이번 포스팅에서는 Python의 시각화 라이브러리인 Seaborn 라이브러리에서 제공하는 Plot 종류 에 대해서 알아 보겠습니다. 데이터 시각화에 있어서 Seaborn은 숨겨진 보석과 같습니다.
탐색적 데이터 분석을 수행할 때, 통상적으로 Matplotlib로 시작하고 Seaborn은 상대적으로 덜 사용합니다.
하지만 seaborn의 모든 잠재력을 안다면, 데이터에서 얼마나 더 많은 것을 탐색할 수 있는지 보고 놀라게 될 것입니다.
Matplotlib과 달리 매력적인 플롯을 만들기 위해 많은 코드 줄을 작성할 필요가 없습니다. Seaborn은 작성하기 쉽고 Pandas와 완벽하게 통합됩니다.
Seaborn 라이브러리에서 제공하는 다양한 Plots 소개
Seaborn에는 많은 플롯이 있으며 이를 모두 기억하는 것은 매우 어렵습니다.
하지만 변수를 기준으로 다음과 같은 섹션으로 크게 분류하면 사용하는 데에 많은 도움이 됩니다.
- Categorical Plots: 범주형 데이터를 시각화하기 위한 플롯입니다.
예: 막대 도표, 개수 도표, 군집 도표, 점 도표, 고양이 도표, 범주형 상자 도표, 범주형 바이올린 도표, 범주형 군집 도표 등 - Univariate Plots: 단일 변수를 시각화하는 플롯입니다.
예: 히스토그램, KDE 도표, 러그 도표, 상자 도표, 거리 도표, 바이올린 도표, 스트립 도표 등 - Bivariate Plots: 두 변수 간의 관계를 시각화하는 플롯입니다.
예: 산점도, 선 도표, 회귀 도표, 조인 도표, 헥스빈 도표 등 - Multivariate Plots: 두 개 이상의 변수를 포함하는 플롯입니다.
예: 쌍 도표, 패싯 그리드, 관계형 도표 등 - Matrix Plots: 데이터 매트릭스 내의 관계를 시각화하기 위한 플롯입니다.
예: 히트맵, 클러스터 맵.
Categorical Plots
Count Plot
Count Plot은 각 범주의 관측치 개수를 표시합니다. 범주형 데이터의 빈도나 분포를 시각화하는 데 적합합니다.
sns.countplot(x, data = dataframe)을 사용하여 Count Plot을 생성합니다.
코드를 보시면 아시겠지만, Matplotlib 라이브러리보다 사용법이 간단합니다. 데이터프레임을 할당해야 하는 data라는 매개변수와 x 및 y 매개변수에 대해 열 이름을 할당하면 됩니다.
Count Plot을 보기 전에 seaborn에서 사용할 수 있는 데이터 세트를 가져 오겠습니다.
import seaborn as sns
import matplotlib.pyplot as plt
# Load the "tips" dataset
tips = sns.load_dataset("tips")
tips.head()
----------------------------------------------------------------
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4 tips 데이터 세트는 레스토랑에서 사람들이 제공하는 tip에 대한 정보입니다.
날짜 카테고리에 대한 Count Plot을 살펴보겠습니다.
# Count Plot
# 한글 깨짐 현상 방지를 위한 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.figure(figsize = (8, 5))
sns.countplot(x = "day", data = tips, palette = "Set3")
plt.title("요일별 팁 건수")
plt.show()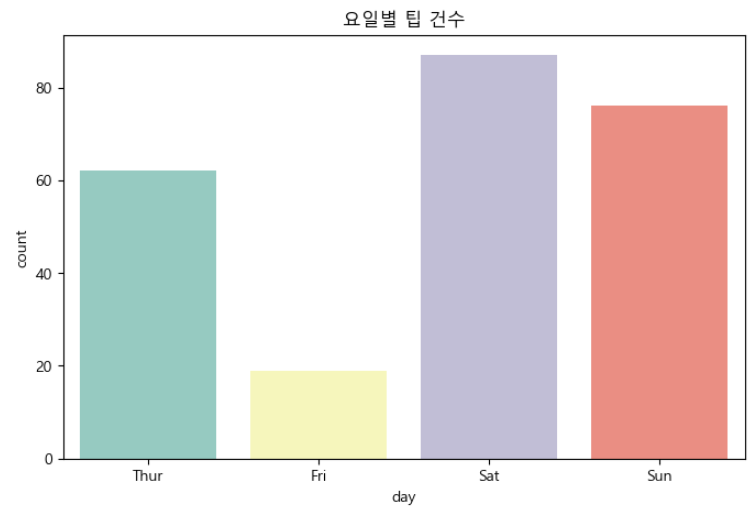
Swarm Plot
Swarm Plot에는 일반적으로 x축에 범주형 변수가 있고 y축에 숫자 변수가 있고, 각 범주를 따라 개별 데이터 포인트를 표시합니다.
이는 범주 내 데이터 포인트의 분포와 밀도를 시각화 합니다.
Swarm Plot의 주요 특징 중 하나는 데이터 포인트 간의 중복 최소화입니다.
즉, 각 데이터 포인트는 동일한 범주의 다른 포인트와 겹치지 않는 방식으로 표시됩니다. 이렇게 하면 데이터의 밀도를 더 쉽게 확인할 수 있습니다.
하지만 더 큰 데이터로는 시각화하기 어렵다는 단점이 있어, 상대적으로 작은 데이터 세트에서 효과적입니다.
sns.swarmplot(x,y,data)를 사용하여 군집 플롯을 만들고 팔레트를 사용하여 색상을 변경합니다.
# Swarm Plot
plt.figure(figsize=(8, 5))
sns.swarmplot(x = "day", y = "total_bill", data = tips, palette = "viridis")
plt.title("요일별 총 청구서 분포")
plt.xlabel("요일")
plt.ylabel("총 청구서 ($)")
plt.show()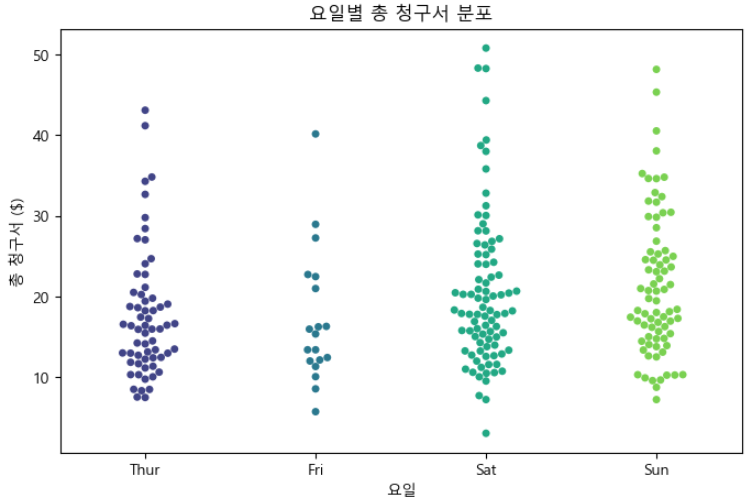
Swarm Plot은 범주 내 이상값이나 특이한 데이터 포인트를 식별하는 데 도움이 됩니다.
스웜 플롯은 데이터 포인트가 집중된 위치와 희박한 위치를 명확하게 표현하기 때문에 데이터 포인트의 밀도를 이해하는 데 유용합니다.
Point Plot
점 도표(Point Plot)는 x축에 범주형 변수가 있고, y축에 숫자형 변수가 있습니다.
선이나 점과 같은 각 범주 내 데이터의 분포에 대한 탐색이 가능합니다.
# 점 도표(Point Plot)
plt.figure(figsize = (8, 5))
sns.pointplot(x = "day", y = "total_bill", data = tips, ci = "sd", palette = "pastel")
plt.title("요일별 평균 총 청구금액")
plt.xlabel("요일")
plt.ylabel("평균 총 청구금액 ($)")
plt.show()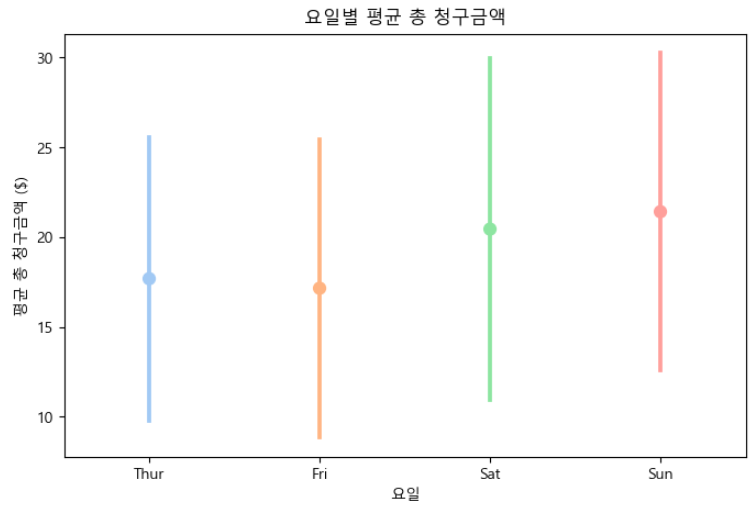
점은 각 범주에 대한 숫자 변수의 평균 또는 중앙값을 나타냅니다(이 예제에서는 평균값을 보여주고 있습니다.). 따라서 이를 활용하면 카테고리별로 평균값이나 중앙값에 차이가 있는지 빠르게 확인할 수 있습니다.
범주형 바이올린 플롯(Categorical Violin Plot)
범주형 변수는 그룹 또는 범주를 결정하고, 숫자 변수는 각 범주 내에서 바이올린 플롯을 생성하는 데 사용됩니다. 특정 지점의 플롯 너비는 해당 값에서의 데이터 포인트의 밀도를 나타내며, 바이올린 플롯의 중앙 부분이 바이올린과 유사해서 바이올린 플롯이라고 불립니다.
바이올린 내부에는 중앙값, 사분위수 및 잠재적 이상값을 포함하는 상자 그림 표현이 있는 경우가 많습니다. 이는 데이터의 중심 경향과 확산에 대한 요약을 제공하여 각 범주 내 수치 변수의 분포에 대한 포괄적인 데이터 탐색을 제공합니다.
# 범주형 바이올린 플롯(Categorical Violin Plot)
plt.figure(figsize = (8, 5))
sns.violinplot(x = "day", y = "total_bill", data = tips, palette = "Set2")
plt.title("요일별 총 청구서 분포")
plt.xlabel("요일")
plt.ylabel("총 청구금액 ($)")
plt.show()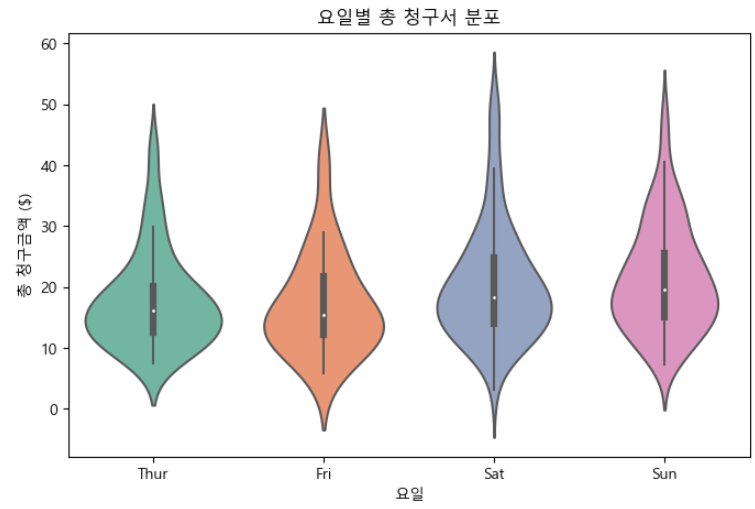
Swarm Plot에서 밀도를 관찰한 것처럼 Box Plot과 Density Plot의 특징을 결합한 것을 알 수 있습니다. 따라서 범주형 바이올린 플롯은 다양한 범주에 걸쳐 수치 데이터의 분포를 비교하는 데 매우 효과적이라고 말할 수 있습니다. 중심 경향과 확산뿐만 아니라 분포의 모양과 왜곡도 확인할 수 있습니다.
Cat Plot
“Categorical Plot”의 약자인 Cat Plot은 Seaborn의 매우 강력한 플로팅 기능입니다. sns.catplot(x,y) 명령에서 kind라는 매개변수 하나만 사용하여 위에서 본 모든 범주형 도표를 만들 수 있습니다.
kind = bar, swarm , box, Violin , count , point 등을 사용할 수 있습니다. 범주형 변수와 수치 변수 간의 관계를 시각화하는 데 적합합니다.
# Catplot에서 violin 분포를 출력하는 예시
plt.figure(figsize = (8, 5))
sns.catplot(x = "day", y = "total_bill", data = tips, kind = "violin")
plt.title("요일별 총 청구서 분포")
plt.xlabel("요일")
plt.ylabel("총 청구금액 ($)")
plt.show()
------------------------------------------------------------------------
# 출력결과는 위와 동일함일변량 플롯(Univariate Plots)
일변량 플롯은 단일 변수를 시각화하고 분석합니다. 분포와 중심 경향의 이해, 이상치 식별, 단일 변수 내의 패턴이나 추세를 확인하는 데 유용합니다.
KDE 플롯(KDE Plot)
KDE(Kernel Density Estimation) 플롯은 연속형 변수의 확률 밀도 함수를 추정하는 데이터 시각화 유형입니다. x축에 연속형 변수가 있고, y축은 곡선 아래의 추정된 확률 밀도 영역을 나타내며, 영역의 합은 1입니다.
# KDE Plot
plt.figure(figsize = (8, 5))
sns.kdeplot(data = tips['total_bill'], fill = True, palette = "muted")
plt.title("총 청구금액의 커널 밀도 추정")
plt.xlabel("총 청구금액 ($)")
plt.ylabel("밀도")
plt.show()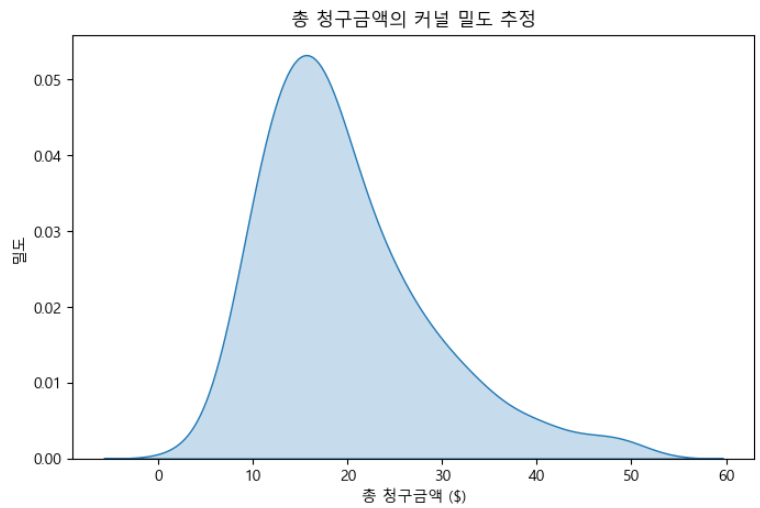
KDE 플롯은 데이터 포인트, 최고 점, 빈도 및 확산에 대한 정보를 제공합니다.
Rug Plot
러그 플롯은 단일 축(일반적으로 x축)을 따라 배치된 수직선(또는 “ticks”)으로 구성됩니다. 각 ticks은 개별 데이터 포인트의 위치를 나타내며 ticks의 근접성은 데이터 포인트의 밀도를 나타냅니다.
# 러그 플롯(Rug Plot)
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize = (8, 5))
sns.rugplot(x = tips['total_bill'], height = 0.5)
plt.title("총 청구금액에 대한 러그 플롯")
plt.xlabel("총 청구금액 ($)")
plt.ylabel("밀도")
plt.show()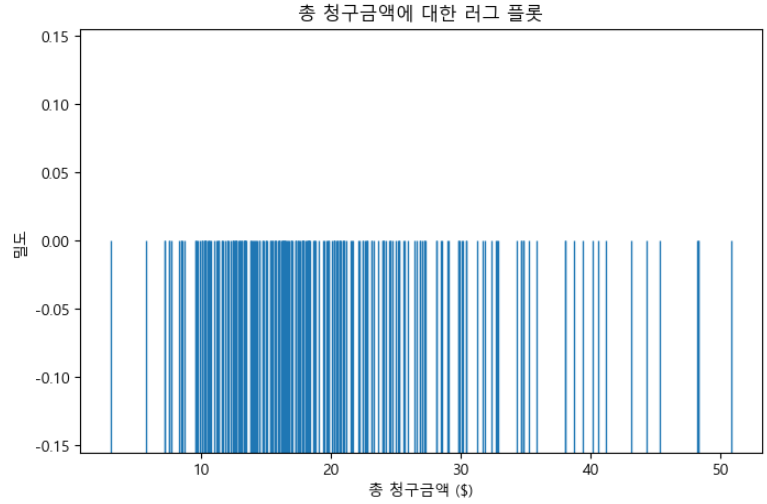
KDE 플롯을 통해서 청구금액의 분포가 10~20 사이에 많이 집중되어 있다는 사실을 알 수 있지만, 러그 플롯을 통해서는 그 집중도가 15~20에 더 가깝다는 사실을 알 수 있습니다.
러그 플롯은 개별 데이터 포인트의 정확한 위치를 확인하려는 경우 특히 유용합니다. 추가 컨텍스트와 세부 정보를 제공하기 위해 히스토그램, KDE 플롯 또는 상자 플롯과 결합하여 사용하는 경우가 많습니다. 이는 이상치나 데이터 밀도가 높은 영역을 강조하는 데 도움이 될 수 있기 때문입니다.
분포 플롯(Dist Plot)
분포 플롯의 약어인 Dist Plot은 히스토그램과 유사하지만 추가적으로 KDE 플롯인 매끄러운 곡선을 포함합니다. 수치형 변수의 범위를 bin(구간) 또는 간격으로 나누고 각 bin 내 데이터 포인트의 빈도 또는 밀도를 표시합니다.
# Dist Plot
plt.figure(figsize = (8, 5))
sns.distplot(tips['total_bill'])
plt.title("총 청구금액에 대한 분포")
plt.xlabel("총 청구금액 ($)")
plt.show()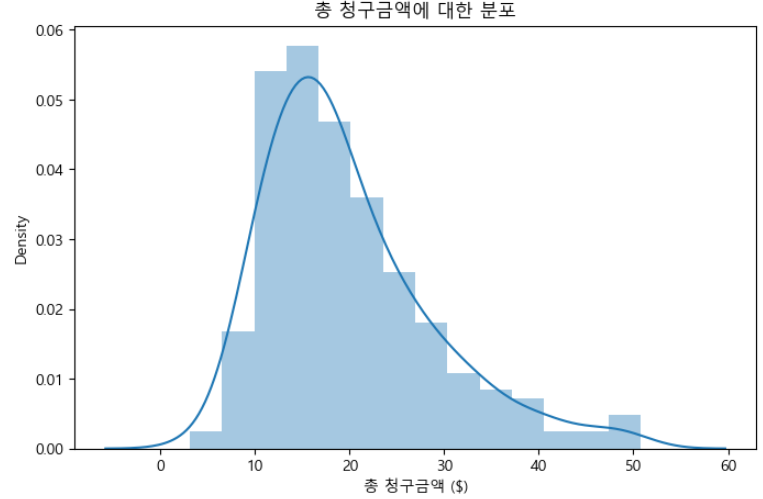
러그 플롯을 X축을 따라 추가하여 개별 데이터 포인트를 작은 수직선으로 표시할 수 있습니다. 이를 통해 개별 데이터 포인트의 밀도와 분포에 대한 통찰력을 얻을 수 있습니다.
# Dist Plot
plt.figure(figsize = (8, 5))
sns.distplot(tips['total_bill'])
sns.rugplot(tips['total_bill'])
plt.title("총 청구금액에 대한 분포")
plt.xlabel("총 청구금액 ($)")
plt.show()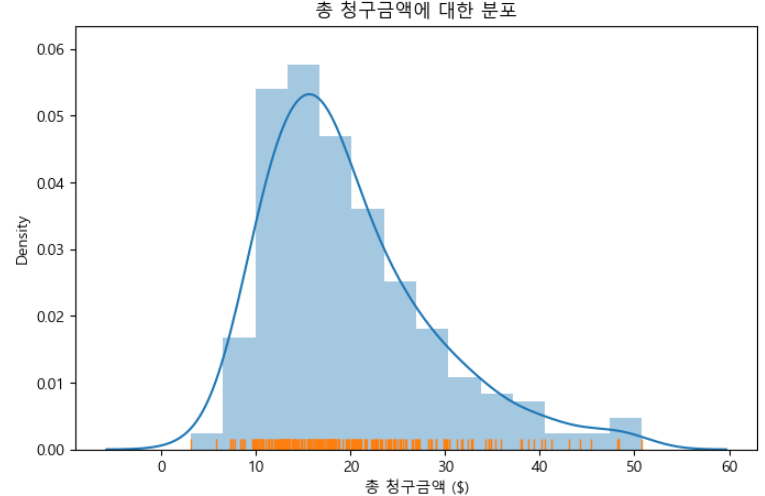
Box Plot & Violin Plot
단변량 분석을 수행하려는 경우 변수를 하나만 전달한다는 점만 다를 뿐 모든 것이 범주형 도표 생성과 동일합니다.
# 단변량 분포를 위한 상자 플롯
plt.figure(figsize = (8, 5))
sns.boxplot(x = tips['total_bill'], palette="coolwarm")
plt.title("총 청구금액 분포")
plt.xlabel("총 청구금액 ($)")
plt.show()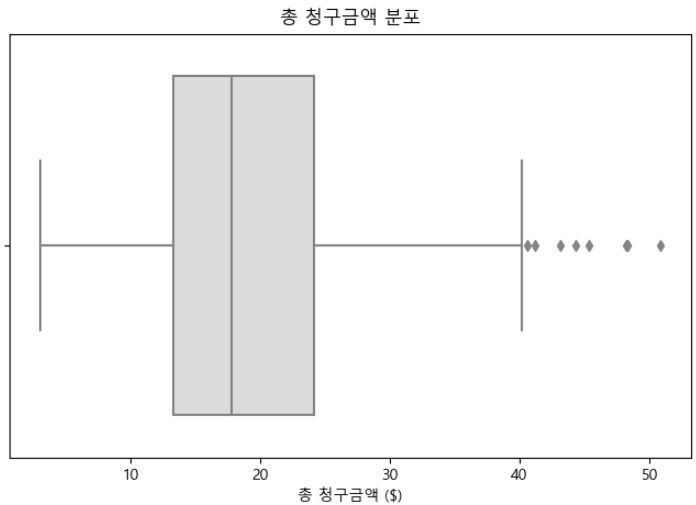
스트립 플롯(Strip Plot)
스트립 플롯은 스웜 플롯과 유사하며 단일 축을 따라 개별 데이터 포인트를 표시합니다. 그러나 데이터 포인트는 스트립 플롯에서 겹칠 것이므로 Swarm Plot은 작은 데이터세트에서 그리고 겹침을 방지하려는 경우에 특히 유용하다고 말할 수 있습니다.
# 스트립 플롯
plt.figure(figsize = (8, 5))
sns.stripplot(x = tips['total_bill'], palette="Set1", jitter = True)
plt.title("총 청구금액 분포")
plt.xlabel("총 청구금액 ($)")
plt.show()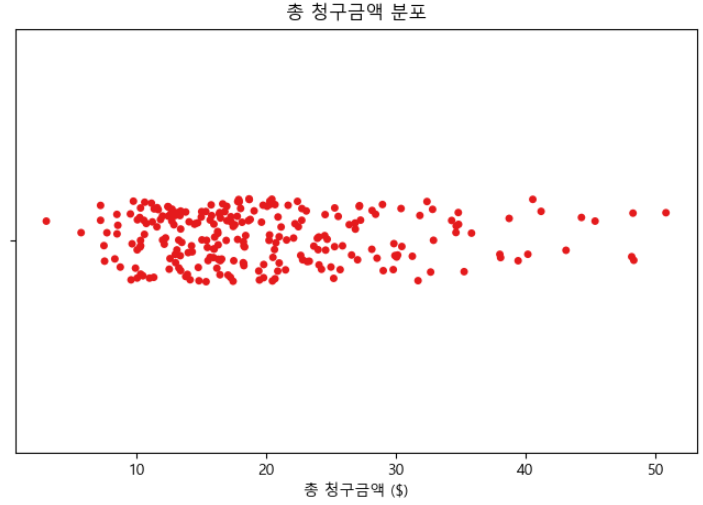
결론
이 종합 가이드에서는 Count Plot, Swarm Plot, Point Plot, Cat Plot, KDE Plot, Rug Plot, Box Plot, Dist Plot, Violin Plot, Strip Plot 등과 같은 다양한 범주형 및 일변량 플롯을 다뤘습니다. seaborn은 다재다능한 도구이며 이를 통해 더 많은 작업을 수행할 수 있습니다.
다음 포스팅에서는 이변량, 다변량 및 매트릭스 플롯을 탐색하여 seaborn 라이브러리에 대한 조금 더 심도 깊은 사용 방법에 대해서 알아 보겠습니다.