이번 포스팅에서는 지난 번 포스팅(파이썬을 활용한 스크랩핑 실습1) 내용에 이어서 파이썬을 활용한 스크랩핑 방법에 대해서 알아 보겠습니다. 네이버 증권 메뉴에서 국내 증시에 상장된 모든 종목의 주식 관련 기본 정보를 시가총액 기준으로 정렬하여 엑셀로 저장해 보겠습니다 (본 포스팅 글을 이해하려면 파이썬을 활용한 스크랩핑 실습1을 먼저 선행하셔야 합니다.).
시가총액 기준으로 정렬된 주식 종목 확인하기
우선, 네이버 증권 메뉴에서 시가총액 기준으로 정렬된 주식 종목이 들어 있는 데이터를 확인합니다. https://finance.naver.com/sise/sise_market_sum.naver?&page=1 링크를 클릭하면 아래와 같은 네이버 증권 화면이 나옵니다. 파란색으로 표시된 영역에 우리가 추출하고자 하는 데이터가 있습니다.
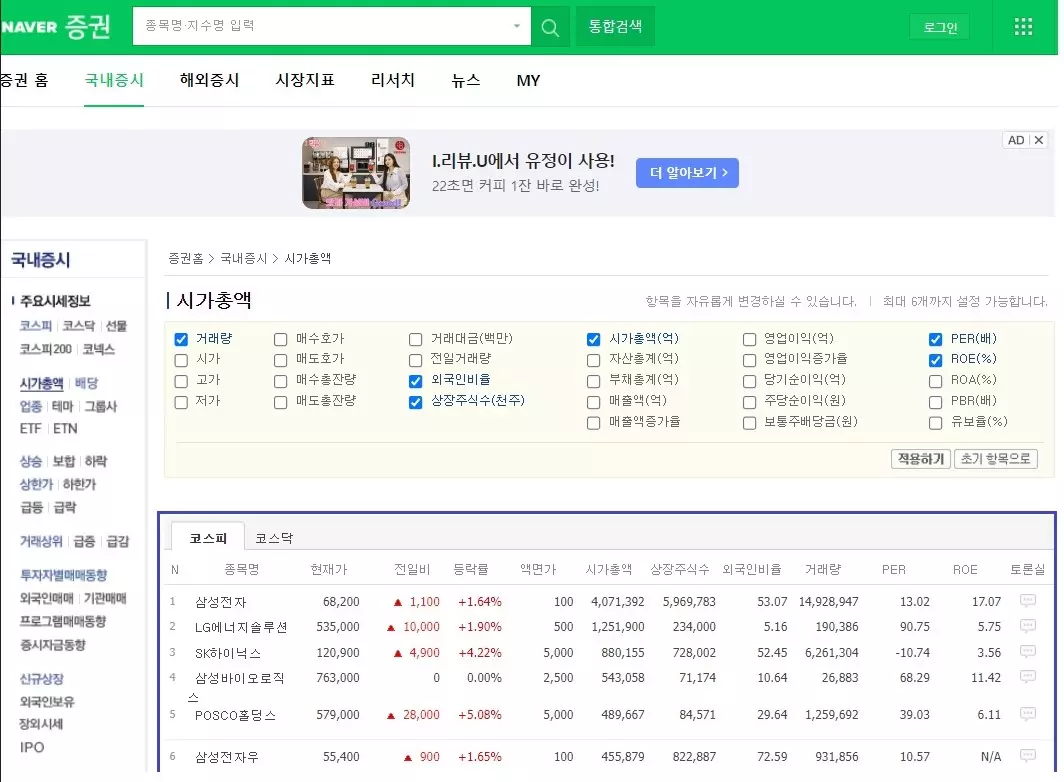
위의 그림에서는 N = 6 까지의 데이터가 보이지만, 마우스 스크롤을 아래로 내리면, 아래 그림과 같이 50개의 종목이 보입니다.
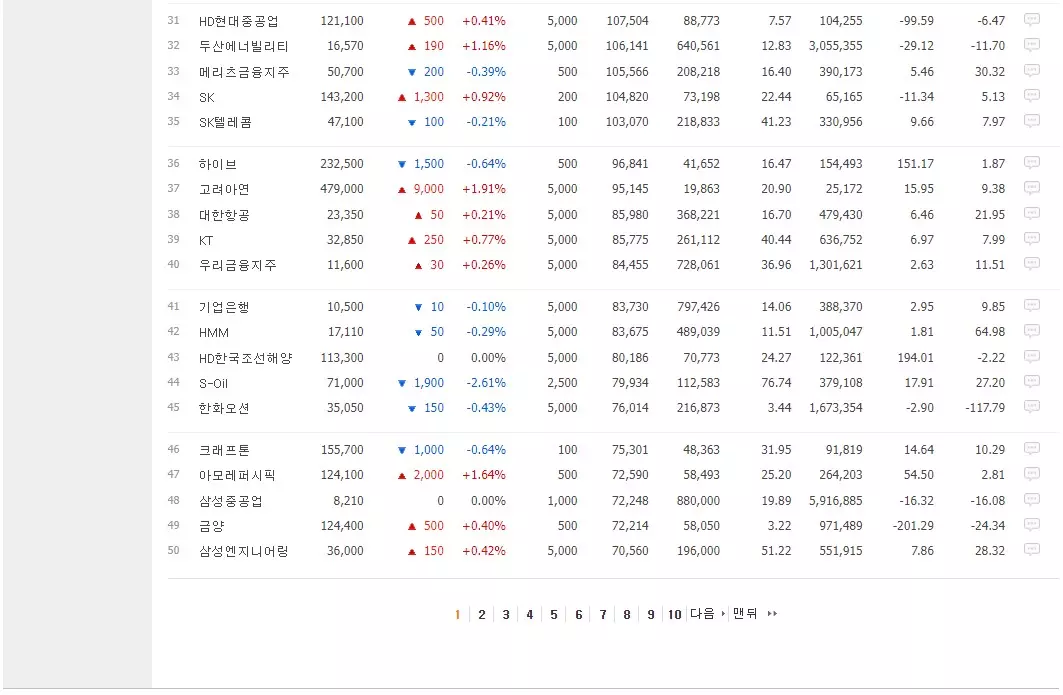
다음 50개의 종목을 보려면, 하단에 있는 “2”를 클릭합니다. 그러면, 해당 url 주소는 https://finance.naver.com/sise/sise_market_sum.naver?&page=2 가 되고, N = 51 부터 50개의 종목이 보입니다.
- https://finance.naver.com/sise/sise_market_sum.naver?&page=3은 그 다음 50개의 종목
- https://finance.naver.com/sise/sise_market_sum.naver?&page=4는 그 다음 50개의 종목
- …
- https://finance.naver.com/sise/sise_market_sum.naver?&page=42까지 종목이 보입니다.
만약, url 주소창에서 https://finance.naver.com/sise/sise_market_sum.naver?&page=43을 입력하면 어떻게 될까요? 아래 그림처럼, 어떤 종목도 나오지 않습니다.
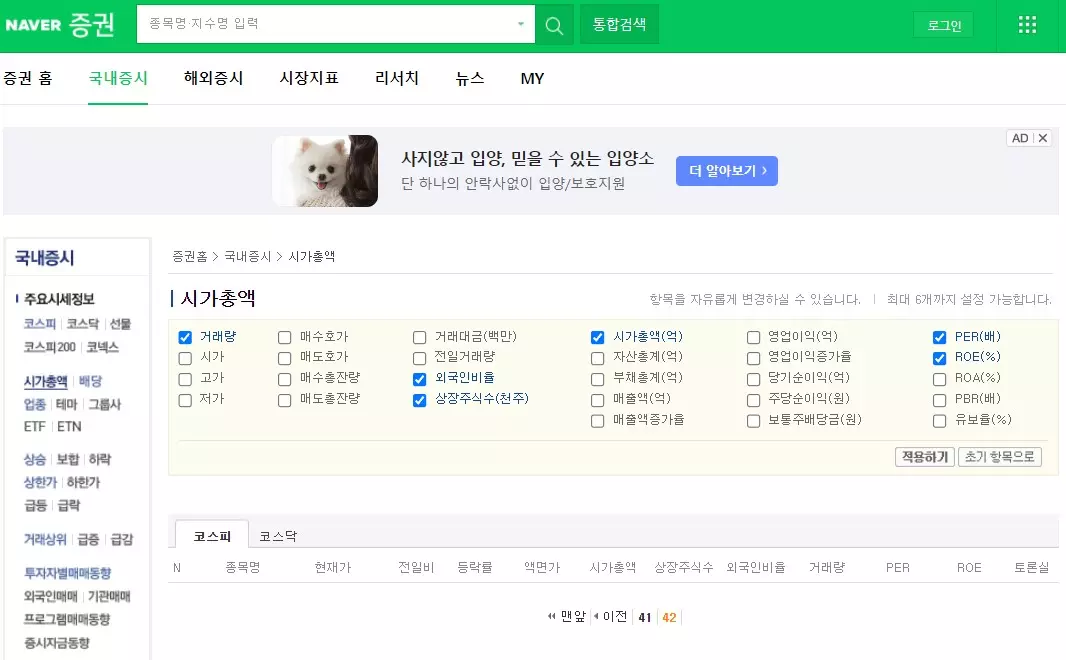
뭔가 패턴이 보이는 것 같습니다.
주식 종목 데이터가 있는 URL 주소 패턴 확인하기
URL 주소의 패턴은 https://finance.naver.com/sise/sise_market_sum.naver?&page=숫자 형태입니다. 숫자 = 1에서 42까지 대입하면서 url 주소를 변경하면 주식 종목이 나오고, 숫자 = 43에서는 더 이상 주식 종목 데이터가 존재하지 않습니다. 숫자를 1에서 부터 1씩 증가 시키면서 주식 종목 데이터가 있는 지 확인하여 있으면 스크랩핑하여 저장하고, 없으면 더 이상 해당 작업을 수행하지 않으면 됩니다. 이를 함수로 작성해 보겠습니다.
주식 종목 가져와서 저장하는 함수 만들기
1차 함수 만들기
파이썬을 활용한 스크랩핑 실습1 포스팅에서 작성한 코드를 조금 수정하여 필요한 함수를 생성합니다.
def listed_company(no) :
url = f"https://finance.naver.com/sise/sise_market_sum.naver?&page={no}"
response = requests.get(url)
data = response.text
soup = BeautifulSoup(data, 'html.parser')
stockTable = soup.select("table.type_2 tr")
# 칼럼명 추출
colNames = []
for tempColnames in stockTable[0].select('th') :
colNames.append(tempColnames.text)
# 데이터 저장
stockData = []
for tempStockData in stockTable[2:] :
if len(tempStockData.select('td')) > 1 :
if tempStockData.select('td')[3].find('img') == None :
전일비 = '동일'
elif tempStockData.select("td")[3].find("span").get("class")[-1].find('red') == 0 :
전일비 = tempStockData.select('td')[3].find('span').text.strip()+'원 상승'
else :
전일비 = tempStockData.select('td')[3].find('span').text.strip()+'원 하락'
stockData.append({
colNames[0]:int(tempStockData.select('td')[0].text),
colNames[1]:tempStockData.select('td')[1].text,
colNames[2]+"(원)":int(tempStockData.select('td')[2].text.replace(",","")),
colNames[3]:전일비,
colNames[4]:tempStockData.select('td')[4].text.strip(),
colNames[5]+"(원)":int(tempStockData.select('td')[5].text.replace(",","")),
colNames[6]+"(억)":int(tempStockData.select('td')[6].text.replace(",","")),
colNames[7]+"(천주)":int(tempStockData.select('td')[7].text.replace(",","")),
colNames[8]+"(%)":float(tempStockData.select('td')[8].text),
colNames[9]:int(tempStockData.select('td')[9].text.replace(",","")),
colNames[10]+"(배)":tempStockData.select('td')[10].text,
colNames[11]+"(%)":tempStockData.select('td')[11].text
})
stockDataDataFrame = pd.DataFrame(stockData)
return stockDataDataFrame위의 함수는 1개의 매개변수를 가지고 있습니다.
- listed_company(1) : https://finance.naver.com/sise/sise_market_sum.naver?&page=1에 있는 주식 종목을 가져와서 stockDataDataFrame 에 저장합니다.
- listed_company(2) : https://finance.naver.com/sise/sise_market_sum.naver?&page=2에 있는 주식 종목을 가져와서 stockDataDataFrame 에 저장합니다.
- …
위의 함수만 계속 사용하게 되면, 50개씩 새로운 주식 종목을 가져와서 동일한 stockDataDataFrame 객체에 저장하기 때문에, 가장 마지막에 수행된 함수의 결과값만 stockDataDataFrame에 저장하게 됩니다. 이를 방지하려면 모든 종목을 저장하기 위한 신규 데이터프레임을 생성하고, 누적하여 저장하여야 합니다.
최종 함수 만들기
위에서 설명한 최종 함수는 아래와 같이 작성 가능합니다.
def final_listed_company(no = 1) :
tempData = listed_company(no)
finalListedCompany = pd.DataFrame()
finalListedCompany = pd.concat([finalListedCompany, tempData])
while not tempData.empty :
tempData = listed_company(no + 1)
finalListedCompany = pd.concat([finalListedCompany, tempData])
no += 1 ;
finalListedCompany.to_excel('D:/코스피_상장사_주식_정보.xlsx', index = False)
return finalListedCompany
finalListedCompany = final_listed_company(1) - def final_listed_company(no = 1) : no의 기본값 1을 가지는 함수 final_listed_company를 정의합니다.
- tempData = listed_company(no) : https://finance.naver.com/sise/sise_market_sum.naver?&page=1 url 주소에서 주식 종목을 스크랩핑해서 가져온 데이터를 tempData에 저장합니다.
- finalListedCompany = pd.DataFrame() : finalListedCompany 데이터프레임 객체를 신규 생성합니다.
- finalListedCompany = pd.concat([finalListedCompany, tempData]) : finalListedCompany 데이터프레임과 tempData 데이터프레임을 결합합니다. finalListedCompany 에는 50개의 종목이 저장되어 있습니다.
- while not tempData.empty : : tempData 데이터프레임이 비어 있지 않은 경우, 아래 3개의 코드를 계속 수행합니다.
- tempData = listed_company(no + 1) :
finalListedCompany = pd.concat([finalListedCompany, tempData])
no += 1 ;
- tempData = listed_company(no + 1) :
- finalListedCompany.to_excel(‘D:/코스피_상장사_주식_정보.xlsx’, index = False) : 최종적으로 생성된 finalListedCompany 데이터프레임을 D드라이브 안에 “코스피_상장사_주식_정보.xlsx” 파일명으로 저장합니다.
아래 동영상을 보시면, 실제 엑셀 파일이 저장되는 것을 확인하실 수 있습니다.