2) <img> 태그의 alt 속성값(“상승”)을 가져와서 적절히 결합해야 합니다.
# 추출을 원하는 텍스트에 접근한 후 결과값을 출함
print(stockTable[2].select('td')[0].text)
print(stockTable[2].select('td')[1].text)
print(stockTable[2].select('td')[2].text)
print(stockTable[2].select('td')[3].find('span').text.strip()+'원 '+stockTable[2].select('td')[3].find('img').get('alt'))
print(stockTable[2].select('td')[4].text.strip())
print(stockTable[2].select('td')[5].text)
print(stockTable[2].select('td')[6].text)
print(stockTable[2].select('td')[7].text)
print(stockTable[2].select('td')[8].text)
print(stockTable[2].select('td')[9].text)
print(stockTable[2].select('td')[10].text)
print(stockTable[2].select('td')[11].text)
-------------------------------------------------------
1
KODEX 코스닥150선물인버스
3,685
40원 상승
+1.10%
123,511,124
455,402
3,685
3,690
12,625
N/A
N/A신규 리스트를 생성하여 위의 결과값을 칼럼명과 함께 저장합니다.
# 정보를 저장할 신규 리스트 생성
stockData = []
# 칼럼명과 정보의 포맷을 수정하여 저장
stockData.append({colNames[0]:int(stockTable[2].select('td')[0].text),
colNames[1]:stockTable[2].select('td')[1].text,
colNames[2]+"(원)":int(stockTable[2].select('td')[2].text.replace(",","")),
colNames[3]:stockTable[2].select('td')[3].find('span').text.strip()+'원 '+stockTable[2].select('td')[3].find('img').get('alt'),
colNames[4]:stockTable[2].select('td')[4].text.strip(),
colNames[5]+"(건)":int(stockTable[2].select('td')[5].text.replace(",","")),
colNames[6]+"(백만)":int(stockTable[2].select('td')[6].text.replace(",","")),
colNames[7]+"(원)":int(stockTable[2].select('td')[7].text.replace(",","")),
colNames[8]+"(원)":int(stockTable[2].select('td')[8].text.replace(",","")),
colNames[9]+"(억)":int(stockTable[2].select('td')[9].text.replace(",","")),
colNames[10]+"(배)":stockTable[2].select('td')[10].text.replace(",",""),
colNames[10]+"(%)":stockTable[2].select('td')[11].text.replace(",","")
})
stockData
-----------------------------------------
[{'N': 1,
'종목명': 'KODEX 코스닥150선물인버스',
'현재가(원)': 3685,
'전일비': '40원 상승',
'등락률': '+1.10%',
'거래량(건)': 123511124,
'거래대금(백만)': 455402,
'매수호가(원)': 3685,
'매도호가(원)': 3690,
'시가총액(억)': 12625,
'PER(배)': 'N/A',
'PER(%)': 'N/A'}]위의 작업을 stockTable 리스트에 있는 세번째 이후의 모든 요소에 대해서 반복하여 수행해야 합니다.
stockData = []
for tempStockData in stockTable[2:] :
stockData.append({
colNames[0]:int(tempStockData.select('td')[0].text),
colNames[1]:tempStockData.select('td')[1].text,
colNames[2]+"(원)":int(tempStockData.select('td')[2].text.replace(",","")),
colNames[3]:tempStockData.select('td')[3].find('span').text.strip()+'원 '+ tempStockData.select('td')[3].find('img').get('alt'),
colNames[4]:tempStockData.select('td')[4].text.strip(),
colNames[5]+"(건)":int(tempStockData.select('td')[5].text.replace(",","")),
colNames[6]+"(백만)":int(tempStockData.select('td')[6].text.replace(",","")),
colNames[7]+"(원)":int(tempStockData.select('td')[7].text.replace(",","")),
colNames[8]+"(원)":int(tempStockData.select('td')[8].text.replace(",","")),
colNames[9]+"(억)":int(tempStockData.select('td')[9].text.replace(",","")),
colNames[10]+"(배)":tempStockData.select('td')[10].text,
colNames[11]+"(%)":tempStockData.select('td')[11].text
})
-------------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[102], line 5
1 stockData = []
3 for tempStockData in stockTable[2:] :
4 stockData.append({
----> 5 colNames[0]:int(tempStockData.select('td')[0].text),
6 # colNames[1]:tempStockData.select('td')[1].text,
7 # colNames[2]+"(원)":int(tempStockData.select('td')[2].text.replace(",","")),
8 # colNames[3]:tempStockData.select('td')[3].find('span').text.strip()+'원 '+ tempStockData.select('td')[3].find('img').get('alt'),
9 # colNames[4]:tempStockData.select('td')[4].text.strip(),
10 # colNames[5]+"(건)":int(tempStockData.select('td')[5].text.replace(",","")),
11 # colNames[6]+"(백만)":int(tempStockData.select('td')[6].text.replace(",","")),
12 # colNames[7]+"(원)":int(tempStockData.select('td')[7].text.replace(",","")),
13 # colNames[8]+"(원)":int(tempStockData.select('td')[8].text.replace(",","")),
14 # colNames[9]+"(억)":int(tempStockData.select('td')[9].text.replace(",","")),
15 # colNames[10]+"(배)":tempStockData.select('td')[10].text,
16 # colNames[11]+"(%)":tempStockData.select('td')[11].text
17 })
ValueError: invalid literal for int() with base 10: ''에러가 발생합니다. 왜 그럴까요? 두 가지 이유가 있습니다.
첫째, 우리가 추출하고자 하는 데이터 중간 중간에 공백이 존재합니다. 해당 정보는 위의 코드로 저장할 수 없는 데이터이기 때문에 제외해야 합니다.
둘째, “전월비” 칼럼을 표현하는 요소들이 다양하고, 일관되지 않습니다. img 태그 존재 여부, alt 속성값 존재 여부 등에 따라 많이 다릅니다.
두 가지 요소를 모두 고려하여 위의 코드를 수정해야 합니다.
stockData = []
for tempStockData in stockTable[2:] :
# 첫번재 이유 해결 코드
if len(tempStockData.select('td')) > 1 :
# 두번째 이유 해결 코드
if tempStockData.select('td')[3].find('img') == None :
temp = '동일'
elif tempStockData.select("td")[3].find("span").get("class")[-1].find('red') == 0 :
temp = tempStockData.select('td')[3].find('span').text.strip()+'원 상승'
else :
temp = tempStockData.select('td')[3].find('span').text.strip()+'원 하락'
stockData.append({
colNames[0]:int(tempStockData.select('td')[0].text),
colNames[1]:tempStockData.select('td')[1].text,
colNames[2]+"(원)":int(tempStockData.select('td')[2].text.replace(",","")),
colNames[3]:temp,
colNames[4]:tempStockData.select('td')[4].text.strip(),
colNames[5]+"(건)":int(tempStockData.select('td')[5].text.replace(",","")),
colNames[6]+"(백만)":int(tempStockData.select('td')[6].text.replace(",","")),
colNames[7]+"(원)":int(tempStockData.select('td')[7].text.replace(",","")),
colNames[8]+"(원)":int(tempStockData.select('td')[8].text.replace(",","")),
colNames[9]+"(억)":int(tempStockData.select('td')[9].text.replace(",","")),
colNames[10]+"(배)":tempStockData.select('td')[10].text,
colNames[11]+"(%)":tempStockData.select('td')[11].text
})
stockData
----------------------------------------
[{'N': 1,
'종목명': 'KODEX 코스닥150선물인버스',
'현재가(원)': 3685,
'전일비': '40원 상승',
'등락률': '+1.10%',
'거래량(건)': 123511124,
'거래대금(백만)': 455402,
'매수호가(원)': 3685,
'매도호가(원)': 3690,
'시가총액(억)': 12625,
'PER(배)': 'N/A',
'ROE(%)': 'N/A'},
{'N': 2,
'종목명': 'KODEX 200선물인버스2X',
'현재가(원)': 2705,
'전일비': '25원 상승',
'등락률': '+0.93%',
'거래량(건)': 118608829,
'거래대금(백만)': 321883,
'매수호가(원)': 2705,
'매도호가(원)': 2710,
'시가총액(억)': 18283,
'PER(배)': 'N/A',
'ROE(%)': 'N/A'},
{'N': 3,
'종목명': '삼부토건',
'현재가(원)': 3370,
'전일비': '320원 상승',
'등락률': '+10.49%',
'거래량(건)': 51775159,
'거래대금(백만)': 169722,
'매수호가(원)': 3365,
'매도호가(원)': 3370,
'시가총액(억)': 6884,
'PER(배)': '-8.60',
'ROE(%)': '-35.88'},
...
]데이터가 잘 저장된 것을 확인할 수 있습니다.
데이터프레임으로 전환 및 엑셀로 저장
리스트 형태의 stockData 를 데이터프레임으로 전환하고, 엑셀로 저장합니다.
import pandas as pd
stockDataDataFrame = pd.DataFrame(stockData)
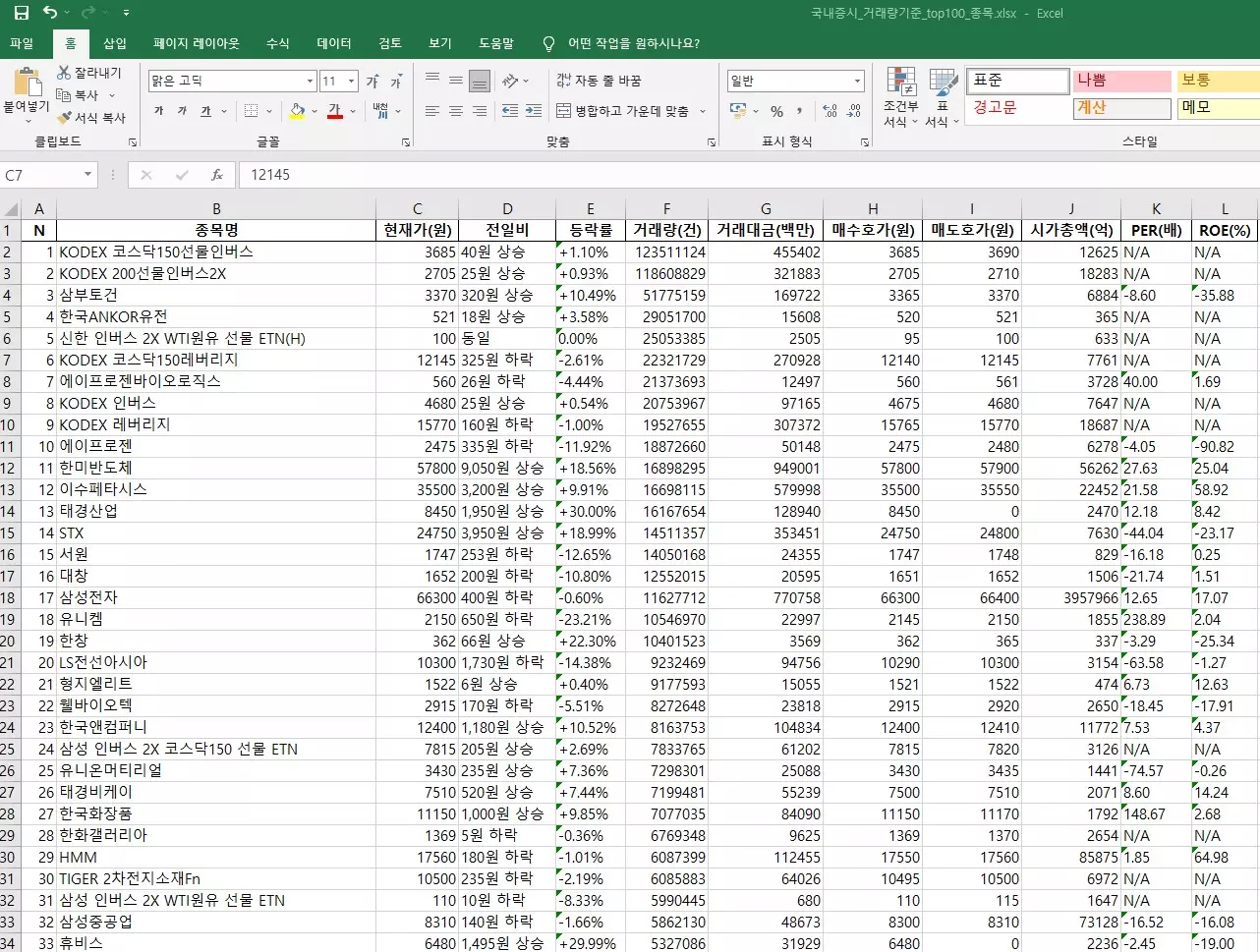
stockDataDataFrame.to_excel("D:/국내증시_거래량기준_top100_종목.xlsx", index = False)D드라이브에 국내증시_거래량기준_top100_종목.xlsx 파일이 생성되었음을 확인하실 수 있습니다.
최종 파이썬 코드 정리
아래 코드는 위에서 설명 드린 파이썬 코드를 데이터 추출에 필요한 필수 코드만 추려서 정리한 결과입니다.
import pandas as pd
import requests
from bs4 import BeautifulSoup
url = "https://finance.naver.com/sise/sise_quant.naver?sosok=0"
response = requests.get(url)
data = response.text
soup = BeautifulSoup(data, 'html.parser')
stockTable = soup.select("table.type_2 tr")
# 칼럼명 추출
colNames = []
for tempColnames in stockTable[0].select('th') :
colNames.append(tempColnames.text)
colNames
# 데이터 저장
stockData = []
for tempStockData in stockTable[2:] :
if len(tempStockData.select('td')) > 1 :
if tempStockData.select('td')[3].find('img') == None :
전일비 = '동일'
elif tempStockData.select("td")[3].find("span").get("class")[-1].find('red') == 0 :
전일비 = tempStockData.select('td')[3].find('span').text.strip()+'원 상승'
else :
전일비 = tempStockData.select('td')[3].find('span').text.strip()+'원 하락'
stockData.append({
colNames[0]:int(tempStockData.select('td')[0].text),
colNames[1]:tempStockData.select('td')[1].text,
colNames[2]+"(원)":int(tempStockData.select('td')[2].text.replace(",","")),
colNames[3]:전일비,
colNames[4]:tempStockData.select('td')[4].text.strip(),
colNames[5]+"(건)":int(tempStockData.select('td')[5].text.replace(",","")),
colNames[6]+"(백만)":int(tempStockData.select('td')[6].text.replace(",","")),
colNames[7]+"(원)":int(tempStockData.select('td')[7].text.replace(",","")),
colNames[8]+"(원)":int(tempStockData.select('td')[8].text.replace(",","")),
colNames[9]+"(억)":int(tempStockData.select('td')[9].text.replace(",","")),
colNames[10]+"(배)":tempStockData.select('td')[10].text,
colNames[11]+"(%)":tempStockData.select('td')[11].text
})
# 저장 데이터 => 데이터프레임으로 전환
stockDataDataFrame = pd.DataFrame(stockData)
# 엑셀 파일로 장
stockDataDataFrame.to_excel("D:/국내증시_거래량기준_top100_종목.xlsx", index = False)