이번 포스팅에서는 DataFrame 작업 시 자주 사용되는 데이터 유형인 문자열 데이터를 처리하는 작업에 대해 알아보겠습니다( Polars 문자열 처리 방법 ).
문자열 처리는 예측할 수 없는 메모리 크기로 인해 종종 비효율적일 수 있습니다. 이로 인해 CPU가 많은 임의의 메모리 위치에 액세스하게 됩니다.
이 문제를 해결하기 위해 Polars는 Arrow를 백엔드로 활용하여 모든 문자열을 인접한 메모리 블록에 저장합니다. 결과적으로 문자열 탐색은 캐시에 최적화되어 있으며 CPU에 대해 예측 가능합니다.
문자열 처리 함수는 str 네임스페이스에서 사용할 수 있습니다.
문자열 네임스페이스에 접근하기
str 네임스페이스는 문자열 데이터 유형을 가진 열의 .str 특성을 통해 접근할 수 있습니다.
다음 예에서는 Animal이라는 열을 만들고 바이트 수와 문자 수를 기준으로 열에 있는 각 요소의 길이를 계산합니다. ASCII 텍스트로 작업하는 경우 이 두 계산의 결과는 동일하며 lengths를 사용하는 것이 더 빠릅니다.
import polars as pl
tmepData = pl.DataFrame({"animal": ["Crab", "cat and dog", "rab$bit", None]})
outTmepData = tmepData.select(
pl.col("animal").str.len_bytes().alias("byte_count"),
pl.col("animal").str.len_chars().alias("letter_count"),
)
print(outTmepData)
문자열 분석(parsing)
Polars는 문자열 요소를 확인하고 구문 분석하는 다양한 방법을 제공합니다. 먼저, Contains 메소드를 사용하여 주어진 패턴이 하위 문자열 내에 존재하는지 확인할 수 있습니다. 이러한 패턴을 추출하고 다른 방법을 사용하여 대체할 수 있습니다. 다음 예제를 살펴보겠습니다.
패턴의 존재 여부 확인하기
문자열 내에 패턴이 있는지 확인하려면 Contains 메소드를 사용할 수 있습니다. Contains 메소드는 리터럴 매개변수의 값에 따라 일반 하위 문자열 또는 정규식 패턴을 허용합니다.
패턴이 문자열의 시작이나 끝 부분에 위치한 간단한 하위 문자열인 경우, start_with 및 end_with 함수를 대신 사용할 수 있습니다.
outTempData = tmepData.select(
pl.col("animal"),
pl.col("animal").str.contains("cat|bit").alias("regex"),
pl.col("animal").str.contains("rab$", literal=True).alias("literal"),
pl.col("animal").str.starts_with("rab").alias("starts_with"),
pl.col("animal").str.ends_with("dog").alias("ends_with"),
)
print(outTempData)
패턴 추출
extract 메소드를 사용하면 지정된 문자열에서 패턴을 추출할 수 있습니다. 이 방법은 패턴에서 괄호()로 정의되는 하나 이상의 캡처 그룹을 포함하는 정규식 패턴을 사용합니다. 그룹 인덱스는 출력할 캡처 그룹을 나타냅니다.
tempData = pl.DataFrame(
{
"a": [
"http://vote.com/ballon_dor?candidate=messi&ref=polars",
"http://vote.com/ballon_dor?candidat=jorginho&ref=polars",
"http://vote.com/ballon_dor?candidate=ronaldo&ref=polars",
]
}
)
outTempData = tempData.select(
pl.col("a").str.extract(r"candidate=(\w+)", group_index = 1),
)
print(tempData)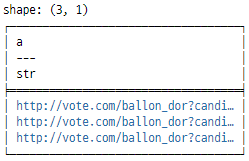
문자열 내에서 패턴의 모든 발생을 추출하려면 extract_all 메소드를 사용할 수 있습니다. 아래 예에서는 하나 이상의 숫자와 일치하는 정규식 패턴(\d+)을 사용하여 문자열에서 모든 숫자를 추출합니다.
extract_all 메소드의 결과 출력은 문자열 내에서 일치하는 패턴의 모든 인스턴스를 포함하는 리스트입니다.
tempData = pl.DataFrame({"foo": ["123 bla 45 asd", "xyz 678 910t"]})
outTempData = tempData.select(
pl.col("foo").str.extract_all(r"(\d+)").alias("extracted_nrs"),
)
print(outTempData)
패턴 교체
지금까지 패턴 일치 및 추출을 위한 두 가지 방법에 대해 알아보았습니다. 이제 문자열 내에서 패턴을 바꾸는 방법을 살펴보겠습니다. extract 및 extract_all과 유사하게 Polars는 이러한 목적으로 replace 및 replace_all 메소드를 제공합니다. 아래 예에서는 단어 끝(\b)에서 일치하는 abc 중 하나를 ABC로 바꾸고 a를 모두 -로 바꿉니다.
tempData = pl.DataFrame({"id": [1, 2], "text": ["123abc", "abc456"]})
outTempData = tempData.with_columns(
pl.col("text").str.replace(r"abc\b", "ABC"),
pl.col("text").str.replace_all("a", "-", literal = True).alias("text_replace_all"),
)
print(outTempData)
결론
이상으로 Polars 라이브러리를 활용하여 문자열을 처리하는 기본적인 방법에 대해서 알아보았습니다. 위에서 다룬 예제 외에도 Polars는 서식 지정, 제거, 분할 등과 같은 작업을 위한 다양한 기타 문자열 조작 방법을 제공합니다.
이러한 추가 방법을 살펴보려면 Polars 문자열 처리방법(상세)를 클릭하시면 됩니다.
감사합니다.