데이터 분석가들은 데이터 시각화(Data Visualization)를 통해 데이터를 더 잘 이해할 수 있다는 것을 알고 있습니다. 데이터 시각화는 통찰력을 얻는 데 도움이 될 뿐만 아니라 우리의 통찰력을 타인에게 쉽게 설명할 수 있게 해줍니다. Python에서 가장 일반적으로 사용되는 시각화 라이브러리에는 Matplotlib 이 있습니다.
따라서 더 나은 시각화를 만드는 방법을 배우는 것은 모든 데이터 분석가에게 필수적이라고 할 수 있습니다. Matplotlib(Mathematical Plotting Library)는 Python의 기본 데이터 시각화 라이브러리 중 하나입니다.
화가가 캔버스에 걸작을 만들기 위해 브러시를 사용하는 것처럼 Matplotlib는 데이터 과학자와 분석가가 데이터를 사용하여 다양하고 통찰력 있는 차트를 만들 수 있도록 지원합니다. 따라서 이번 포스팅에서는 Matplotlib 라이브러리에 대해서 알아 보겠습니다.
기본 플로팅
먼저, 플로팅 기능에 접근하려면 matplotlib.pyplot을 가져와야 합니다.
간단한 선 도표 그리기
이름에서 알 수 있듯이 데이터 포인트는 직선으로 연결되어 있습니다. 이는 범위에 걸쳐 지속적으로 변하는 데이터를 표시하는 데 매우 유용합니다.
패턴과 추세를 쉽게 식별할 수 있습니다. 간단한 선 플롯에는 plt.plot(x,y)를 사용하고 플롯을 표시하려면 plt.show()를 사용하면 됩니다.
import matplotlib.pyplot as plt
# 월간 웹사이트 트래픽(천 단위)을 나타내는 임시 데이터 생성
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun']
traffic = [150, 200, 180, 220, 250, 210]
# 선 플롯 생성하기
plt.plot(months, traffic)
plt.show()
라벨과 제목이 없는 매우 단순한 그래프입니다.
라벨, 색상, 스타일에 대한 사용자 정의 옵션
플롯에 옵션을 주면 훨씬 명확하게 정보를 전달할 수 있습니다. Matplotlib은 색상, 선 스타일, 마커 등을 제어할 수 있는 다양한 사용자 정의 옵션을 제공합니다.
레이블 및 제목 추가: plt.xlabel(), plt.ylabel() 및 plt.title() 사용
import matplotlib.pyplot as plt
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun']
traffic = [150, 200, 180, 220, 250, 210]
# line plot 생성하기
plt.plot(months, traffic)
# 라벨과 제목 추가하기
plt.xlabel('Month')
plt.ylabel('Monthly Traffic (in Thousands)')
plt.title('Monthly Website Traffic')
plt.show()
- 참고: plt.show()는 항상 플롯 설정의 끝에 있어야 합니다. plt.show() 뒤에 label 명령을 주면 표시되지 않습니다.
색상 및 선 스타일 변경
매개변수 marker를 사용하여 점을 표시합니다. linetsyle을 사용하여 선 스타일을 변경합니다. plt.grid(True)를 사용하여 플롯에 그리드를 추가합니다.
# marker, linestyle, color 매개변수 사용
plt.plot(months, traffic, marker='o', linestyle='--', color='g')
# 라벨과 제목 추가
plt.xlabel('Month')
plt.ylabel('Monthly Traffic (in Thousands)')
plt.title('Monthly Website Traffic')
# 그리드 추가
plt.grid(True)
# 그래프 출력
plt.show()
플롯 스타일 변경
Matplotlib에는 다양한 스타일이 있습니다. 사용 가능한 스타일을 확인하려면 plt.style.available 명령을 사용하시면 됩니다. 전체 플롯의 스타일을 변경하려면 plt.style.use(‘desired_style’)을 사용하면 됩니다.
만화 스타일 플롯을 사용하려면 plt.xkcd()를 사용하면 아래와 같은 멋진 플롯이 제공됩니다. 이는 전체 노트북의 플롯 스타일을 변경합니다. 기본값으로 변경하려면 plt.style.use(‘default’)를 사용하시면 됩니다.
참고: plt.show() 전에 이러한 스타일 명령을 사용해야 합니다.
그림 크기 변경
플롯 크기를 조정하려면 plt.Figure(figsize=(x_size,y_size)) 를 사용해야 합니다. .plot 명령어를 입력하기 전에 이것을 사용해야 합니다.
라벨 사용
동일한 그래프에 여러 선을 그리는 경우 원하는 변수에 대해 Plot 명령을 두 번 사용하면 됩니다. 이 경우 여러 선을 적절하게 구분하여 주는 것이 필요합니다. 이를 위해 label이라는 매개변수와 plt.legend()를 사용하면 됩니다.
# 두 제품의 월별 수익을 나타내는 예시 데이터
months = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun']
product_a_revenue = [45, 55, 60, 70, 80, 75]
product_b_revenue = [35, 40, 50, 55, 70, 68]
# 파란색과 원 표식을 가지는 제품 A를 표현하는 line plot 생성하기
plt.plot(months, product_a_revenue, marker='o', linestyle='-', color='blue', label='Product A')
# 빨간 점선과 square 표식을 가지는 제품 B를 표현하는 line plot 생성하기
plt.plot(months, product_b_revenue, marker='s', linestyle='--', color='red', label='Product B')
# 라벨과 제목 추가
plt.xlabel('Month')
plt.ylabel('Monthly Revenue (in $1000)')
plt.title('Monthly Revenue Comparison')
# 제품 A와 B 사이의 차이점을 설명하는 범례 표시
plt.legend()
# 그래프 출력
plt.show()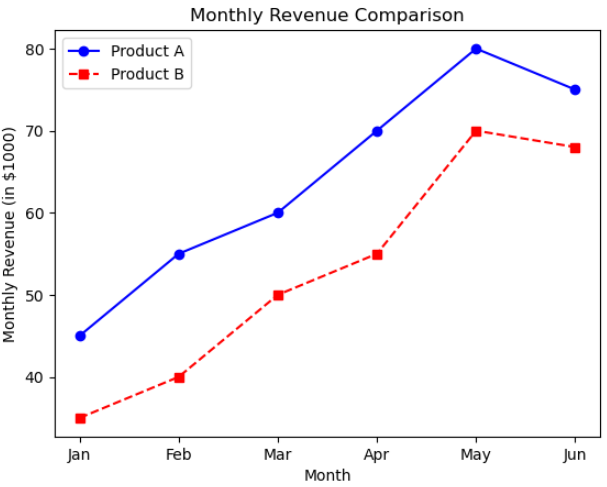
Matplotlib 플롯을 이미지 파일로 저장
Matplotlib을 사용하면 플롯을 이미지 파일로 저장할 수 있습니다.
주피터 노트북에서 저장하기
주피터 노트북에서 작업할 때 플롯을 이미지 파일로 저장하려면 plt.savefig(‘path/to/directory/plot_name.png’) 를 사용하면 됩니다. 전체 파일 경로를 지정할 수 있고 원하는 파일 이름과 형식(예: .jpg, .png, .pdf )을 지정할 수 있습니다.
Google Colab에서 저장하기
Google Colab에서 작업할 때 플롯을 이미지 파일로 저장하려면 먼저 드라이브를 마운트하고 plt.savefig()를 사용해야 합니다.
from google.colab import drive
# Google Drive 마운트
drive.mount('/content/drive')
# Colab에서 이미지 파일로 플롯 저장하기
# My Drive 이후에 폴더 위치 변경 가
plt.savefig('/content/drive/My Drive/'+'my_plot.png')플롯 유형
이전 섹션에서 기본적인 선 그래프를 보았습니다. 하지만 Matplotlib에는 막대 차트, 히스토그램, 산점도, 원형 차트, 상자 그림(상자 및 수염 그림), 히트맵, 이미지 표시 등 훨씬 더 많은 종류의 플롯이 있습니다.
이제 몇 가지 사용 사례와 함께 언제 사용해야 하는지 알아 보겠습니다.
막대 차트(Bar Chart)
막대 차트는 직사각형 막대로 범주형 데이터를 나타냅니다. 각 막대의 길이나 높이는 값을 나타냅니다. plt.bar(x,y) 명령을 사용하여 수직 막대 차트를 생성하고 plt.barh(x,y) 명령을 사용하여 수평 막대 차트를 생성할 수 있습니다.
몇 가지 사용 사례:
- 다양한 제품의 판매 실적 비교
- 국가별 인구 분포
예: 단일 그래프의 다중 막대 플롯
import numpy as np
# 비용 항목
categories = ['Housing', 'Transportation', 'Food', 'Entertainment', 'Utilities']
# Alice, Bob, Carol의 월별 비용
alice_expenses = [1200, 300, 400, 200, 150]
bob_expenses = [1100, 320, 380, 180, 140]
carol_expenses = [1300, 280, 420, 220, 160]
# x축 위치에 대한 배열 생성
x = np.arange(len(categories))
# 막대의 너비는 여러 막대를 플롯하려고 하므로 필요
bar_width = 0.2
# Alice의 비용에 대한 막대를 만들고 x 배열에서 막대 너비를 뺍니다.
# 그래서 왼쪽에 놓이게 됩니다.
plt.bar(x - bar_width, alice_expenses, width=bar_width, label='Alice', color='skyblue')
# bars for Bob's 비용을 나타내는 막대 생성
plt.bar(x, bob_expenses, width=bar_width, label='Bob', color='lightcoral')
# Create bars for Carol의 비용을 나타내는 막대 생성 및 너비를 X축으로 하는 막대 추가
# 오른쪽에 배치
plt.bar(x + bar_width, carol_expenses, width=bar_width, label='Carol', color='lightgreen')
# 라벨, 제목, 범례 추가
plt.xlabel('Expense Categories')
plt.ylabel('Monthly Expenses (USD)')
plt.title('Monthly Expenses Comparison')
# x축 위치에 카테고리 이름 표시
plt.xticks(x, categories)
plt.legend()
# 그래프 출력
plt.show()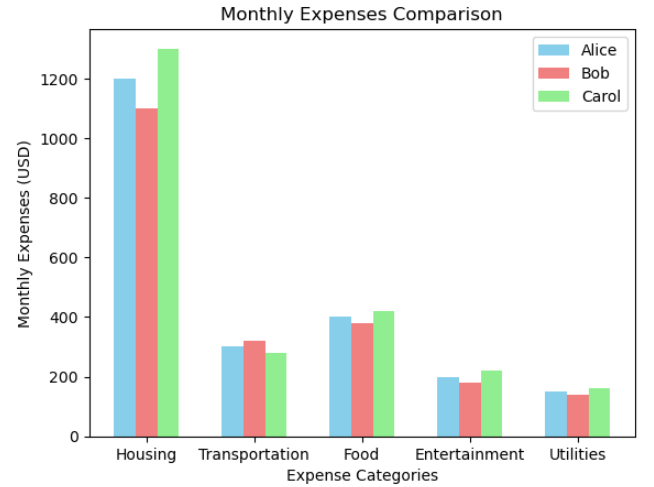
따라서 이러한 막대를 얻으려면 우선, 첫 번째 막대에서 막대 너비로 x 레이블을 빼야 합니다. 마지막 막대에서는 막대 너비로 레이블을 추가했습니다. width 매개변수를 모든 막대 너비와 동일하게 설정했습니다.
히스토그램(Histogram)
연속 데이터 또는 수치 데이터의 분포를 시각화하는 데 히스토그램을 사용합니다. 데이터의 패턴을 식별하는 데 도움이 됩니다. 히스토그램 플롯에서 데이터는 “bin”으로 그룹화되며 각 막대의 높이는 해당 bin에 있는 데이터 포인트의 빈도 또는 개수를 나타냅니다. 주어진 데이터의 하한과 상한을 취해 주어진 bin 수로 나눕니다.
plt.hist(x) 명령을 사용하여 히스토그램을 생성합니다. 막대 그래프와 달리 여기서는 하나의 연속 데이터의 빈도만 나타내므로 ‘y’가 필요하지 않습니다. bin의 기본값은 10개이며 변경할 수 있습니다. 원하는 bin 범위로 bin 범위를 재정의할 수 있습니다. 막대의 가장자리 색상을 추가할 수도 있습니다.
히스토그램 플롯과 함께 동일한 그래프에서 평균 또는 중앙값과 같은 선을 추가할 수 있습니다.
값을 계산하고 plt.axvline(calculated_mean,label=desired_label) 에 전달하면 됩니다. 이는 다른 플롯과 함께 사용할 수 있습니다.
몇 가지 사용 사례:
- 인구의 연령 분포 분석
- 교실에서의 시험 점수 분포 조사
import numpy as np
import matplotlib.pyplot as plt
# 시험 점수 자료
examScores = [68, 72, 75, 80, 82, 84, 86, 90, 92, 95, 98, 100]
# bin 정의
binRanges = [60, 70, 80, 90, 100]
# 히스토그램 생성
plt.hist(examScores, bins = binRanges, color = 'lightblue', edgecolor = 'black', alpha = 0.7)
# 라벨과 제목 추가하기
plt.xlabel('Exam Score')
plt.ylabel('Frequency')
plt.title('Exam Scores Histogram with Custom Bins')
# 중앙값 선 계산 및 추가하기
medianScore = np.median(examScores)
plt.axvline(medianScore, color = 'red', linestyle = 'dashed', linewidth = 2, label = f'Median Score: {median_score}')
# 범례 추가
plt.legend()
# 그래프 출력
plt.show()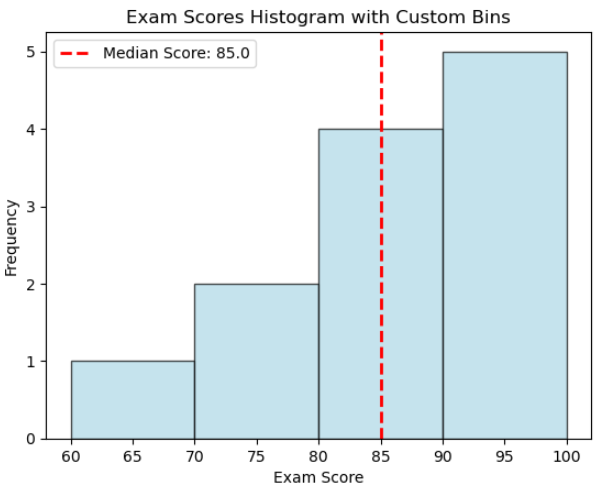
산점도(Scatter plots)
산점도(Scatter plots)는 개별 데이터 포인트를 2차원 평면에 점으로 표시합니다. 그리고 두 수치 변수 사이의 관계나 상관 관계를 탐색하는 데 사용됩니다. 여기서 각 축은 하나의 변수를 나타내고 점은 데이터 포인트를 나타냅니다.
plt.scatter(x,y)를 사용하여 분산형 차트를 생성할 수 있습니다. 점의 크기를 변경하려면 매개변수 s, c를 색상으로 사용하고 marker를 사용하여 점 대신 마커를 변경합니다. 그리고 alpha 매개변수는 색상의 강도를 조절합니다. 크기의 경우 각 지점마다 다른 크기 리스트를 보낼 수도 있습니다.
몇 가지 사용 사례:
- 학습시간과 시험점수의 관계 조사
- 기온과 아이스크림 판매량의 상관관계 분석
# 가게에 대한 예제 데이터 생성
stores = ['Store A', 'Store B', 'Store C', 'Store D', 'Store E']
customers = [120, 90, 150, 80, 200]
revenue = [20000, 18000, 25000, 17000, 30000]
storeSize = [10, 5, 15, 8, 20]
pointSizes = [size * 100 for size in storeSize]
plt.scatter(customers, revenue, s = pointSizes, c = 'skyblue', alpha = 0.7, edgecolors = 'b')
# 라벨, 제목, 범례 추가
plt.xlabel('Number of Customers')
plt.ylabel('Revenue (USD)')
plt.title('Relationship between Customers, Revenue, and Store Size')
# 그래프 출력
plt.show()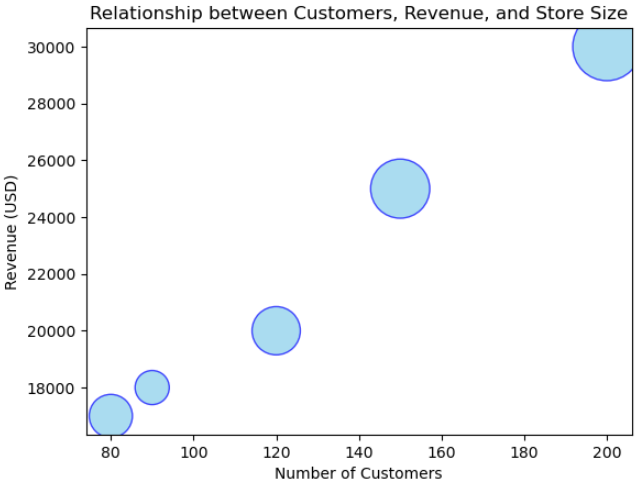
원형 차트(Pie Charts)
원형 차트(Pie Charts)는 전체의 일부를 원형 조각으로 나타냅니다. 단일 범주형 변수의 구성을 백분율로 표시하는 데 적합합니다. 하지만 6개 이상의 카테고리가 있으면 보기에 좋지 않을 수 있습니다. 그런 경우에는 가로 막대를 이용하는 것이 더 좋습니다.
plt.pie(x,labels=your_category_names, colors=desired_colors_list) 명령을 사용하시면 됩니다 .원하는 색상 리스트가 있는 경우 해당 리스트를 제공할 수 있으며 wedgeprops = {‘edgecolor’ : your_color} 매개변수를 사용하여 원형 차트의 가장자리 색상을 변경할 수도 있습니다.
또한 explode 매개변수를 사용하여 특정 세그먼트를 강조 표시할 수도 있습니다. 그리고 autopct 매개변수를 사용하면 소수점 이하의 값이 플롯에 표시될 수 있는 수를 선택할 수 있습니다.
몇 가지 사용 사례:
- 비용 항목별 예산 분포 표시
- 다양한 스마트폰 브랜드의 시장 점유율
예: 프레젠테이션 중에 더 나은 스토리텔링을 위해 특정 세그먼트를 분해합니다.
# 제품 카테고리
categories = ['Electronics', 'Clothing', 'Home Decor', 'Books', 'Toys']
# 각 카테고리별 판매 데이터
sales = [3500, 2800, 2000, 1500, 1200]
explode = (0, 0.1, 0, 0, 0)
plt.pie(sales, labels = categories, explode = explode, shadow = True, autopct = '%1.1f%%')
plt.title('Sales by Product Category')
# 그래프 출력
plt.show()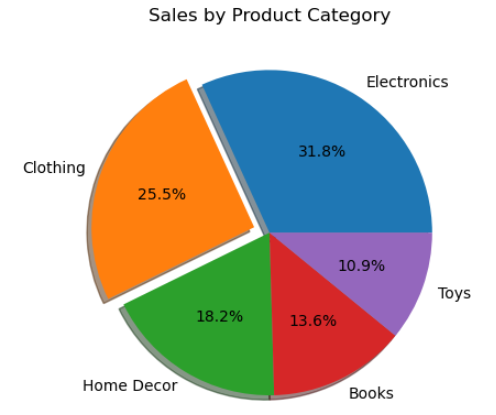
상자 그림(상자 및 수염 그림)
상자 그림은 앞서 설명했던 플롯과 비교해 볼 때, 복잡해 보일 수 있습니다. 상자 그림을 간단히 설명하면 사분위수, 이상값 및 잠재적 왜도를 표시하여 수치 데이터의 분포를 요약합니다. 이는 데이터 분, 중심 경향 및 변동성에 대한 통찰력을 제공합니다. 상자 그림은 이상값을 식별하고 분포를 비교하는 데 특히 유용합니다.
plt.boxplot(data)을 사용하여 상자 그림을 그릴 수 있습니다. boxprops 및 flierprops를 사용하여 상자 모양과 이상값을 사용자가 정의할 수 있습니다. 상자 그림을 수평으로 만들려면 vert = False를 사용하고 상자를 색상으로 채우려면 patch_artist = True를 사용하시면 됩니다.
몇 가지 사용 사례:
- 회사의 급여 분포 분석
- 다양한 지역의 주택 가격 변동성 평가
# 이상치를 가지는 임의 데이터 생성
np.random.seed(42)
data = np.concatenate([np.random.normal(0, 1, 100), np.random.normal(6, 1, 10)])
# 이상치를 가지는 상자 그림 생성
plt.figure(figsize=(8, 6)) # 그림 크기 설정
plt.boxplot(data, vert = False, patch_artist = True,
boxprops={'facecolor': 'lightblue'},
flierprops={'marker': 'o', 'markerfacecolor': 'red',
'markeredgecolor': 'red'})
# 라벨과 제목 추가
plt.xlabel('Values')
plt.title('Box Plot with Outliers')
# 그래프 출력
plt.grid(True) # 그리드 추가
plt.show()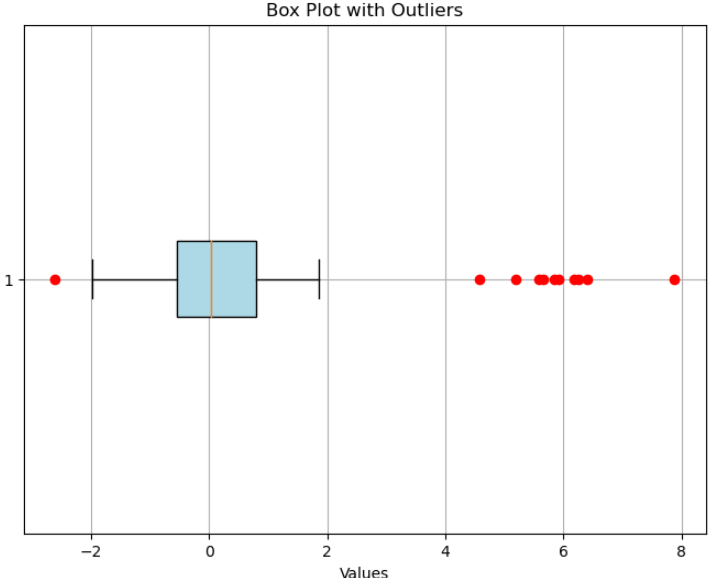
히트맵 및 이미지 표시
plt.imshow()는 2차원 이미지 데이터를 표시하거나, 2차원 배열을 시각화 하거나, 다양한 형식으로 이미지를 표시하기 위해 사용하는 Matplotlib 함수입니다.
히트맵은 상관 행렬의 시각화로, 각 변수가 다른 변수와 어떤 상관관계가 있는지를 알려줍니다. 여기서는 상관 행렬을 시각화하기 위해 히트맵을 만들고, 이 관계를 시각적으로 표시하기 위해 컬러 맵을 사용하겠습니다. 히트맵을 시각화하려면 상관 행렬을 imshow에 전달해야 합니다.
# 단순한 상관관계를 나타내는 행렬 생성
correlationMatrix = np.array([[1.0, 0.8, 0.3, -0.2],
[0.8, 1.0, 0.5, 0.1],
[0.3, 0.5, 1.0, -0.4],
[-0.2, 0.1, -0.4, 1.0]])
# 히트맵 생성
plt.imshow(correlationMatrix, cmap = 'coolwarm', vmin = -1, vmax = 1, aspect = 'auto', origin = 'upper')
# 칼러바 추가
cbar = plt.colorbar()
cbar.set_label('Correlation', rotation = 270, labelpad = 20)
# 라벨과 제목 추가
plt.title('Correlation Matrix Heatmap')
plt.xticks(range(len(correlationMatrix)), ['Var1', 'Var2', 'Var3', 'Var4'])
plt.yticks(range(len(correlationMatrix)), ['Var1', 'Var2', 'Var3', 'Var4'])
plt.show()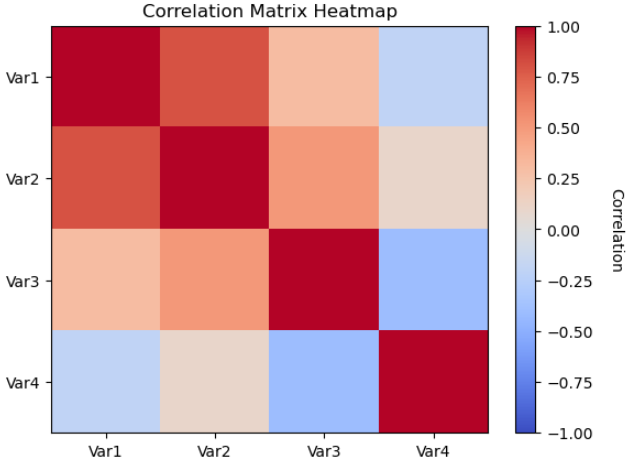
스택 플롯(Stack Plot)
세 가지 제품 범주(전자제품, 의류, 가전제품)가 4분기(1분기~4분기) 동안 총 매출에 어떻게 기여하는지 그래프로 표현해 보겠습니다. 그런 다음 각 범주의 매출을 도표의 레이어로 나타낼 수 있으며, 도표는 시간 경과에 따른 카테고리의 기여도와 추세를 이해하는 데 도움이 됩니다. 이것이 바로 스택 플롯이 하는 일입니다.
누적 영역 플롯이라고도 하는 스택 플롯은 여러 데이터 세트를 서로 쌓인 레이어로 표시하는 데이터 시각화 유형으로, 각 레이어는 데이터의 서로 다른 범주 또는 구성 요소를 나타냅니다.
누적 도표는 개별 구성 요소가 연속 기간 또는 범주형 영역에 걸쳐 전체에 어떻게 기여하는지 시각화하는 데 특히 유용합니다. 원하는 만큼 스택을 plt.stackplot(x,y1,y2) 로 사용하시면 됩니다.
# 스택 플롯을 위한 샘플 데이터
quarters = ['Q1', 'Q2', 'Q3', 'Q4']
electronics = [10000, 12000, 11000, 10500]
clothing = [5000, 6000, 7500, 8000]
homeAppliances = [7000, 7500, 8200, 9000]
# 스택 플롯 생성
plt.figure(figsize = (10, 6)) # 그래프 크기 조정
plt.stackplot(quarters, electronics, clothing, homeAppliances, labels = ['Electronics', 'Clothing', 'Home Appliances'],
colors = ['blue', 'green', 'red'], alpha = 0.7)
# 라벨, 범례, 제목 추가
plt.xlabel('Quarters')
plt.ylabel('Sales ($)')
plt.title('Product Category Sales Over Quarters')
plt.legend(loc = 'upper left')
# 그래프 출력
plt.grid(True)
plt.show()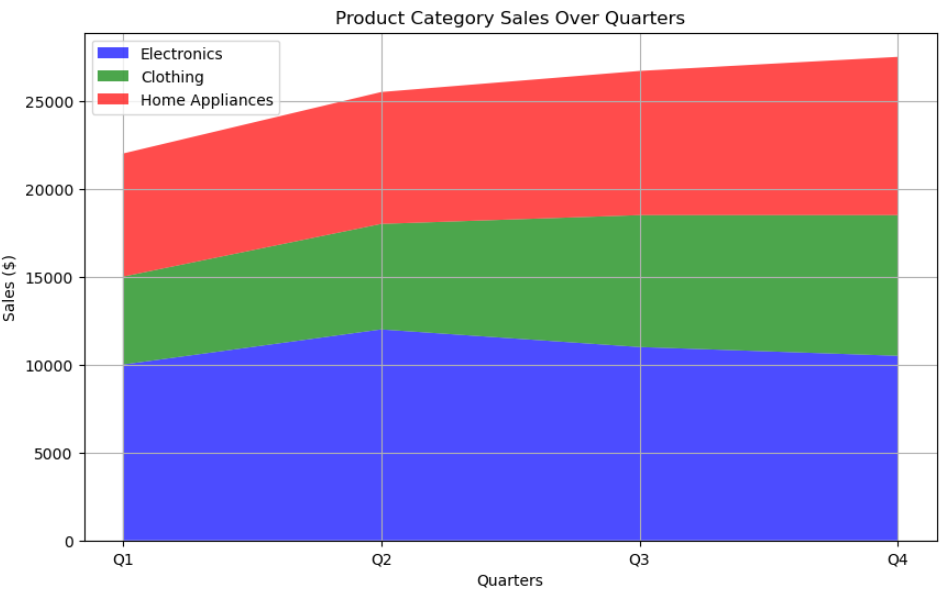
결론
이번 포스팅에서는 Matplotlib 라이브러리를 활용하여 기본 플롯을 만드는 방법과 이를 사용자 정의하는 방법을 다루었고, 중요한 플롯의 특징에 대해 논의했습니다.
Matplotlib을 마스터하는 것은 더 나은 데이터 시각화를 위해 필수적이며, 이번 포스팅에서 설명 드린 것에만 국한되지 않습니다. Matplotlib의 좀 더 고급스러운 사용법에 대해서는 다음 포스팅에서 설명 드리겠습니다.